



MQTT基础知识
MQTT的报文格式:


前两个control header和packet lenth表示固定报文格式,后两个为剩余数据长度。
variable header:可变长度报头,主要服务于后面的payload
payload:有效数据载荷,就是要发送的数据内容,数据载荷会根据variable header长度的变化而变化。这里面就包含了我们后面会用到的topic和message,一次可发送256M的数据。
控制报文的类型
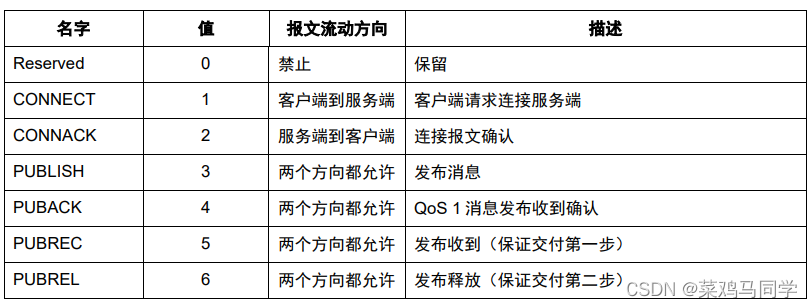
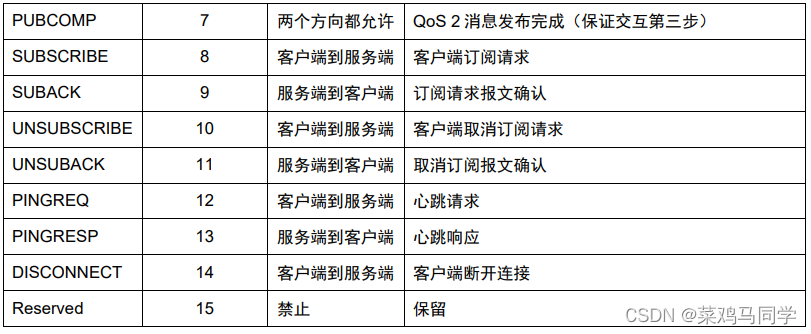
这里简单解释一下上面的参数:
Reserve:这个地方是保留使用的,我们不用管他,也用不到
Connect:客户端开始向服务器发送请求,说 :“我要开始连接你啦”
CONNACK:服务器收到连接请求后发出的回执,说:“收到收到,你连吧”
PUBLISH:连接之后,双方可以发布消息了,注意是双向通讯
PUBACK:客户端和服务器任意一端收到消息之后,都会互相告知对方一声:“我收到你的消息啦”
-----------------------------------------------------------------------------------------------------------------------------
插播一个知识点:QoS >>>表示两人通讯的等级,等级越高,通讯越可靠。
QoS=0时,表示客户端或服务器任意一方发送的消息,接收者最多只收一次,收不到就算了,收不到就摆烂,不太可靠
QoS=1时,表示客户端或服务器任意一方发送的消息,接收者至少能收到一次,接收者会不停接收,直到收到消息为止,比较负责,但存在重复接收的问题
QoS=2时,通讯最复杂,简单来讲,信息不容易丢失和重复。
------------------------------------------------------------------------------------------------------------------------------
后续参数都差不多,都是 “请求+答复” 的模式。。。。。。。。。
以上表里的内容可以参考下面这张图来看,这是MQTT传输数据的方式和过程: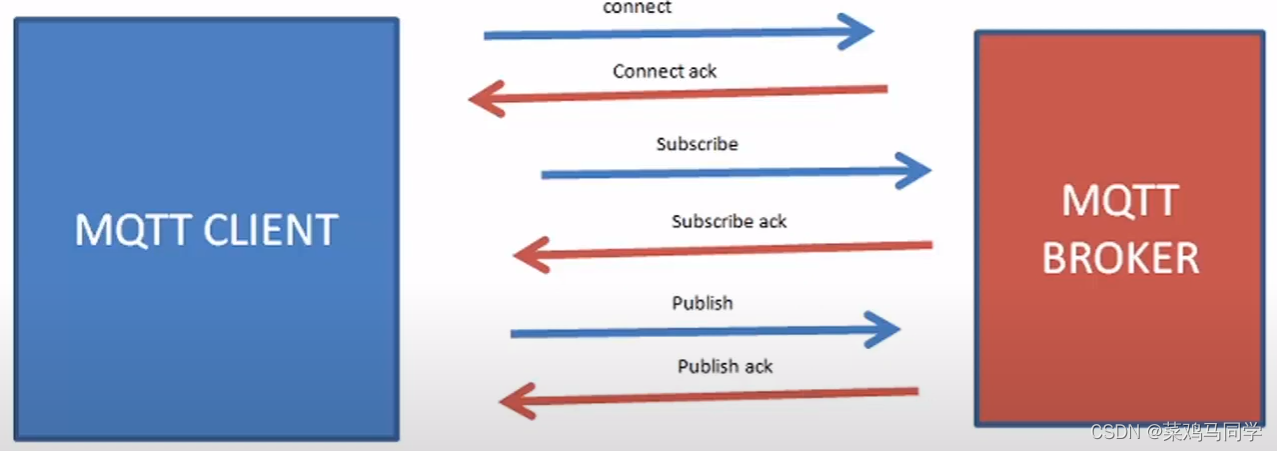
补充一下客户端和服务器的知识: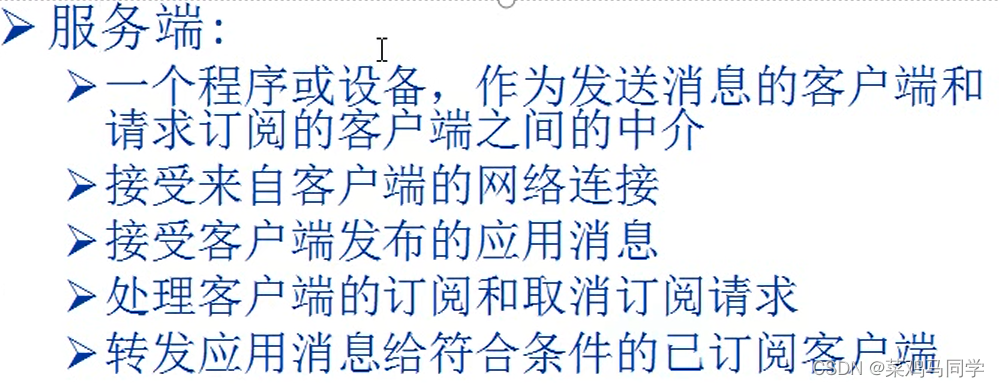

代码部分
detect.py部分插入的代码
import argparse
import os.path
import time
from pathlib import Path
import json
import paho.mqtt.client as mqtt
import MQTT.publish
from MQTT import publish_test, publish
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized
def json_content(fn):
def inner():
result = fn()
print(result)
print("这是装饰器")
return inner
# @json_content
def detect(save_img=False):
source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
save_img = not opt.nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
# Directories
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(opt.device)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
t0 = time.time()
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=1)
###---------------添加代码:按照json输出-------------------------
save_json = True
if save_json:
file_name = save_path.split('/')
json_content_dict = {
"name": file_name[len(file_name) - 1],
"category": (names[int(cls)]),
