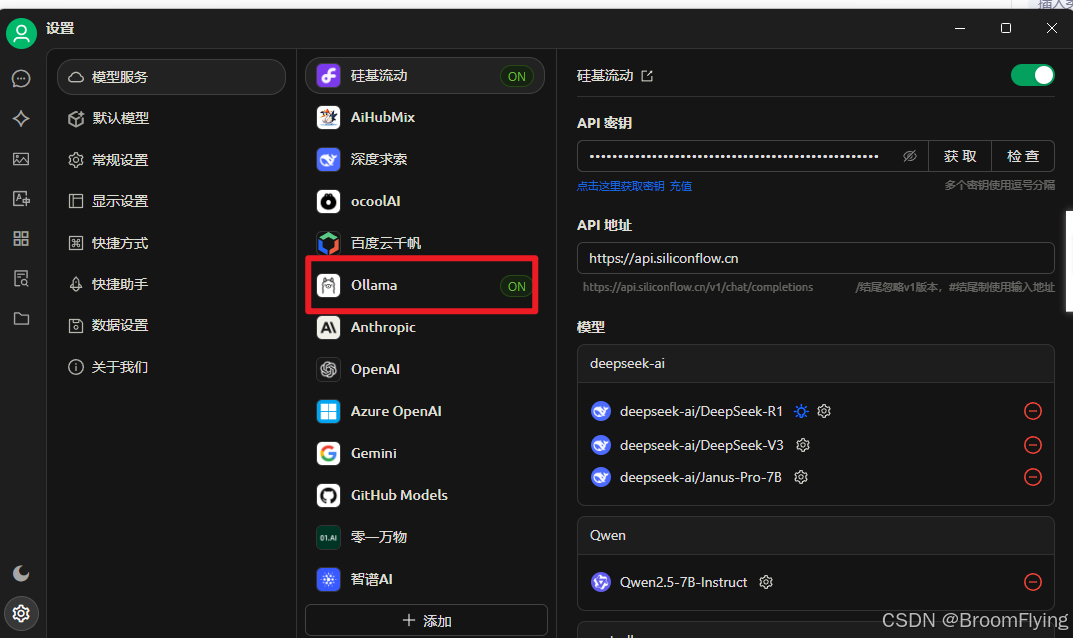
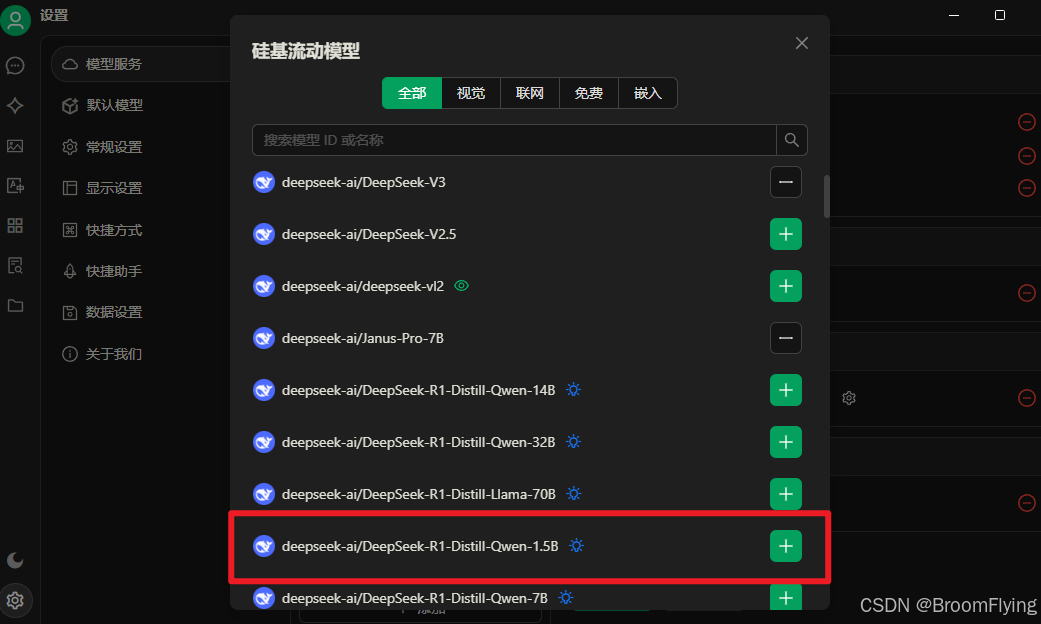
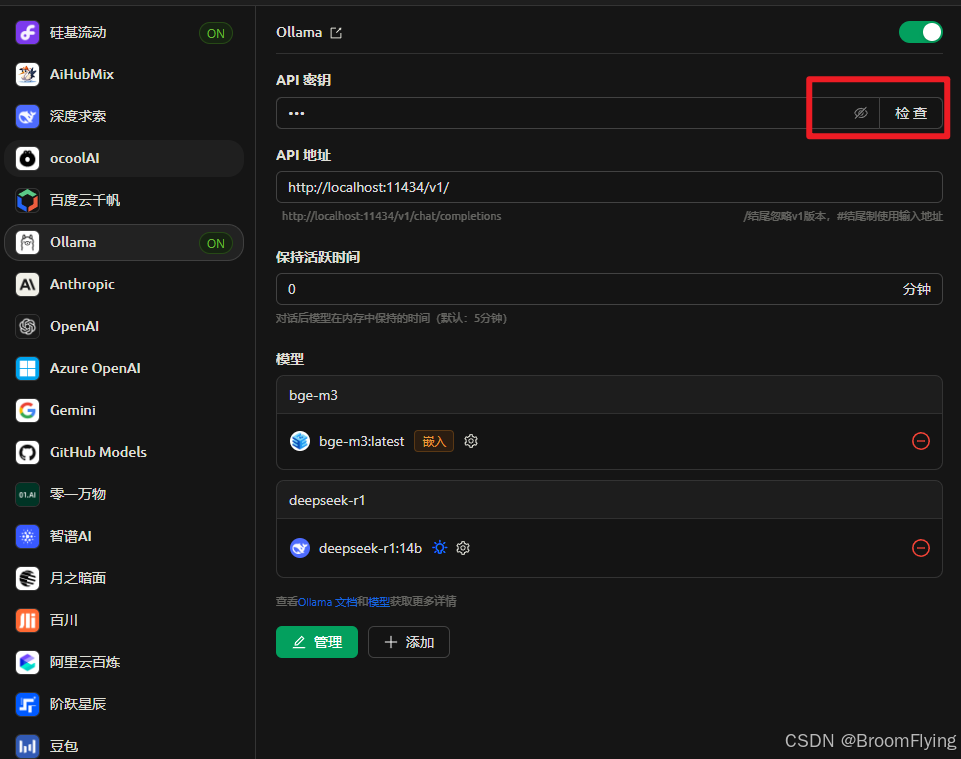
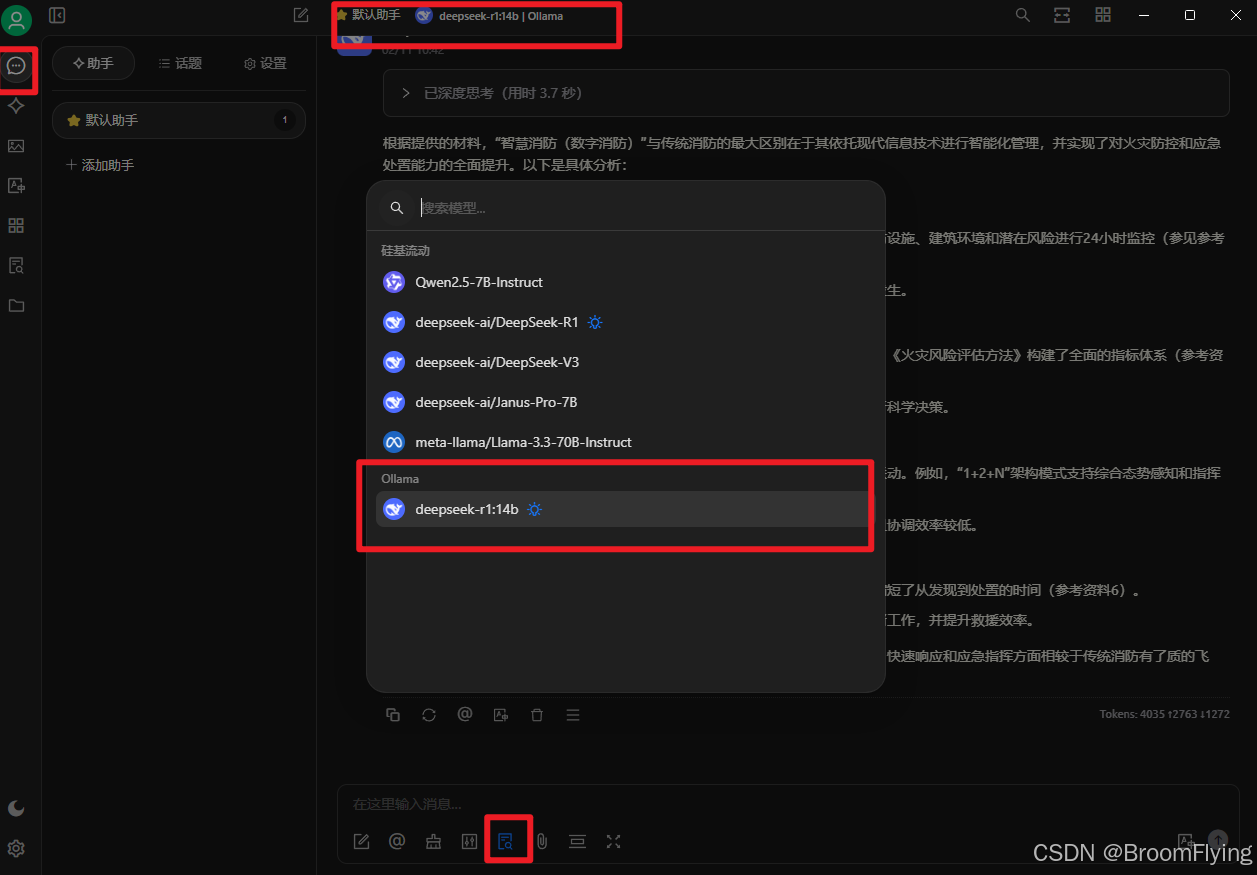
教程链接 https://mp.weixin.qq.com/s/IKoBga2iKfpkdD4Qgy8iLg 步骤 下载ollama cmd运行命令行 ollama run deepseek-r1:1.5b ollama pull bge-m3 下载cherry cherry-ai.com客户端 配置cherry 添加命令行下载好的模型1.5b 检查一下 等待检查成功 进入会话框 选中模型 进行会话 可分为线上和本地知识库倒数第四个标点亮就是本地知识库会话 本地知识库会话前先建立知识库 上传知识库资料文档


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























 4585
4585





