




深度学习经典网络讲解:走进AlexNet的世界
前言
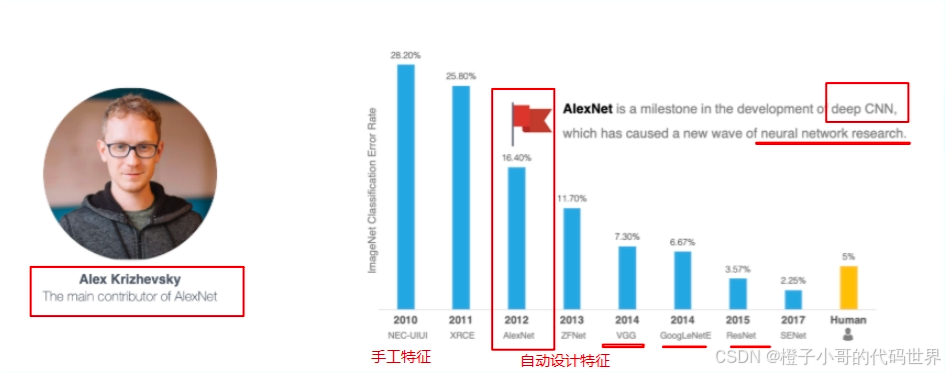
在计算机视觉领域,深度学习的崛起是一个划时代的事件。回顾深度学习在图像识别方面的辉煌历程,就不能不提到AlexNet这座里程碑式的模型。2012年,Alex Krizhevsky等人提出的AlexNet在ImageNet竞赛中横空出世,将图像分类的Top-5错误率从近25%一下子拉低到16%左右,远超传统手工特征与浅层模型的表现。这一突破性进展引发了后续一系列深度卷积神经网络(CNN)的繁荣发展,从而开启了计算机视觉研究的新纪元。
本系列长文将从基础概念到代码实现,对AlexNet进行详尽的剖析。我们会从传统的机器学习与手工特征提取时代谈起,引入卷积、池化、BN(Batch Normalization)和激活函数等深度学习组件,以完整的脉络带领读者理解AlexNet的设计思路和精华所在。文章将分为多部分输出,涵盖:
-
深度学习时代前后的对比:从手工特征到自动特征提取
-
卷积神经网络基本单元:卷积、池化、激活函数、BN
-
AlexNet的网络架构与参数分析
-
数据增强与正则化技巧:ReLU、Dropout、数据增广
-
实战演示:使用PyTorch构建、训练AlexNet并进行图像分类
-
深入剖析输入/输出特征图尺寸变化计算方法
-
性能与时代意义:AlexNet对后续模型的启示
-
引用参考资料与论文来源

AlexNet架构图
历届imagenet比赛冠军:


在本篇第一部分中,我们将重点关注深度学习背景和传统特征提取的局限性,然后初步介绍卷积、池化、BN等概念,为后续深入讨论AlexNet架构奠定基础。
从传统机器学习到深度学习:特征提取的变革
早期视觉研究:手工特征的时代
在深度学习崛起之前,计算机视觉研究主要依赖于手工设计的特征描述子(Feature Descriptor)。研究者必须根据经验和领域知识,为任务定制化地构造特征提取算法。例如,经典的特征包括SIFT(Scale-Invariant Feature Transform)、HOG(Histogram of Oriented Gradients)以及各种纹理、颜色直方图特征。这些特征在特定场景下表现良好,但具有以下局限:
-
特征工程困难重重:设计优良特征需要丰富的领域经验与试错过程。一个特征可能对某类图像有效,对另一类则效果甚微。
-
泛化能力有限:手工特征往往对光照、旋转、尺度变化不够稳健,需要研究者不断改进特征提取方法。
-
性能瓶颈:随着数据规模扩大和任务复杂度增加,单纯堆叠或组合手工特征难以继续提升性能。
深度学习与CNN的兴起
深度卷积神经网络(CNN)的出现改变了这一局面。CNN通过多层卷积和非线性激活,自动从数据中学习多层次特征表示。早期的LeNet(1998年,由Yann LeCun提出)已展示CNN在手写数字识别上的潜力,但直到2012年AlexNet在ImageNet上的惊艳表现,才彻底点燃了学界与工业界对深度学习的热情。
为什么深度学习具备变革性?
-
自动特征学习:模型不再需要手工编写特征提取代码,神经网络的卷积核参数在训练中自动调整,从像素级别开始逐层学习复杂特征表示。
-
可扩展性:随着数据量和计算能力增加,深度网络能显著提升精度与泛化能力。
-
通用性:深度特征往往可迁移到其他任务(Transfer Learning),减少对任务定制特征的依赖。
AlexNet正是深度学习时代的开山之作之一。它在当时将理论研究与大规模计算资源相结合,通过GPU加速训练,在挑战性的数据集(ImageNet)上取得突破,验证了深度学习的潜力。
卷积、池化、激活函数、BN:CNN的基本组件
在全面介绍AlexNet之前,我们需要首先理解CNN中的关键组件和概念。这些基础知识是理解AlexNet架构的前提。
卷积(Convolution):自动提取特征的关键
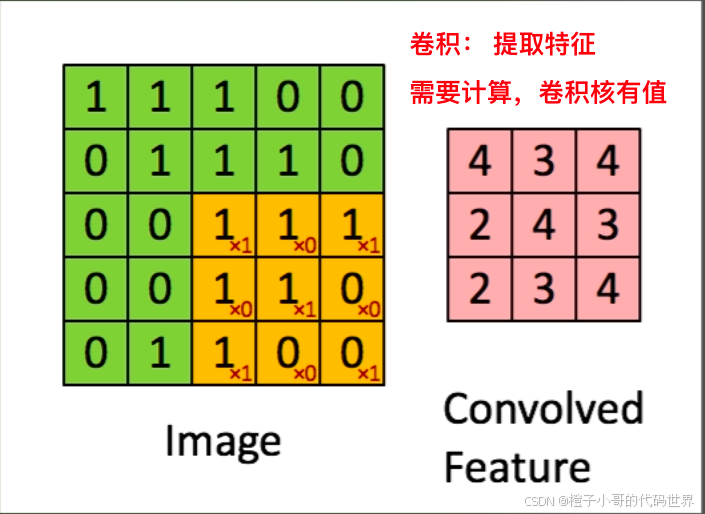
卷积层是CNN的核心模块,用于从输入图像中提取局部特征。一个卷积操作的本质是用可学习的卷积核(滤波器)在输入特征图上进行元素相乘求和,从而产生输出特征图。
-
卷积核(Kernel):如一个
3x3大小的卷积核,对应9个可训练参数。卷积核在输入图像上滑动,每次计算局部加权和,这个操作提取出某种局部模式特征(如边缘、纹理)。 -
参数共享:卷积核的参数在图像平面上共享,不同位置使用同一组滤波器参数,提高数据效率并减少参数数量。
公式(概念性):
特征图尺寸计算公式
(输入与输出的计算关系)
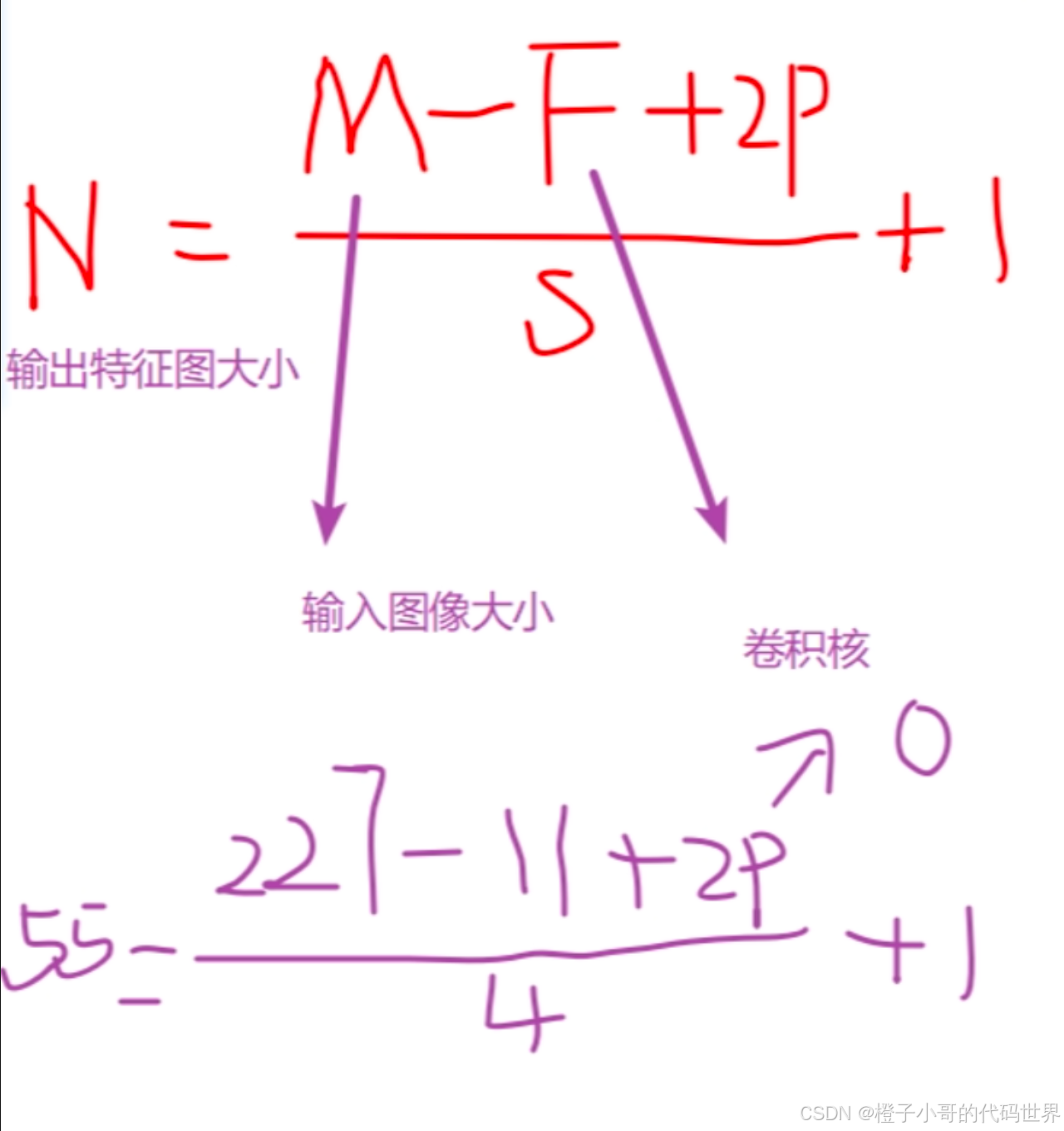
对于输入图像大小为,卷积核大小为
(
与输入通道相同),stride为
S,padding为 P,则输出特征图的空间尺寸 可由下面公式计算:

