







“互联网”“大数据”“人工智能”你可能在无数篇文献中都看到过这三个词,这三个词的顺序其实是不能颠倒的。互联网、大数据、人工智能的关系:互联网产生了大量数据,使用大数据技术进行存储+计算,并对人工智能提供支撑。
在互联网时代,我们都能上网,而只要上网就会产生大量数据。
你在逛京东的时候,浏览某一个商品,你的这些行为数据会被记录下来,甚至你把鼠标悬浮在某一个分类上,并没有点击,它就会记录数据。
那这么庞大的数据要怎么存,怎么去计算呢?
当然要把这些数据存储下来。但如果你只是单独存储下来,不去对这些数据进行下一步的分析计算,那这些数据就是死数据,不能产生什么价值。所以要让这些数据产生更大的价值,就要对它们进行计算。
所以大数据解决的两个问题——
海量数据的存储
海量数据的计算
同时,大数据也为人工智能提供支撑。因为人工智能里面其实有很多算法,算法可以简单来理解为公式。但这个公式真的准确么?还是得靠大量的数据来进行校验。
大数据,从表面上看,就是说大的数据量,即海量数据。那你想一想,仅仅是数据量大就是大数据吗?多大算大呢,有一个标准么?
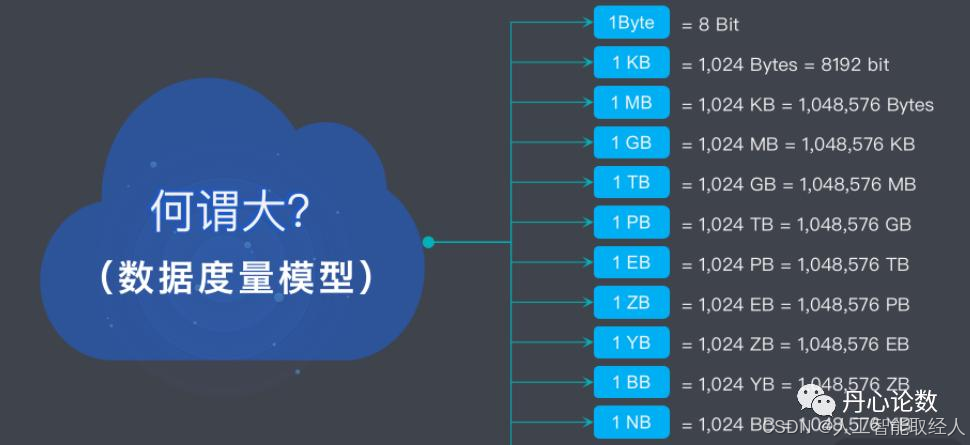
数据,其实是有一个量级的,如上图,看一下数据的度量模型。它的度量单位,MB、GB、TB……可能你在平时的生活中有所接触,现在 1TB、2TB 的移动硬盘也非常普遍了。其实到现在为止,我们全球范围内全人类的整个数据量也就才到 ZB 级。说起 MB,大家可能还有一些体会,到 GB 可能也有一些概念,一个电影它可能就是几十M、几百M,或者几G, 但是你到 PB 可能就没有感觉了。
如何去衡量更大单位的容量大小呢?
1PB 相当于 50% 的全美学术研究图书馆藏书信息内容
5EB 相当于至今全世界人类所讲过的所有话语
1ZB 如同全世界海滩上的沙子数量总和
1YB 相当于 7000 位人类体内的微细胞总和
2020 年,全球数据总量达到了40ZB
那么你肯定想问,到哪个量级才算是“大数据”呢?
有的人说达到 PB 级的数据才算是“大数据”。但实际上,普遍说来,多大的数据量才算大数据并没有一个明确的标准。
很多公司处理的数据量在 TB 级,也就是没达到 PB 级,但是它也要上大数据平台,应用大数据技术。因为传统的技术已经搞不定了,只有用大数据平台来解决业务问题。
大数据(BIG DATA),指无法在一定时间范围内用常规软件工具(比如 MySQL)进行捕捉、管理和处理的数据集合,是需要新处理模式才能处理的海量、高增长率和多样化的信息资产。
那常规软件又指什么呢?
学过计算机的同学可能接触过 MySQL ,其实它就属于常规软件。MySQL 就是一种关系型数据库,而关系型数据库说白了是一种二维表格模型,类似于 Excel 是有明确的行和列的二维表格模型。这样看来, IT 时代的很多软件,当我们数据量大了以后,都不太好存,也不太好算了,甚至根本存不了或算不了了。
像这样的数据场景,我们就称之为大数据;解决这样数据场景的技术,我们就称之为大数据技术。
提到大数据技术就不得不谈Hadoop,hadoop是大数据技术的基石和开山之作,是每个想要从事大数据方面工作的人员必须精通的一门技术。

















 1969
1969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