"bbox": torch.tensor(xyxy).view(1, 4).view(-1).tolist(),
"score": conf.tolist()
}
print(json_content_dict)
publish_test.run(json_content_dict) # 将检测到的坐标信息加载到mqtt的发布模块
# Print time (inference + NMS)
print(f'{s}Done. ({t2 - t1:.3f}s)')
# Stream results
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer.write(im0)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {save_dir}{s}")
# return json_content_dict
print(f'Done. ({time.time() - t0:.3f}s)')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='/home/ma/project/yolov5-5.0_crack/runs/train/exp63/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='/home/ma/project/yolov5-5.0_crack/fire_test/231826574-1-16.mp4', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=448, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
print(opt)
check_requirements(exclude=('pycocotools', 'thop'))
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:
detect()
strip_optimizer(opt.weights)
else:
publish_test.connect_mqtt() # 先启动连接
detect()
publish.py部分的代码,用于项MQTT服务器发布检测框信息
# python 3.6
import json
import random
import time
from paho.mqtt import client as mqtt_client
broker = '123.249.86.54' #tcp://123.249.86.54:1883
port = 1883
topic = "robot"
# generate client ID with pub prefix randomly
client_id = f'python-mqtt-id-{random.randint(0, 1000)}'
def connect_mqtt():
def on_connect(client, userdata, flags, rc): # 连接回调函数,rc=0代表成功,其他为失败
if rc == 0:
print(f"已连接到服务器{broker},rc={rc}")
else:
print(f"连接失败!,rc={rc}")
client = mqtt_client.Client(client_id) # 创建客户端对象
client.on_connect = on_connect # 建立连接回调
client.username_pw_set("building-robot-client", "Cw123456") # 设置服务器连接帐号和密码
client.connect(broker, port) # 连接到指定服务器和端口
client.loop_start() # 启动循环
return client
def publish(client, msg):
msg_count = 0 # 计数器
while msg_count < 1:
# time.sleep(1) # 设置间隔时间
result = client.publish(topic, payload=json.dumps(msg)) # 将消息内容整体转化为json内容,并发送出去
print(msg)
# result: [0, 1]
status = result[0] # 0号元素代表状态信息,若为0表示成功发送,若为1表示发送失败
if status == 0:
print(f"正在将 `{msg}` 发送到 `{topic}主题`...")