卷积通过学习卷积核参数,使网络能自动提取有用特征,而不需要人工设计特征描述子。
池化(Pooling):降维与特征增强的利器
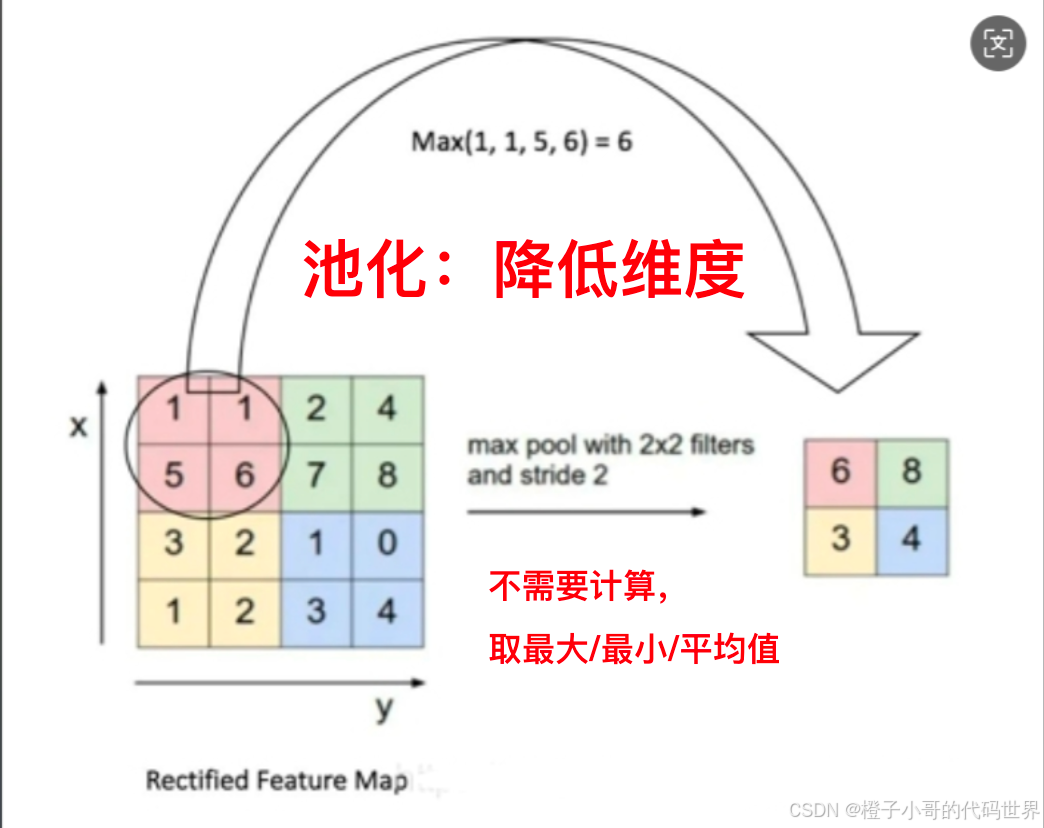
池化层通过在局部窗口内取最大值(Max Pooling)或平均值(Average Pooling)来降低特征图的尺寸,同时保留重要信息。
-
目的:减少特征图大小,降低计算量与模型过拟合倾向;同时增大感受野,使模型关注更大尺度的特征。
-
常用设置:
2x2大小的池化窗口,stride=2。这样特征图宽高缩小一半。
例如,一个 3x3 的max pooling过滤器在 3x3 区域内选取最大值,从而减少数据维度并保留显著特征。
激活函数:引入非线性
激活函数决定了神经网络的非线性表达能力。早期网络使用sigmoid或tanh激活函数,但这些函数在深层网络中会出现梯度消失问题。
AlexNet中引入了ReLU(Rectified Linear Unit)激活函数,大幅加速训练收敛并缓解梯度消失问题。ReLU的定义为:

优点:
-
简单高效:计算代价低。
-
在正区间有较大梯度,保持梯度流动顺畅,便于训练深层模型。
批归一化(Batch Normalization, BN)
虽然BN在AlexNet提出时还未广泛使用(BN于2015年提出),但在后续模型中非常常见,也是读者必须了解的概念。BN通过对mini-batch数据在特征维度上求均值和方差进行归一化,然后通过可学习的缩放和平移参数恢复数据分布。它的好处包括:
-
减少内部协变量偏移(Internal Covariate Shift)
-
加速训练收敛
-
在一定程度上起到正则化作用,提高泛化能力
虽然AlexNet并未使用BN,但理解BN为后来VGG、ResNet等模型打下基础很有价值。我们在后续介绍AlexNet改进时,会提及BN的作用。
AlexNet的重大意义与创新点初探
在正式介绍AlexNet架构前,让我们先了解它在当时所做的创新和贡献:
-
深度与规模:AlexNet比LeNet深、卷积核更多且参数更多(约6000万参数)。在当时,能成功训练如此深的模型已是壮举。
-
ReLU激活函数:引入ReLU代替sigmoid,使得网络训练更容易,收敛速度加快。
-
GPU加速训练:AlexNet利用两块GPU进行数据并行,显著减少训练时间。这是深度学习崛起的硬件基础。
-
大规模数据集(ImageNet)与数据增广:利用ImageNet数据(上百万级别图像)和翻转、裁剪、颜色抖动等数据增广手段,有效缓解过拟合。
这些特性与技巧的结合,促成AlexNet在ImageNet 2012上获得了超越传统方法的成绩。传统手工特征再无还手之力,这一事件震撼了计算机视觉领域,研究者们纷纷转向深度学习路线。
从输入到输出:特征图的尺寸变化
读者可能很好奇,卷积和池化层会如何改变输入特征图的尺寸。AlexNet中的输入图像为 3x227x227(3通道RGB),通过多层卷积和池化,特征图尺寸会不断变化。
让我们简要说明一次卷积或池化如何影响特征图大小:
-
卷积操作(以第1层为例):卷积核
11x11,stride=4,padding=0。 -

