







近日,微软进一步扩展了 Phi-4家族,推出了两款新模型:Phi-4多模态(Phi-4-multimodal)和 Phi-4迷你(Phi-4-mini),这两款模型的亮相,无疑将为各类 AI 应用提供更加强大的处理能力。
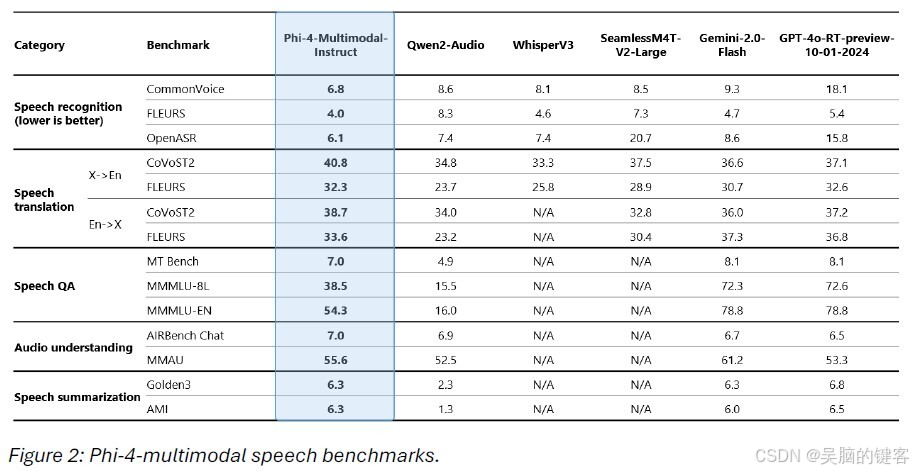
Phi-4多模态模型是微软首款集成语音、视觉和文本处理的统一架构模型,拥有5600万参数。这款模型在多项基准测试中表现优异,超越了目前市场上的许多竞争对手,例如谷歌的 Gemini2.0系列。在自动语音识别(ASR)和语音翻译(ST)任务中,Phi-4多模态模型表现尤为突出,成功击败了如 WhisperV3和 SeamlessM4T-v2-Large 等专业语音模型,词错误率更是以6.14% 的成绩位居 Hugging Face OpenASR 排行榜首位。

在视觉处理方面,Phi-4多模态模型同样表现出色。其在数学和科学推理方面的能力令人印象深刻,能够有效理解文档、图表和执行光学字符识别(OCR)。与 Gemini-2-Flash-lite-preview 和 Claude-3.5-Sonnet 等流行模型相比,该模型的表现不相上下,甚至更胜一筹。
另一款新发布的 Phi-4迷你模型则专注于文本处理任务,参数量为3800万。在文本推理、数学计算、编程和指令遵循等方面,Phi-4迷你表现卓越,超越了多款流行的大型语言模型。为了确保新模型的安全性和可靠性,微软邀请了内部与外部的安全专家进行全面测试,并按照微软人工智能红队(AIRT)的标准进行优化。
这两款新模型均可通过 ONNX Runtime 部署到不同设备上,适用于多种低成本和低延迟的应用场景。它们已在 Azure AI Foundry、Hugging Face 和 NVIDIA API 目录中上线,供开发者使用。毫无疑问,Phi-4系列的新模型标志着微软在高效 AI 技术上的重大进步,为未来的人工智能应用打开了新的可能性。
演示
安装依赖:
flash_attn==2.7.4.post1
torch==2.6.0
transformers==4.48.2
accelerate==1.3.0
soundfile==0.13.1
pillow==11.1.0
scipy==1.15.2
torchvision==0.21.0
backoff==2.2.1
peft==0.13.2
import requests
import torch
import os
import io
from PIL import Image
import soundfile as sf
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from urllib.request import urlopen
# Define model path
model_path = "microsoft/Phi-4-multimodal-instruct"
# Load model and processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
attn_implementation='flash_attention_2',
).cuda()
# Load generation config
generation_config = GenerationConfig.from_pretrained(model_path)
# Define prompt structure
user_prompt = '<|user|>'
assistant_prompt = '<|assistant|>'
prompt_suffix = '<|end|>'
# Part 1: Image Processing
print("\n--- IMAGE PROCESSING ---")
image_url = 'https://www.ilankelman.org/stopsigns/australia.jpg'
prompt = f'{user_prompt}<|image_1|>What is shown in this image?{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
# Download and open image
image = Image.open(requests.get(image_url, stream=True).raw)
inputs = processor(text=prompt, images=image, return_tensors='pt').to('cuda:0')
# Generate response
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
# Part 2: Audio Processing
print("\n--- AUDIO PROCESSING ---")
audio_url = "https://upload.wikimedia.org/wikipedia/commons/b/b0/Barbara_Sahakian_BBC_Radio4_The_Life_Scientific_29_May_2012_b01j5j24.flac"
speech_prompt = "Transcribe the audio to text, and then translate the audio to French. Use <sep> as a separator between the original transcript and the translation."
prompt = f'{user_prompt}<|audio_1|>{speech_prompt}{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
# Downlowd and open audio file
audio, samplerate = sf.read(io.BytesIO(urlopen(audio_url).read()))
# Process with the model
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to('cuda:0')
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
https://huggingface.co/microsoft/Phi-4-multimodal-instruct


















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