print("发送成功!!")
else:
print(f"发送到{topic}失败!!!")
msg_count += 1
def run(msg):
client = connect_mqtt()
client.username_pw_set("building-robot-client", "Cw123456") # 设置服务器连接帐号和密码
client.loop_start()
publish(client, msg)
if __name__ == '__main__':
run("swd")发送后的效果
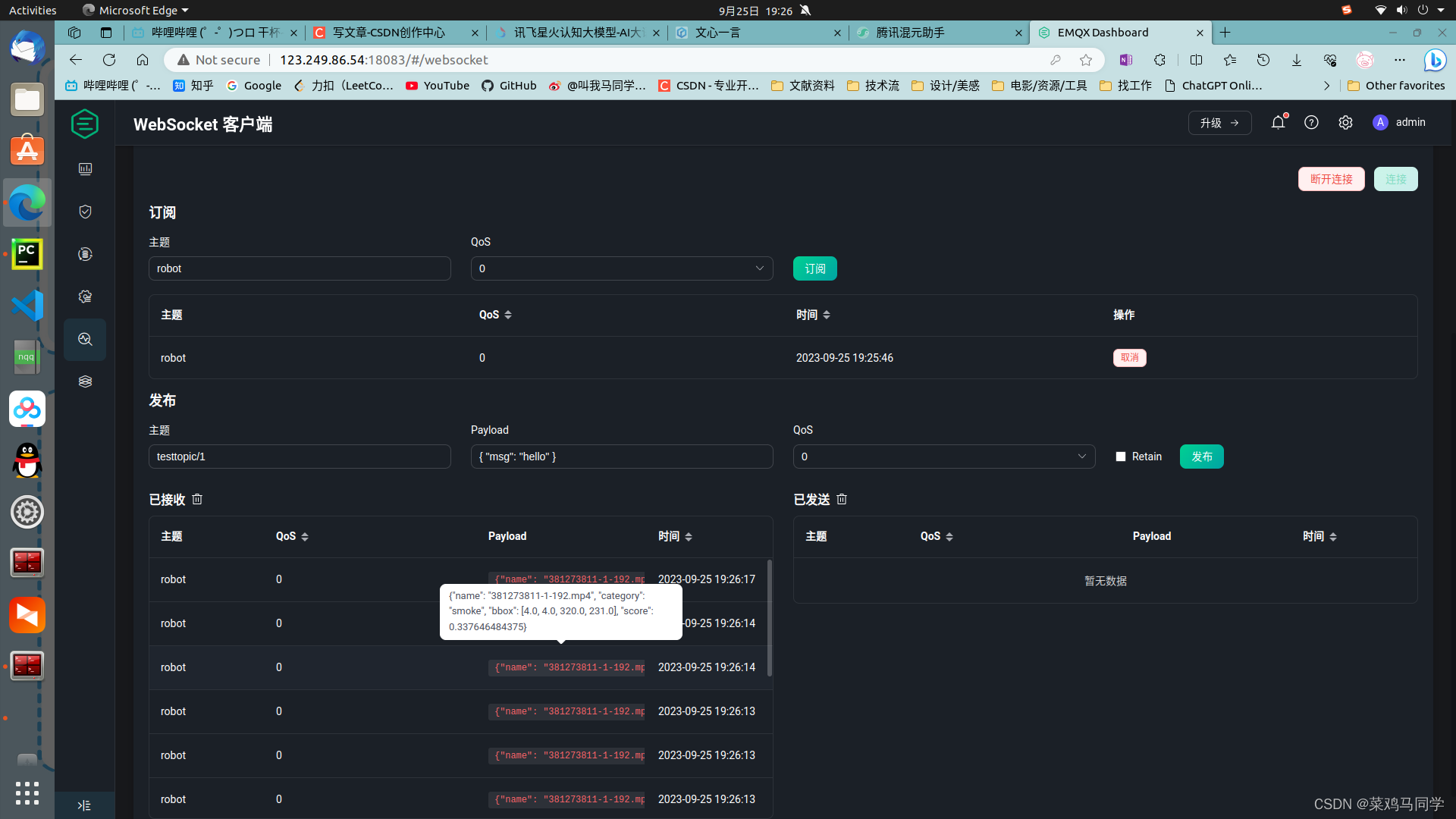

















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









