







 本文深入解析正则表达式的元字符及功能,包括*、?、+等,并介绍贪婪与非贪婪模式,以及re模块的高级应用如compile、match、search等函数,通过实例演示如何使用sub和subn函数进行高效文本替换。
本文深入解析正则表达式的元字符及功能,包括*、?、+等,并介绍贪婪与非贪婪模式,以及re模块的高级应用如compile、match、search等函数,通过实例演示如何使用sub和subn函数进行高效文本替换。
1. 正则表达式中有一些元字符,如:. * - ? [] + {} $ ^ , 元字符是一些有着特殊含义的字符,倘若无另加的说明(设置)默认为元字符 ,即正则匹配的时候匹配不到元字符,因为这时候它们不是普通字符。
2. 如果要去除元字符的特殊含义,即使其变成普通字符,只需在元字符的前面加上反斜杠‘\'来设置其变成普通的字符。
3.反斜杠除了有使元字符变成普通字符的功能外还有和一些字母搭配变成一些有特殊含义的字符组。
4. 元字符:* *:作用是代表前面的字符匹配0-n次。
5.元字符:? ?:作用是代表前面的字符出现0次或1次,即前面的字符可有可无。
6.元字符:+ +:作用是代表前面的字符匹配1-n次,至少出现一次。
7.字符: - -:作用是指出一个范围,如[0-9],[a-z],[A-Z]
8.元字符:$ $: $在字符串中一般放在最后,代表的是$前面的字符必须匹配给出的字符串的结尾字符,如果不是的话,返回空
9.元字符:^ ^: ^在[]中如果在最前面表示非[]的内容,如果在最后表示无其他意义的普通字符^,^在’字符串中时一般放最前面表示一个元字符,意义是只从给定字符串的行首开始匹配,如果从字符串的第一个字符与模式串的第一个字符不同就结束匹配,返回结果为空.
10.元字符:{}: {m,n}代表的意思是将前面的字符至少重复m次,至多重复n次。
11.贪婪模式和非贪婪模式,在’+‘和’*‘的后面加上’?‘代表的是非贪婪即尽可能少的匹配。
对于正则表达式可用到的一些函数:
1.re.compile()函数,对正则模式串进行编译,加快正则匹配的速度。
2.在匹配时,如果加入参数re.I代表的是匹配时自动忽略大小写。
3.匹配模式串前面加上r代表的是防止模式串中的字符转义,例如加上r(raw string:原生字符,原生字符中反斜杠就是反斜杠,无转义字符的意思)之后,模式串中的\n就不代表换行符,而是两个普通字符\和n。因此正则表达式用原生字符串编写。

4.正则表达式的match()函数与search()函数匹配成功返回的都是一个对象,match()返回MatchObject对象,search()也将返回MatchObject对象。
match()默认从字符串的第一个字符匹配,如果字符串的第一个字符不同于模式串的第一个字符,返回空(None). search()是从模式串中全局搜索匹配正则串。
5.MatchObject对象的方法和属性:

MatchObject对象的string属性获得和“正则模式串”匹配成功的string字符串。
6.split()函数:正则中的split()函数的一个比非正则中的split()函数好用的地方是它可以一次操作设置多个分割标识符。
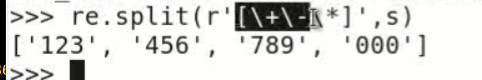
这里的+-*在正则中都是元字符,有着特殊的含义,需要用\来取消其特殊的含义。
7.sub()函数:正则中的sub()函数较非正则函数即参数不支持正则表达式的replace()的一个优点是,sub()函数由于支持了正则所以其在替换的时候支持同时对多个元素进行替换。
import re
s='、\ 非常好 ,'
print((re.sub(r"[、\\,]",'',s)).strip()) #在原生字符串中,虽然无转移符解释字符串,但\仍要两个\才能表示
#第一个参数是要被替换的符号,第二个参数是要替换成的符号,第三个参数为操作字符串,当第二个参数为空时,sub()的作用是剔除要被替换的元素。
#在第一个参数用列表来盛放多个要被替换的元素,而多个要被替换的元素之间不需要空格以及其他分隔符,直接挨着写下去。
################结果#####################
非常好
说明:subn()函数的参数和sub()函数一致,只是增加一个新的功能就是还可以返回是被替换的字符的个数。
8. 字符点'.'在正则式中默认是元字符即有着特殊的含义,其功能是匹配除换行符\n和退格符\t之外的所有字符,如果想要其也可以匹配换行符\n和退格符\t,只需要在函数中加入参数re.S即可。
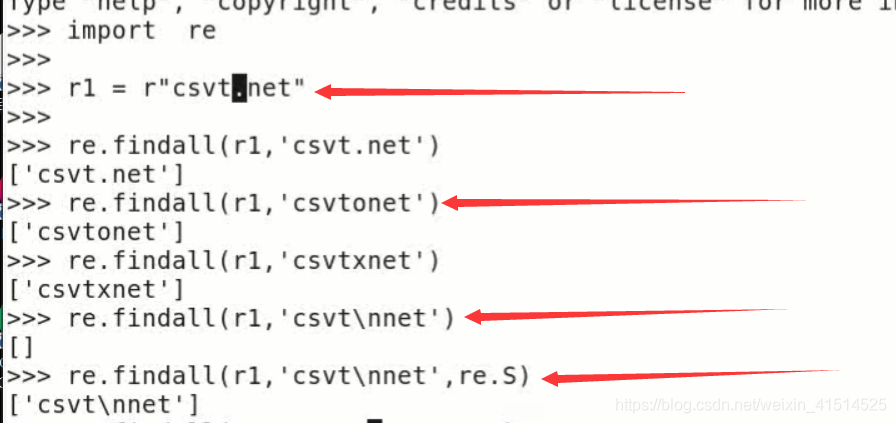
9. re.M参数可以设定正则匹配进行多行匹配,在进行与一个文件和一个多行字符串字段匹配时有时候用到。
10.正则的分组操作:分组操作后可对组内进行操作,如或操作。


11. 写了分组之后,匹配返回的默认是分组中的部分,这一点经常用于爬虫,获取网页上的有用信息。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