-
池化操作:3x3窗口,stride=2会把尺寸变为原来的一半左右。例如从
55x55池化后变为(55-3)/2+1 = 27(四舍五入为整)。 -
实际计算可能略有不同,需根据当时的设计精确计算,但大致是减半的效果。
通过类似的计算可追踪整条网络的输入输出维度变化,后续我们将更详细探讨这一过程。
写代码:从概念到实践
为了让读者在理论理解的同时也掌握实战能力,我们将在后续部分给出利用PyTorch构建AlexNet的完整代码示例,并对代码加上详细注释。代码中我们将体现:
-
如何定义卷积、激活、池化层,以及全连接层
-
如何使用
nn.Sequential简化网络结构定义 -
如何实现
forward函数完成前向传播 -
如何训练AlexNet对特定数据集(例如鲜花分类数据集)进行图像分类的具体步骤,包括数据加载(
ImageFolder、DataLoader)、数据增广和训练循环
通过手把手实现,我们希望让读者在掌握AlexNet原理的同时,能够写出自己的图像分类代码。
在第一部分中,我们主要讲了:
-
深度学习时代的崛起背景:从手工特征向自动特征学习转变
-
CNN关键组件:卷积、池化、激活函数、BN的基本概念(BN在AlexNet中未用,但理解其原理对后续扩展有益)
-
AlexNet的意义与创新点预览
-
特征图尺寸计算的简单示例
在下一部分中,我们将深入拆解AlexNet的完整网络结构,对每一层的参数配置(通道数、卷积核大小、步幅、填充、池化窗口),以及数据增广、Dropout、ReLU等技巧进行详细解释。我们还会初步展示部分代码片段,并补充更多细节,使读者对AlexNet有更全面的认识。
请读者在阅读完此部分后,准备好在下一部分走进AlexNet内部结构的大舞台,深入理解这款改变历史的经典网络。
第一部份完结~
深度学习经典网络讲解:走进AlexNet的世界(第二部分)
回顾与导入
在上一部分中,我们了解了深度学习崛起的时代背景,从手工特征的局限到自动特征提取的巨大变革。我们介绍了卷积、池化、激活函数ReLU与BN(批归一化)的基本概念,并简要说明了AlexNet的历史地位和创新点。
本部分将深入剖析AlexNet网络结构的每一层设计,包括卷积核尺寸、步幅(stride)、填充(padding)设置、通道数变化,以及全连接层的构成与最终分类输出层的选择。我们还会阐述数据增广技巧、正则化方法(如Dropout)的重要性,并通过示例代码帮助读者更好地理解实现细节。
当你读完本部分后,将对AlexNet的内部构造有一个清晰的轮廓。之后我们将在下一部分展示更全面的PyTorch代码示例,以及训练该模型对某些数据集(如鲜花分类数据集)进行分类的完整流程,帮助你将理论落地实践。
深入AlexNet的内部结构
AlexNet与LeNet在设计理念相似,都采用“卷积层 + 池化层 + 全连接层”的经典CNN结构,但AlexNet更加深且宽,并引入多项关键改进。这套网络在ImageNet上达到了前所未有的性能。
AlexNet的输入要求

在AlexNet的经典实现中,输入图像大小为 3x227x227,其中3为RGB三个通道,227x227为宽高。为什么是227而非224、256等尺寸?AlexNet的原论文中,输入为 224x224 或 227x227 都曾出现过,不同实现略有差异。本质上,AlexNet需要相对较大的输入尺寸来保留更多信息,方便更深的卷积核提取丰富特征。
无论是227还是224,对于理解结构本身影响不大。后来很多模型(如VGG)采用224x224作为标准输入尺寸。
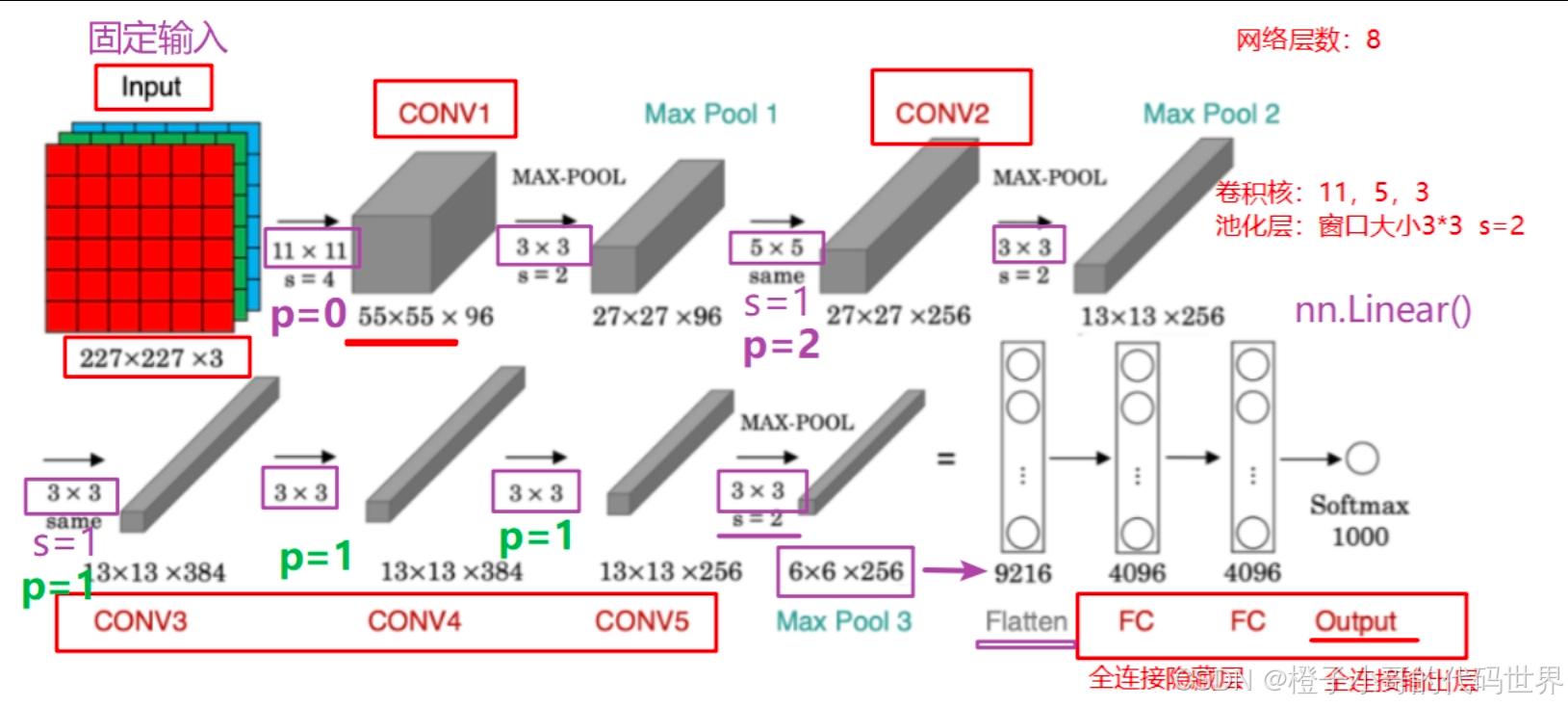
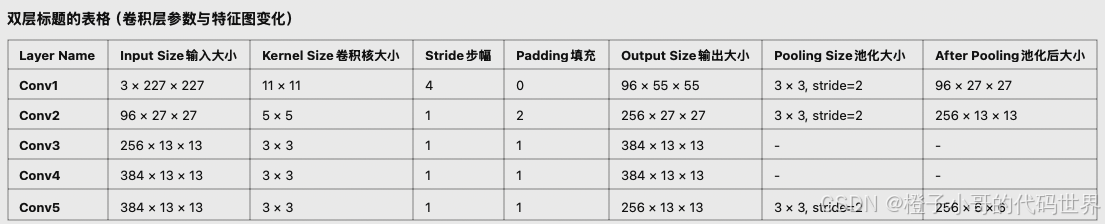
卷积层参数与特征图变化


AlexNet有5个卷积层,采用不同大小的卷积核和步幅设置。下面我们一一拆解。

-
Conv1层:
-
输入:
3x227x227 -
卷积核大小:
11x11 -
卷积核个数(输出通道数):96
-
步幅(stride):4
-
填充(padding):0

-
-
Conv2层:
-
输入:
96x27x27 -
卷积核大小:
5x5 -
输出通道数:256
-
步幅:1
-
填充:2 (通过padding=2,使卷积后输出能维持输入的大小)

-
-
Conv3层:
-
输入:
256x13x13 -
卷积核大小:
3x3 -
输出通道数:384
-
步幅:1
-
填充:1

-
-
Conv4层:
-
输入:
384x13x13 -
卷积核大小:
3x3 -
输出通道数:384
-
步幅:1
-
填充:1

-
-
Conv5层:
-
输入:
384x13x13 -
卷积核大小:
3x3 -
输出通道数:256
-
步幅:1
-
填充:1

-
-
在卷积层之间,加入激活函数ReLU,对输出进行非线性处理。某些实现中也在前几个卷积层后加了LRN(Local Response Normalization,AlexNet原论文中使用过的一种归一化策略),但后来BN出现后LRN较少使用。在此我们聚焦于现代常用的版本:ReLU在每个卷积层后激活,最大池化层在特定层后减小特征图维度。
全连接层与分类输出
经过5个卷积层和3次池化层后,我们得到 256x6x6 的特征图,需要将其展平(flatten)为向量,用于连接至全连接层。
-
展平后向量大小:
256 * 6 * 6 = 9216 -
因此第一层全连接层输入为9216个神经元。
AlexNet的全连接层结构:

