




混合专家模型(Mixture of Experts,简称MoE)是一种先进的机器学习技术,旨在通过将复杂问题分解为多个子任务,并由多个专门的“专家”模型分别处理这些子任务来提高模型的效率和性能。MoE的核心思想是利用多个专家网络(Experts),每个专家专注于处理输入数据的不同部分或特定任务,从而实现对复杂问题的有效解决。
MoE的基本原理与组成
- 专家(Experts) :MoE模型由多个专家组成,每个专家是一个小型的神经网络,专门针对特定类型的输入或任务设计。这些专家可以是全连接网络、卷积网络、循环网络等,它们各自学习处理输入数据的一部分或某种特定的模式。
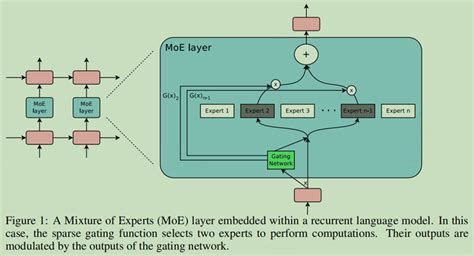
- 门控网络(Gating Network) :MoE模型通过一个门控网络来决定每个输入数据应由哪个专家处理。门控网络计算每个专家的权重,即输入数据对每个专家的“适用性”,从而动态选择最合适的专家进行处理。
- 融合模块(Fusion Module) :在所有专家完成其任务后,融合模块将各专家的输出进行汇总,生成最终的预测结果。这通常通过加权平均或其他集成方法实现。
MoE的优势与应用
- 提高效率与可扩展性:MoE通过仅激活部分专家,显著减少了计算需求,从而提高了推理速度并降低了模型训练成本。此外,MoE具有固有的可扩展性,随着任务复杂性的增加,可以无缝地集成更多专家以扩大专业知识范围。
- 处理复杂任务:MoE能够将一个大的复杂问题分解为多个小的、更易于管理的子问题,从而在不牺牲精度的前提下,显著降低计算成本并提高推理性能。
- 广泛的应用领域:MoE在自然语言处理、机器视觉、推荐系统等多个领域都有广泛应用。例如,在自然语言处理中,MoE被用于语言建模和多任务学习;在计算机视觉中,MoE被用于图像分类和目标检测。
MoE的挑战与优化
尽管MoE具有显著的优势,但其也面临一些挑战:
- 内存需求高:由于需要将所有专家的参数加载到内存中,MoE对分布式计算能力有较高要求。
- 训练复杂性:MoE模型的训练通常较为困难,因为缺乏闭合形式的参数更新,需要使用迭代算法如期望最大化(EM)算法进行优化。
- 系统优化:为了应对这些挑战,研究者提出了多种优化方法,包括优化内存占用、通信延迟、计算效率和并行扩展等。
MoE的发展与未来方向
MoE作为一种高效的集成学习技术,近年来在大模型领域得到了广泛关注。随着技术的不断进步,MoE有望在更多领域发挥重要作用。例如,在多模态大模型的发展浪潮中,MoE可能成为未来研究的新方向之一。此外,通过改进门控机制和专家选择策略,MoE在加速模型训练和提高性能方面仍具有巨大的潜力。
混合专家模型(MoE&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2514
2514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