在实践中,如果是针对不同数据集(如只有5类鲜花),将最终输出层的神经元数改为5即可。
ReLU与Dropout:训练与正则化技巧
ReLU我们已介绍过,其主要作用是加快训练收敛并降低梯度消失风险。相对于sigmoid激活函数,ReLU简单高效。
Dropout是一种正则化手段:在训练过程中,以一定概率p(如0.5)随机将某些神经元输出置零,从而防止模型过度记忆训练数据(过拟合)。经过Dropout的网络在测试时关闭Dropout(p=0),使用全部神经元进行推理。
数据增广(Data Augmentation)
AlexNet还有一个非常重要的技巧:数据增广。通过随机裁剪、水平翻转、颜色抖动等手段,在训练集中生成更多变的样本。这样即使原始数据有限,也可提升模型对噪声和变形的鲁棒性。
例如:
-
随机裁剪:从原图中随机裁一个224x224区域(如果用224尺寸的版本),使模型在训练中看不到固定中心区域,提升泛化能力。
-
随机水平翻转:对图像进行左右对称翻转,扩充样本多样性。
-
颜色抖动:随机调整亮度、对比度、色相等,使模型不依赖固定的颜色分布。
这些增广方法相当于给模型提供了“更多”训练数据。
模型参数量与GPU加速
AlexNet总参数约6000多万,训练如此庞大的模型需要大量计算资源。在2012年,AlexNet首次大规模采用GPU进行加速训练,将训练时间从数周降至数天。这是AlexNet成功的重要因素。
过去的浅层模型、手工特征方法很难在如此海量数据和庞大模型上高效训练。GPU并行计算的引入为深度学习快速崛起铺平了道路。
AlexNet的特征学习与可视化
一个有趣的问题是,AlexNet的卷积核到底学到什么特征?研究者在训练好AlexNet后可将第一层卷积核可视化,发现它们学到了类似边缘、条纹、颜色对比等基础特征。越往深层走,特征越复杂,从简单的边缘渐进到纹理、形状,再到高层语义模式。
这证明了自动特征提取的神奇之处:无需人为设计特征,网络自行从数据中捕捉有用的模式。这也是AlexNet后被大量关注和仿效的原因之一。
实战:代码结构设计与实现步骤
在实践中使用PyTorch实现AlexNet,我们通常会:

-
定义网络类:继承
nn.Module,在__init__中定义所有层(卷积、池化、线性层),在forward中定义数据前向传播。 -

-
初始化参数(如有需要)、选择优化器(SGD、Adam等)。
-
数据加载:使用
torchvision.datasets.ImageFolder和DataLoader加载数据集,对训练集进行数据增广。 -
训练循环:多轮(epochs)的循环,对于每个batch数据计算前向输出、损失,然后反向传播更新参数。
-
验证集评估:每轮训练后在验证集上评估模型性能,看是否提升并防止过拟合。
-
保存模型:训练完成后保存模型权重,以备后用。
代码示例(结构大纲)
下面为构建AlexNet的一个结构大纲示例,详细注释将在最终部分给出更完整的实例。
#这段代码定义了一个AlexNet类,并根据论文结构搭建层。features模块负责卷积、激活、池化操作;
#classifier模块是全连接层和Dropout。forward函数中先通过features提取特征,
#再flatten后通过#classifier得到输出。
import torch
from torch import nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
# 定义卷积部分
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
# 全连接层部分
self.classifier = nn.Sequential(
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
def forward(self, x):
# 卷积提取特征
x = self.features(x)
# 展平
x = x.view(x.size(0), -1)
# 全连接分类
x = self.classifier(x)
return x这段代码定义了一个AlexNet类,并根据论文结构搭建层。features模块负责卷积、激活、池化操作;classifier模块是全连接层和Dropout。forward函数中先通过features提取特征,再flatten后通过classifier得到输出。
读者可能会问:为什么使用
inplace=True的ReLU?inplace=True表示在原张量上做ReLU,不创建新张量,节省显存。一般小改动,不影响逻辑。
解读各层输出维度及检查
构建完模型后,我们可使用torchsummary或直接输入一张224x224或227x227的随机图像通过网络,来检查每层输出的大小是否符合预期。
示例(伪代码):
from torchsummary import summary
model = AlexNet(num_classes=1000)
summary(model, (3,227,227))summary将打印每层输出大小和参数数目,对照我们计算的理论值判断是否一致。
输出:
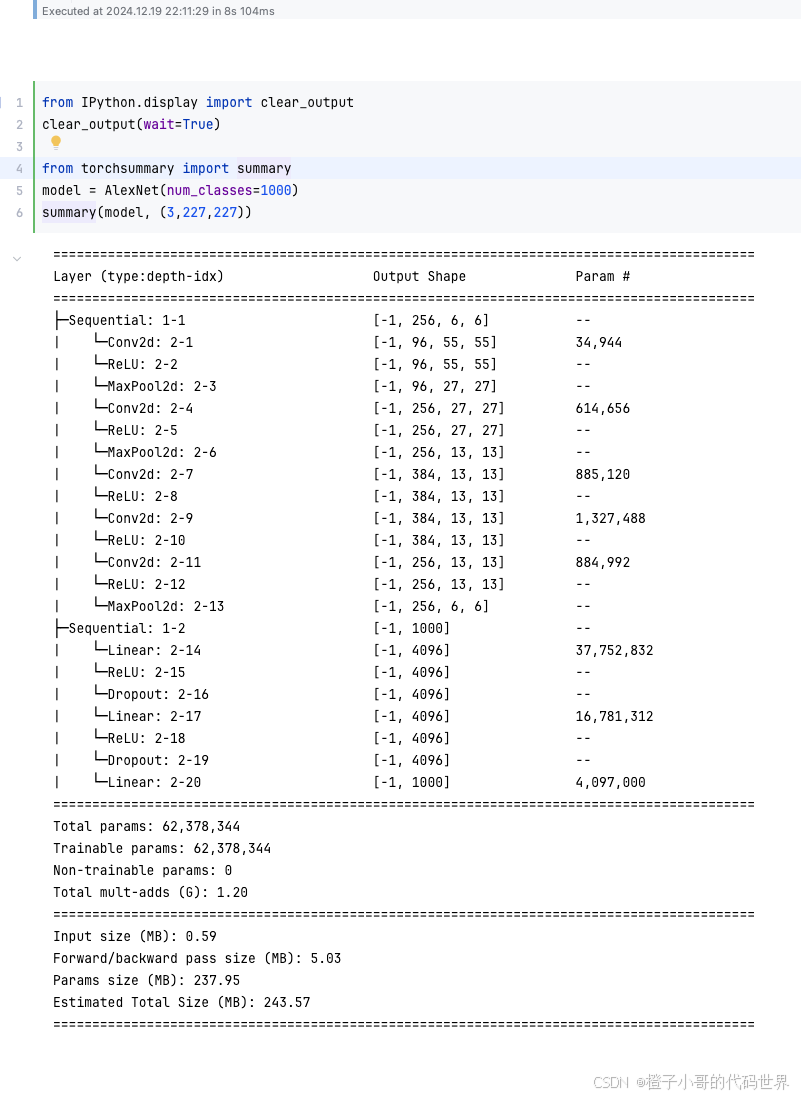
可以看到打印的模型结构和我们AlexNet 论文结构是一样的~
与后续模型的关系
AlexNet之后,研究者们提出了更多网络结构,如ZFNet(2013)、VGG(2014)、GoogLeNet(2014)、ResNet(2015)等,它们在AlexNet的基础上继续改进。例如:
-
VGG使用更多、更小的卷积核(3x3)堆叠,强调深度的力量。
-
GoogLeNet引入Inception模块,进一步提高参数利用效率。
-
ResNet用残差模块解决梯度消失,训练更深层网络成为可能。
这些后续模型都离不开AlexNet奠定的基础:使用ReLU、数据增广、大数据训练、深层CNN架构,使深度学习在CV领域一发不可收拾。
你需要掌握的关键点
本部分的要点包括:
-
AlexNet的基本架构:5个卷积层、3次最大池化、3个全连接层(带Dropout)。
-
参数设置:首层用11x11卷积核,stride=4减小计算量,后层采用5x5、3x3的卷积核,注重提取不同层次特征。
-
ReLU与Dropout:ReLU提高训练速度和稳定性,Dropout作为正则化减少过拟合。
-
数据增广:利用数据增广手段扩大有效数据规模,提高泛化能力。
-
GPU加速:AlexNet大幅利用GPU并行计算,推动深度学习在工业界的落地。
-
特征图尺寸计算:掌握输入/输出特征图大小计算公式,为设计新网络或调试时使用。
掌握了以上知识,读者已能对AlexNet的设计理念与实现要点有扎实理解。
展望与下篇预告
本部分介绍了AlexNet网络的细节与创新要点。下一部分(第三部分)中,我们将重点展示更多代码实践,包括:
-
如何使用PyTorch加载训练数据(如鲜花分类数据集),对图像进行增广处理(transforms)。
-
如何定义训练循环,选择损失函数与优化器,并在CPU/GPU环境中训练AlexNet。
-
如何评估模型性能(准确率),并逐渐提高模型效果。
我们还将进一步讨论BN与LRN区别、AlexNet的训练难点和经验教训,以及如何将AlexNet迁移到自定义数据集上实现实际图像分类任务,帮助读者从构思到落地实践,掌握模型训练的全流程。
下一部分将开始更深入的代码实现与训练实战环节。
第二部分完结~
深度学习经典网络讲解:走进AlexNet的世界(第三部分)
回顾与导入
在前两部分中,我们从深度学习的崛起背景讲起,介绍了CNN的基本组件(卷积、池化、激活函数、BN)、AlexNet的网络结构与创新点,并对各层参数和特征图尺寸变化进行了分析。
本部分将聚焦于实际的代码实现与训练过程。我们将详细展示如何使用PyTorch搭建AlexNet模型、加载数据集、进行数据增广与预处理、定义训练循环和评价指标,以及如何在CPU或GPU上加速训练。
我们将以鲜花分类数据集为例,让读者从理论知识过渡到实际操作。
在完成本部分学习后,读者应当能够编写完整的图像分类代码:
• 使用torchvision.datasets.ImageFolder与DataLoader加载数据
• 利用transforms对图像进行Resize、Crop、Flip、Normalize等预处理
• 实例化AlexNet模型(可根据需求修改输出层大小)
• 设置损失函数与优化器(如CrossEntropyLoss + Adam)
• 运行训练循环并在验证集上评估准确率
数据加载与增广:实践细节
数据集选择与结构
在先前的介绍中提到了鲜花分类数据集,它包含5类花卉(如daisy, dandelion, roses, sunflowers, tulips)。数据组织如下:
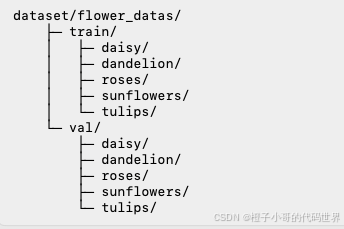
train中是训练集图像分为5个文件夹(每个文件夹为一类),val中是验证集相同结构。这种结构非常适合ImageFolder类,它将子文件夹名映射为类别标签。
我们需要对图像进行预处理以适应AlexNet输入尺寸(如227x227),并使用数据增广提高泛化能力。
使用transforms进行数据增广
例如,在训练集中进行以下变换:
• Resize((227,227)):将图像统一到227x227大小(AlexNet要求较大输入维度)。
• RandomHorizontalFlip():有50%概率水平翻转图像。
• RandomRotation(15):随机旋转±15度。
• ToTensor():将图像转为张量并归一化到[0,1]。
• Normalize(mean, std):对图像按特定均值和标准差进行标准化(如果有预训练模型,通常使用ImageNet的mean/std;如无可自行计算)。
验证集通常只需Resize和ToTensor以及Normalize,不需要随机数据增广,以便评估时稳定性和可重复性。
代码示例(数据加载与transform)
import torch
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
# 指定训练集和验证集的文件路径
# 这些路径需要包含按照类别分成子文件夹的图像数据
train_dir = '../01.图像分类/dataset/flower_datas/train' # 训练集路径
val_dir = '../01.图像分类/dataset/flower_datas/val' # 验证集路径
# 定义训练集的图像预处理(包含数据增广)
# transforms.Compose 用于将一系列预处理操作组合起来
train_transform = transforms.Compose([
transforms.Resize((227, 227)), # 将图像调整为固定大小 227x227
transforms.RandomHorizontalFlip(p=0.5), # 以 50% 概率随机水平翻转图像
transforms.RandomRotation(degrees=15), # 随机旋转图像,旋转角度范围 [-15, 15]
transforms.ToTensor(), # 将图像转换为张量格式,并将像素值归一化到 [0, 1]
transforms.Normalize([0.485, 0.456, 0.406], # 对图像进行归一化,减去均值,除以标准差
[0.229, 0.224, 0.225]) # 这些均值和标准差是基于 ImageNet 数据集计算的
])
# 定义验证集的图像预处理(不包含数据增广)
val_transform = transforms.Compose([
transforms.Resize((227, 227)), # 将图像调整为固定大小 227x227
transforms.ToTensor(), # 将图像转换为张量格式,并将像素值归一化到 [0, 1]
transforms.Normalize([0.485, 0.456, 0.406], # 对图像进行归一化,减去均值,除以标准差
[0.229, 0.224, 0.225])
])
# 使用 ImageFolder 加载数据集
# ImageFolder 假定数据集的目录结构为每个类别一个子文件夹
train_dataset = datasets.ImageFolder(root=train_dir, transform=train_transform) # 加载训练集
val_dataset = datasets.ImageFolder(root=val_dir, transform=val_transform) # 加载验证集
# 定义 DataLoader,用于批量加载数据
# DataLoader 会在训练时迭代数据集,并自动将数据分成小批量
batch_size = 32 # 每个批次包含 32 张图像
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
# train_loader:
# - batch_size: 每批加载的图像数量
# - shuffle=True: 打乱数据集以增强训练的随机性
# - num_workers=4: 使用 4 个进程加速数据加载
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# val_loader:
# - shuffle=False: 验证集不需要打乱顺序
# 打印类别与索引的映射关系
# ImageFolder 会自动根据子文件夹名称生成类别与索引的对应关系
print("Class-to-Index mapping:", train_dataset.class_to_idx)
# 输出示例:
# Class-to-Index mapping: {'daisy': 0, 'dandelion': 1, 'rose': 2, 'sunflower': 3, 'tulip': 4}
通过以上代码,我们成功加载了训练集和验证集,并进行了适度的数据增广和预处理。
输出:

模型实例化与修改输出类别数
我们之前定义的AlexNet默认输出1000类,为ImageNet而设。如果我们的鲜花数据集只有5类(目前数据集只有5类别),可以在构造AlexNet时传递num_classes=5参数。
import torch
import torch.nn as nn
# 定义 AlexNet 类,继承自 nn.Module
class AlexNet(torch.nn.Module):
def __init__(self, num_classes=1000): # AlexNet使用的图片默认类别数为 1000,也就是1000个分类数,可通过传参覆盖
super(AlexNet, self).__init__() # 调用父类 nn.Module 的构造函数
# 定义特征提取部分(卷积层 + 激活函数 + 池化层)
self.features = nn.Sequential(
# 输入通道为 3(RGB 图像),输出通道为 96,卷积核大小 11x11,步长 4,无填充
nn.Conv2d(3, 96, 11, 4, 0),
nn.ReLU(inplace=True), # 激活函数,使用 ReLU,提高模型的非线性表达能力
nn.MaxPool2d(3, 2), # 最大池化层,池化核大小 3x3,步长为 2
# 第二个卷积层:输入 96 通道,输出 256 通道,卷积核大小 5x5,步长 1,填充 2
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2), # 最大池化层
# 第三个卷积层:输入 256 通道,输出 384 通道,卷积核大小 3x3,步长 1,填充 1
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(inplace=True),
# 第四个卷积层:输入 384 通道,输出 384 通道,卷积核大小 3x3,步长 1,填充 1
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(inplace=True),
# 第五个卷积层:输入 384 通道,输出 256 通道,卷积核大小 3x3,步长 1,填充 1
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2) # 最大池化层
)
# 定义分类部分(全连接层 + 激活函数 + Dropout)
self.classifier = nn.Sequential(
nn.Linear(256 * 6 * 6, 4096), # 输入特征 256*6*6,输出特征 4096
nn.ReLU(inplace=True), # 激活函数
nn.Dropout(p=0.5), # Dropout 防止过拟合,丢弃 50% 的神经元
nn.Linear(4096, 4096), # 全连接层,输入特征 4096,输出特征 4096
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes) # 最后一层,输出特征数为分类类别数
)
# 定义前向传播的过程
# 于批量大小为 32 的 RGB 图像,分辨率为 227x227
# 输入 x 的形状为: (32, 3, 227, 227):
def forward(self, x):
# self.features 输出形状:(32, 256, 6, 6)
x = self.features(x) # 通过特征提取部分(卷积层 + 池化层)
# 将卷积特征图展平为一维向量,便于输入全连接层。
# (batch_size, channels * height * width) = (32, 256 * 6 * 6) = (32, 9216)
x = x.view(x.size(0), -1) # 将特征图展平为一维向量(批次大小 x 所有特征)
# 全连接层处理后,输出形状变化为:(32, 4096) → (32, 4096) → (32, num_classes)
x = self.classifier(x) # 通过分类部分(全连接层 + Dropout)
# 其中 num_classes 是分类数,这里为 5。最终形状为:(32, 5)
return x
# 初始化模型,指定类别数为 5,是因为我们这次只做5分类的数据训练与预测(可覆盖默认值)
model = AlexNet(num_classes=5)
定义损失函数与优化器
图像分类的损失函数常用交叉熵(CrossEntropyLoss),优化器可用Adam或SGD。Adam收敛较快,对初学者友好。
import torch.nn as nn
import torch.optim as optim
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)如果有GPU可用(如CUDA),可将模型和数据迁移到GPU上加速训练,苹果Mac的MPS同理:
定义训练与验证循环
训练循环基本流程:
1. 将模型设为训练模式:model.train()
2. 遍历train_loader的每个batch:
• 将图像与标签移动到device(GPU/CPU)
• 前向传播计算输出和loss
• 清零梯度 optimizer.zero_grad()
• loss.backward()反向传播计算梯度
• optimizer.step()更新参数
验证流程:
1. 模型设为评估模式:model.eval()
2. 禁用梯度计算:torch.no_grad()
3. 遍历val_loader,计算预测正确数和总数,求准确率。
代码示例(训练函数)
def evaluate(model, data_loader, device):
model.eval() # 将模型设置为评估模式,关闭 Dropout 和 BatchNorm
correct = 0 # 累计预测正确的样本数
total = 0 # 累计样本总数
with torch.no_grad(): # 禁用梯度计算,加快推理速度并节省内存
for images, labels in data_loader: # 遍历数据加载器中的每个批次
# 将图像和标签移动到指定设备(CPU、GPU 或 MPS)
images, labels = images.to(device), labels.to(device)
outputs = model(images) # 模型前向传播,获取预测结果
_, predicted = torch.max(outputs, 1) # 获取每个样本的预测类别
total += labels.size(0) # 累计样本数量
correct += (predicted == labels).sum().item() # 累计预测正确的样本数
return correct / total # 返回准确率(正确预测数 / 总样本数)
def train_model(model, train_loader, val_loader, loss_fn, optimizer, device, epochs=10):
# 循环指定的训练轮次(epochs)
for epoch in range(epochs):
model.train() # 将模型设置为训练模式,启用 Dropout 和 BatchNorm
running_loss = 0.0 # 累计损失值,用于计算平均损失
total = 0 # 累计训练样本数
correct = 0 # 累计预测正确的样本数
# 遍历训练数据加载器中的每个批次
for i, (images, labels) in enumerate(train_loader):
# 将图像和标签移动到指定设备
# images 的形状为 [32, 3, 227, 227],labels 的形状为 [32] 每个值是该图像的类别标签
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad() # 清空优化器中的梯度缓存
#outputs 的形状为 [32, 5],即每张图像对应 5个类别的预测分数,并未经过 softmax 转化为概率
outputs = model(images) # 模型前向传播,计算输出
#outputs 的形状为 [32, 5],labels 的形状为 [32]
#输出标量 loss(形状为 []),loss_fn会自动将 outputs(logits)通过 softmax 转化为概率分布,再计算与真实标签的交叉熵损失
loss = loss_fn(outputs, labels) # 计算损失值
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
# running_loss 中存储的是当前 epoch 的总损失: 累计当前批次的损失值,以便计算平均损失
running_loss += loss.item()
# 计算当前批次的预测结果
# 获取模型对每张图像的预测类别
# predicted 每张图像预测分数的索引值(类别标签)
_, predicted = torch.max(outputs, 1)
total += labels.size(0) # total 会累加所有样本数量 累计样本总数,用于计算准确率。
correct += (predicted == labels).sum().item() # 累计预测正确的样本数:逐元素比较 predicted 和 labels
# 计算训练集准确率
train_acc = correct / total
# 在验证集上评估模型性能
val_acc = evaluate(model, val_loader, device)
# 打印当前轮次的损失值、训练集准确率和验证集准确率
print(f"Epoch [{epoch+1}/{epochs}] Loss: {running_loss/(i+1):.4f}, Train Acc: {train_acc:.4f}, Val Acc: {val_acc:.4f}")
代码解释:
• evaluate函数不计算梯度,在验证集上衡量准确率。
• train_model函数每轮(epoch)循环训练集,并在轮末使用evaluate查看验证集准确率,观察训练进展。
运行训练:实践建议
• 选择合适epochs:AlexNet在大数据集上训练需要数十到上百个epochs,但在小数据集(如鲜花集)可先尝试10-20个epochs观察过拟合情况。
• 若验证集准确率不提升,可尝试调小学习率、增加数据增广、或使用更强正则化手段。
• 若GPU可用,训练将更快。如GPU不可用,可尝试缩小batch_size或减少epochs做初步测试。
显示训练过程与分析
训练过程中,可将Loss和Accuracy记录下来,使用matplotlib绘图观测变化趋势,判断何时收敛、是否过拟合等。
例如:
train_losses = [] # 用于存储每个 epoch 的训练集平均损失
val_accuracies = [] # 用于存储每个 epoch 的验证集准确率
for epoch in range(10): # 训练 10 个 epoch
# 假设训练循环代码已经完成,略去
train_losses.append(running_loss / (i + 1)) # 将当前 epoch 的训练损失加入列表
val_accuracies.append(val_acc) # 将当前 epoch 的验证集准确率加入列表
# 绘图查看训练损失和验证准确率随 epoch 的变化
import matplotlib.pyplot as plt # 导入 matplotlib 绘图库
plt.plot(range(1, 11), train_losses, label='Train Loss') # 绘制训练损失曲线
plt.plot(range(1, 11), val_accuracies, label='Val Acc') # 绘制验证准确率曲线
plt.legend() # 添加图例,标注曲线名称
plt.show() # 显示绘制的图形
通过这种方式,你可直观了解模型性能随训练进行的变化。
好的,我们为了看图,要在训练过程中收集训练集损失和验证集准确率,并绘制曲线,可以对 刚才的train_model 函数稍作修改,使其返回 train_losses 和 val_accuracies,然后在外部调用时绘图。
# train_losses, val_accuracies 添加两个参数列表,进行return
# 返回每个 epoch 的训练集平均损失
# 返回用于存储每个 epoch 的验证集准确率
def train_model(model, train_loader, val_loader, loss_fn, optimizer, device, epochs=10):
train_losses = [] # 用于存储每个 epoch 的训练集平均损失
val_accuracies = [] # 用于存储每个 epoch 的验证集准确率
# 循环指定的训练轮次(epochs)
for epoch in range(epochs):
model.train() # 将模型设置为训练模式,启用 Dropout 和 BatchNorm
running_loss = 0.0 # 累计损失值,用于计算平均损失
total = 0 # 累计训练样本数
correct = 0 # 累计预测正确的样本数
# 遍历训练数据加载器中的每个批次
for i, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device) # 将图像和标签移动到设备
optimizer.zero_grad() # 清空优化器中的梯度缓存
outputs = model(images) # 模型前向传播,计算输出
loss = loss_fn(outputs, labels) # 计算损失值
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
# 统计损失和准确率
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算每个 epoch 的训练集平均损失和准确率
train_loss = running_loss / (i + 1)
train_acc = correct / total
# 在验证集上评估模型性能
val_acc = evaluate(model, val_loader, device)
# 保存损失和验证准确率
train_losses.append(train_loss)
val_accuracies.append(val_acc)
# 打印当前 epoch 的结果
print(f"Epoch [{epoch+1}/{epochs}] Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, Val Acc: {val_acc:.4f}")
# 返回训练集损失和验证集准确率
return train_losses, val_accuracies
在训练过程中,保存最好的模型是一种常见的做法,这样可以在训练结束后直接加载表现最好的模型,而不需要再手动选取最优的 epoch。以下是如何修改代码以保存最好的模型的详细步骤:
# 如果当前验证准确率高于最佳准确率,保存模型
best_val_acc = 0.0 # 初始化最佳验证准确率
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), save_path) # 保存模型权重
print(f"Model saved with Val Acc: {val_acc:.4f}")最终修改我们的train_model 函数
def train_model(model, train_loader, val_loader, loss_fn, optimizer, device, epochs=10, save_path='saved_models'):
best_val_acc = 0.0 # 初始化最佳验证准确率
train_losses = [] # 用于存储每个 epoch 的训练集平均损失
val_accuracies = [] # 用于存储每个 epoch 的验证集准确率
# 循环指定的训练轮次(epochs)
for epoch in range(epochs):
model.train() # 将模型设置为训练模式,启用 Dropout 和 BatchNorm
running_loss = 0.0 # 累计损失值,用于计算平均损失
total = 0 # 累计训练样本数
correct = 0 # 累计预测正确的样本数
# 遍历训练数据加载器中的每个批次
for i, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device) # 将图像和标签移动到设备
optimizer.zero_grad() # 清空优化器中的梯度缓存
outputs = model(images) # 模型前向传播,计算输出
loss = loss_fn(outputs, labels) # 计算损失值
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
# 统计损失和准确率
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算每个 epoch 的训练集平均损失和准确率
train_loss = running_loss / (i + 1)
train_acc = correct / total
# 在验证集上评估模型性能
val_acc = evaluate(model, val_loader, device)
# 保存损失和验证准确率
train_losses.append(train_loss)
val_accuracies.append(val_acc)
# 如果当前验证准确率高于最佳准确率,保存模型
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), save_path) # 保存模型权重
print(f"Model saved with Val Acc: {val_acc:.4f}")
# 打印当前 epoch 的结果
print(f"Epoch [{epoch+1}/{epochs}] Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, Val Acc: {val_acc:.4f}")
# 返回训练集损失和验证集准确率
return train_losses, val_accuracies
可视化训练模型,并且保存模型
# 调用训练方法并获取损失和准确率
epochs=100
train_losses, val_accuracies = train_model(
model=model, # 传入模型实例
train_loader=train_loader, # 传入训练数据的 DataLoader
val_loader=val_loader, # 传入验证数据的 DataLoader
loss_fn=loss_fn, # 传入损失函数
optimizer=optimizer, # 传入优化器
device=device, # 传入计算设备(CPU/GPU/MPS)
epochs=epochs, # 设置训练轮次为 10
# 设置保存模型路径保存时包含关键信息(模型、学习率、batch size),
# 可以更轻松地复现相应实验
save_path='saved_models/AlexNet_lr0.001_bs32_best.pth'
)
# 绘图查看训练损失和验证准确率随 epoch 的变化
import matplotlib.pyplot as plt # 导入 matplotlib 绘图库
# 绘制训练损失曲线
plt.plot(range(1, epochs+1), train_losses, label='Train Loss')
# 参数说明:
# - range(1, 11): 表示横轴的取值范围,即 1 到 10(对应 10 个 epoch)
# - train_losses: 每个 epoch 的训练损失列表
# - label='Train Loss': 为曲线添加标签,便于图例显示
# 绘制验证准确率曲线
plt.plot(range(1, epochs+1), val_accuracies, label='Val Acc')
# 参数说明:
# - range(1, 11): 横轴范围同上
# - val_accuracies: 每个 epoch 的验证准确率列表
# - label='Val Acc': 为曲线添加标签,便于图例显示
# 设置横轴标签
plt.xlabel('Epoch')
# 参数说明:
# - 'Epoch': 横轴标签内容,表示训练轮次
# 设置纵轴标签
plt.ylabel('Value')
# 参数说明:
# - 'Value': 纵轴标签内容,表示数值(损失或准确率)
# 添加图例
plt.legend()
# 参数说明:
# - 自动根据 `label` 参数生成图例,用于区分曲线
# 添加图标题
plt.title('Train Loss and Validation Accuracy')
# 参数说明:
# - 'Train Loss and Validation Accuracy': 图标题内容,描述图的含义
# 显示绘制的图形
plt.show()
# 参数说明:
# - 显示图形窗口,让曲线图可视化
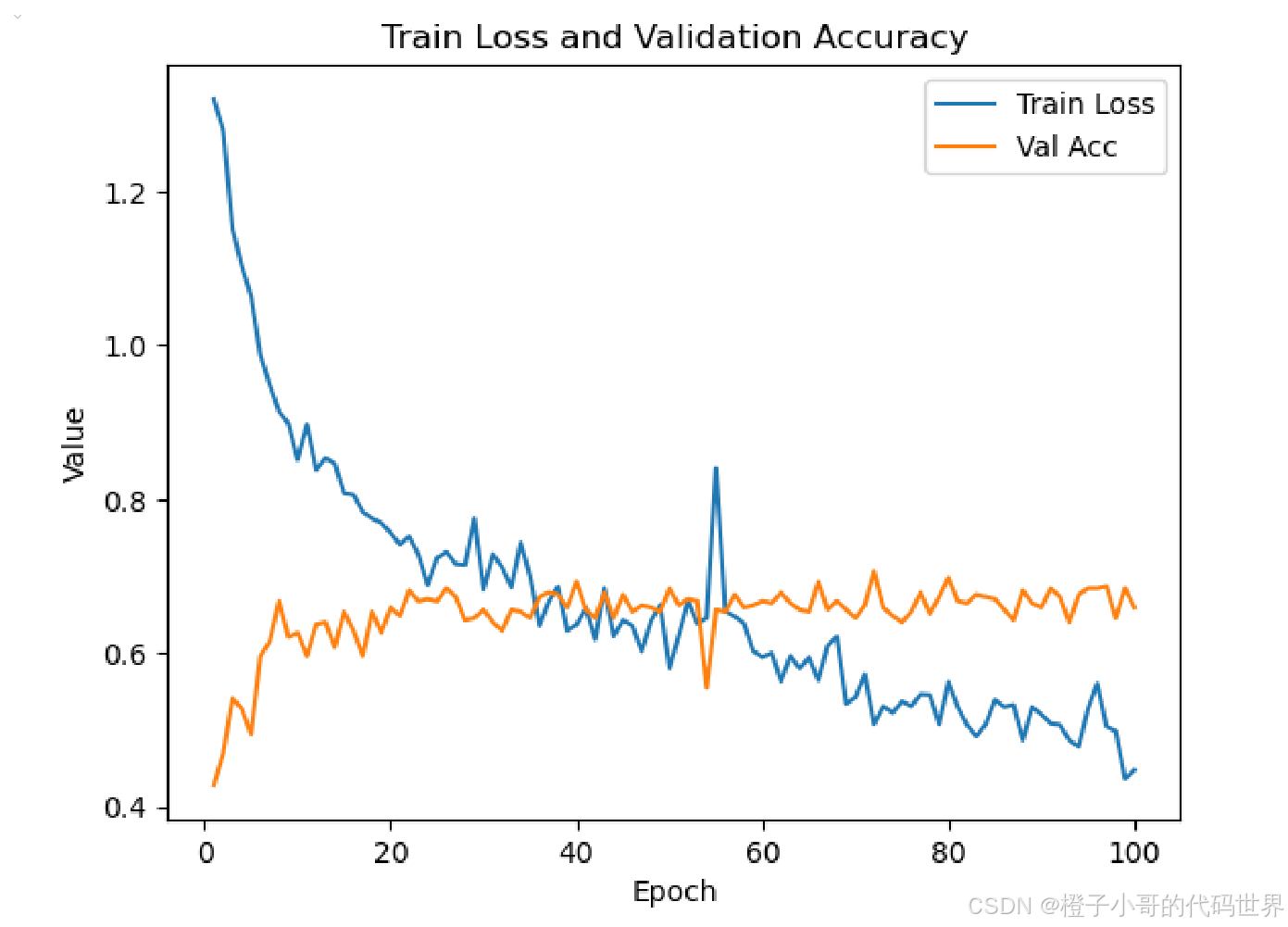
训练过程如下:

我又设置训练轮次epochs = 100,batchsize设置为16对模型进行训练,损失和准确率的变化曲线如下所示:(左图是损失函数的变化曲线,右图是验证集准确率的变化曲线)

超参数与技巧
1. 学习率(lr):1e-3是常用初始值,但你可尝试 5e-4 或 1e-4 若loss不稳定。
2. 学习率调度(Scheduler):在若干epochs后降低lr,使模型更精细地调参。
3. 数据增广:若过拟合明显,可增加更多增广手段,如ColorJitter、RandomResizedCrop。
4. 正则化与Dropout:Dropout已在全连接层使用,若仍过拟合可增加Dropout概率或减少全连接层神经元数量。
5. Batch Normalization:虽然AlexNet原生不包含BN层,但你可以在Conv层后插入BN层,这是后期的改良方法,有助于加速收敛。
从学术到工业:AlexNet的影响
AlexNet的成功不只是一个学术案例,更引发工业界的轰动。许多公司从2012年开始采用深度学习解决图像分类、物体检测、图像分割等问题。AlexNet证明了当深度网络遇上大数据与GPU加速,AI性能可以跃升到前所未有的水平。
后续发展,如VGG、GoogLeNet、ResNet、DenseNet、MobileNet等网络在AlexNet的启示下不断改进,探索更深、更宽、更高效的架构,BN、残差连接、多分支结构、注意力机制等技术百花齐放。
持续学习和扩展
在掌握AlexNet后,建议读者继续研究后续卷积架构及其背后的思想。例如:
• VGG:使用更小卷积核(3x3)和深度加深的策略,让特征表达更细腻。
• GoogLeNet/Inception:多尺度卷积核并行提取特征,提高参数利用率。
• ResNet:使用残差模块,让100层、1000层深的网络训练成为可能。
• Batch Normalization与Layer Normalization:各种归一化技术的应用与效果比较。
• 后期出现的Transformer在CV中的应用:如Vision Transformer(ViT)用自注意力机制替代卷积,加速了新一轮研究热潮。
对比这些模型,你会发现AlexNet正是深度学习CV革命的起点之一,是整个生态的里程碑。
提示与总结
通过三部分的讲解,我们已从深度学习背景、AlexNet的时代意义与结构原理,走到实际代码实现训练过程。读者应该已经对:
• 深度学习特征学习与手工特征区别
• 卷积、池化、激活函数ReLU、Dropout、数据增广等基本概念
• AlexNet的网络结构(5卷积+3全连接)和创新点
• 在PyTorch中实现AlexNet及训练过程
• 使用DataLoader和transforms加载预处理数据,评估模型性能
有了系统的了解与实践能力。
下一部分(第四部分,也将是最后一部分)我们将:
1. 对全文进行全面回顾与总结。
2. 简述如何将AlexNet应用到更多自定义数据集或迁移学习任务中。
3. 给出参考文献和资料链接,以供进一步深入学习。
**第三部分结束。
深度学习经典网络讲解:走进AlexNet的世界(第四部分)
回顾与总结
在前面三部分的内容中,我们系统地探讨了AlexNet这一深度学习经典模型。从深度学习的兴起背景、传统机器学习方法的局限,到卷积神经网络(CNN)的基本组件——卷积、池化、激活函数以及批归一化(Batch Normalization, BN)的概念,我们逐步搭建了理解AlexNet的基础知识框架。随后,我们深入解析了AlexNet的网络结构、参数配置和创新点,最后通过PyTorch的实战演示,指导大家如何构建、训练并评估一个基于AlexNet的图像分类模型。
AlexNet的核心优势与创新点总结如下:
-
深度与规模:AlexNet比前代模型更深,拥有更多的卷积层和全连接层,使得其具备更强的特征提取和表达能力。
-
ReLU激活函数:引入ReLU(Rectified Linear Unit)激活函数,显著加快了训练速度,并缓解了梯度消失问题。
-
GPU加速训练:首次大规模利用GPU进行并行计算,大幅缩短了训练时间,使得训练更大规模的深度网络成为可能。
-
数据增广与正则化:通过数据增广(如翻转、裁剪、颜色抖动)和Dropout等正则化手段,有效防止了模型的过拟合,提升了泛化能力。
-
特征自动学习:证明了深度学习模型能够自动从数据中学习到层次化的特征表示,超越了传统手工设计特征的性能。
AlexNet的成功不仅在于其卓越的性能,更在于它为后续深度学习模型的设计和应用奠定了坚实的基础。许多后续模型,如VGG、GoogLeNet、ResNet等,都是在AlexNet的基础上不断优化和创新,推动了计算机视觉领域的迅猛发展。
迁移学习与自定义数据集
尽管AlexNet在ImageNet数据集上表现卓越,但在实际应用中,我们往往面对不同规模和类别的数据集。迁移学习(Transfer Learning)作为一种有效的方法,可以帮助我们在有限的数据和计算资源下,充分利用预训练模型的知识,加速模型的训练并提升性能。
迁移学习的基本概念
迁移学习的核心思想是将一个在大规模数据集(如ImageNet)上训练好的模型,应用到另一个相关但规模较小的数据集上。通过这种方式,模型可以利用在源任务中学到的特征表示,减少在目标任务中的训练时间,并提升模型的泛化能力。
如何应用AlexNet进行迁移学习
以PyTorch为例,我们可以通过以下步骤,使用预训练的AlexNet模型进行迁移学习:
1. 加载预训练模型
PyTorch的torchvision.models模块提供了预训练的AlexNet模型。通过设置pretrained=True,可以加载在ImageNet上预训练好的权重。
import torch
from torchvision import models
# 加载预训练的AlexNet模型
model = models.alexnet(pretrained=True)2. 冻结部分网络层
为了防止在新任务中预训练模型的权重被更新,我们通常会冻结前几层,仅训练后几层或自定义的分类层。
# 冻结所有卷积层参数
for param in model.features.parameters():
param.requires_grad = False

3. 修改输出层
-
调整输出层是迁移学习中常见的操作之一,因为预训练模型的最后一层通常是为特定任务设计的(例如,ImageNet分类任务有1000个类别)。在新任务中,类别数往往不同,因此需要替换输出层以适应新任务的要求。
-
为什么要修改输出层?
- 预训练模型的特定性:比如在ImageNet上预训练的AlexNet,其最后一层全连接层输出维度是1000,对应ImageNet的1000个类别。
- 迁移到新任务的要求:如果我们用于一个有5个类别的任务,那么最后一层的输出维度应调整为5,以匹配新的目标任务。
- 根据目标任务的类别数,调整模型的最后一层全连接层。例如,如果目标任务有5个类别:
-
import torch.nn as nn # 获取原有分类器的输入特征数 num_ftrs = model.classifier[6].in_features # 替换最后一层全连接层,使其输出维度为目标任务类别数(例如5) model.classifier[6] = nn.Linear(num_ftrs, 5)
4. 定义损失函数与优化器
只优化需要训练的参数,即修改后的分类层。
import torch.optim as optim
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 只优化最后一层的参数
optimizer = optim.Adam(model.classifier[6].parameters(), lr=1e-3)

5.训练模型
按照前面介绍的训练流程,进行模型训练。由于前几层已被冻结,训练速度和效果都会有所提升。
import torch
# 判断设备是否支持 MPS(macOS),否则尝试 CUDA,如果都不支持则使用 CPU
device = torch.device("mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # 将模型移动到选择的设备上(MPS、CUDA 或 CPU)
def train_model(model, train_loader, val_loader, criterion, optimizer, device, epochs=10):
"""
模型训练函数
参数:
- model: 待训练的 PyTorch 模型
- train_loader: 训练数据集的 DataLoader
- val_loader: 验证数据集的 DataLoader
- criterion: 损失函数
- optimizer: 优化器
- device: 计算设备(CPU/GPU/MPS)
- epochs: 训练轮数,默认为 10
返回:
- 无直接返回值,打印每个 epoch 的损失、训练准确率和验证准确率
"""
for epoch in range(epochs):
model.train() # 设置模型为训练模式(启用 Dropout 等特性)
running_loss = 0.0 # 累计损失,用于计算平均损失
correct = 0 # 预测正确的样本数
total = 0 # 总样本数
# 遍历训练数据加载器中的每个批次
for images, labels in train_loader:
# 将图像和标签移动到指定的设备上(MPS/CUDA/CPU)
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad() # 清空梯度缓存
outputs = model(images) # 前向传播,获取模型输出(logits)
loss = criterion(outputs, labels) # 计算损失值
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
running_loss += loss.item() # 累计当前 batch 的损失值
_, predicted = torch.max(outputs, 1) # 获取预测类别索引
total += labels.size(0) # 累计样本数量
correct += (predicted == labels).sum().item() # 累计预测正确的样本数
# 计算训练集的平均准确率
train_acc = correct / total
# 在验证集上评估模型性能
val_acc = evaluate(model, val_loader, device)
# 打印当前 epoch 的损失、训练准确率和验证准确率
print(f"Epoch [{epoch+1}/{epochs}] Loss: {running_loss/len(train_loader):.4f}, Train Acc: {train_acc:.4f}, Val Acc: {val_acc:.4f}")
# 开始训练模型
train_model(model, train_loader, val_loader, criterion, optimizer, device, epochs=10)
迁移学习的优势
-
减少训练时间:预训练模型已经学习到了一些通用特征,减少了从零开始训练的时间。
-
提升性能:尤其在数据较少的情况下,迁移学习能够显著提升模型的准确率和泛化能力。
-
节省计算资源:通过冻结部分层,减少了需要训练的参数数量,节省了计算资源。
注意事项
-
数据集相似性:源任务与目标任务的数据集应具有一定的相似性,以便模型能够有效迁移特征。
-
调整学习率:在迁移学习中,通常需要较小的学习率,避免预训练权重的过度更新。
-
适当冻结层数:根据具体任务,可以选择冻结更多或更少的网络层,以平衡模型的泛化能力和特定任务的适应性。
结语
AlexNet作为深度学习在计算机视觉领域的重要里程碑,不仅展示了深度卷积神经网络在大规模图像分类任务中的强大能力,更开启了深度学习在各类视觉任务中的广泛应用。通过对AlexNet的深入学习与实践,您不仅掌握了深度学习模型的构建与训练技巧,还为进一步探索更先进的网络架构和技术打下了坚实的基础。
在未来的学习与研究中,建议您继续关注以下方向:
-
更深层次的网络架构:如VGG、GoogLeNet、ResNet等,了解不同网络设计的优势与适用场景。
-
优化与正则化技术:探索Batch Normalization、Layer Normalization、Dropout等技术在不同网络中的应用与效果。
-
迁移学习与微调:深入掌握迁移学习的方法,应用预训练模型解决实际问题。
-
新兴技术与趋势:如自注意力机制、Transformer架构在计算机视觉中的应用(如Vision Transformer, ViT)。
通过不断的学习与实践,您将能够驾驭更复杂的深度学习模型,解决更具挑战性的视觉任务,推动个人与团队在人工智能领域的创新与突破。
感谢您阅读本系列文章,祝您在深度学习的道路上不断前行,取得丰硕成果!
互动与交流
如果您喜欢这篇关于AlexNet的深度解析,欢迎点赞、收藏和分享!您的支持是我持续创作的动力。此外,如果您有任何疑问或想法,欢迎在评论区留言交流。让我们一起在深度学习的道路上不断前行,共同探索更多的可能性!
参考文献与资料链接
在深入学习AlexNet及其应用过程中,以下参考资料和文献将对您提供进一步的帮助:
-
原始论文
-
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems, 25.
-
-
深度学习经典书籍
-
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. 在线阅读
-
Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
-
-
PyTorch官方文档
-
在线教程与课程
-
相关博客与资源
-
开源代码与实现
-
相关研究与进展
-
Simonyan, K., & Zisserman, A. (2014). Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv preprint arXiv:1409.1556.
-
He, K., Zhang, X., Ren, S., & Sun, J. (2015). Deep Residual Learning for Image Recognition. arXiv preprint arXiv:1512.03385.
-
-
工具与环境
-
Anaconda:用于管理Python环境和依赖。
-
Jupyter Notebook:交互式编程环境,适合实验和展示代码。
-
参考文献
-
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems, 25.
-
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
-
Simonyan, K., & Zisserman, A. (2014). Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv preprint arXiv:1409.1556.
-
He, K., Zhang, X., Ren, S., & Sun, J. (2015). Deep Residual Learning for Image Recognition. arXiv preprint arXiv:1512.03385.
-
Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
-
PyTorch官方文档. PyTorch documentation — PyTorch 2.5 documentation
-
Deep Learning with PyTorch: A 60 Minute Blitz. Deep Learning with PyTorch: A 60 Minute Blitz — PyTorch Tutorials 2.5.0+cu124 documentation
-
CS231n: Convolutional Neural Networks for Visual Recognition. Stanford University CS231n: Deep Learning for Computer Vision
-
Towards Data Science: Understanding AlexNet. https://towardsdatascience.com/understanding-alexnet-34a4b8b76a38
-
GitHub: PyTorch AlexNet Implementation. vision/torchvision/models/alexnet.py at main · pytorch/vision · GitHub
作者:橙子小哥
日期: 2024年12月19日


















 6651
6651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









