







 本文探讨了传统梯度优化的不足,介绍了动量算法、NAG算法、AdaGrad、RMSProp和Adam等自适应优化方法,强调了它们如何通过动态调整学习率和动量来改善收敛性能,特别关注稀疏数据和复杂非凸函数的优化。
本文探讨了传统梯度优化的不足,介绍了动量算法、NAG算法、AdaGrad、RMSProp和Adam等自适应优化方法,强调了它们如何通过动态调整学习率和动量来改善收敛性能,特别关注稀疏数据和复杂非凸函数的优化。
传统梯度优化不足
θ
←
θ
−
λ
g
\theta\leftarrow\theta-\lambda g
θ←θ−λg
学习率恰当时,可以收敛到全面最优点(凸函数)或局部最优点(非凸函数)
不足:学习率不易找。由于学习率保持不变,可能卡在鞍点位置。
动量算法
动量算法每下降一步都是有前面下降方向的一个累积和当前点的梯度方向组合而成。
计算速度:
v
←
α
v
−
λ
g
v\leftarrow \alpha v-\lambda g
v←αv−λg
更新参数:
θ
←
θ
+
v
\theta\leftarrow\theta+v
θ←θ+v
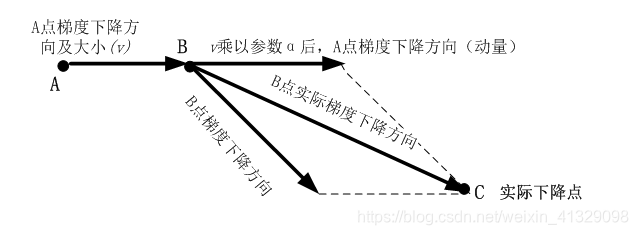
NAG算法(Nesterov Accelerated Gradient)
按照历史梯度向前走一小步,按照前面一小步位置的“超前梯度”来做梯度合并:
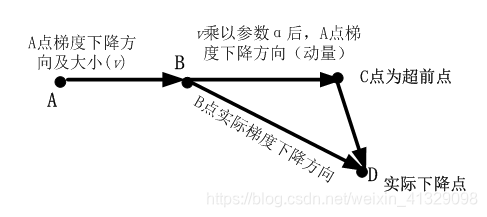
先往前走一步,在靠前一点的位置(C点)看到梯度,然后按照那个位置来修正这一步的梯度方向。
这种预更新方法能够防止大幅震荡,不会错过最小值,并会对参数更新更加敏感。
与之前不同的是在超前点更新梯度。(B点vsC点)
动量法更关注梯度下降方法的优化,如果能从方向和学习率同时优化,效果或许更理想。
j
接下来介绍几种自适应优化方法。
AdaGrad算法
通过参数来调整合适的学习率,是能独立地自动调整模型参数的学习率,对稀疏参数进行大幅更新和对频繁参数进行小幅更新。因此,Adagrad方法非常适合处理稀疏数据。
但还有些不足,可能因其累积梯度平方导致学习率过早或过量地减少导致。
核心计算:
- 对每个batch更新梯度得到g
- 累积平方梯度: r ← r + g ⊙ g r\leftarrow r+g\odot g r←r+g⊙g 【 ⊙ \odot ⊙代表逐元运算】
- 计算速度: △ θ ← − λ δ + r ⊙ g \triangle \theta\leftarrow-\frac{\lambda}{\delta+\sqrt{r}}\odot g △θ←−δ+rλ⊙g
- 更新参数: θ ← θ + △ θ \theta\leftarrow\theta+\triangle\theta θ←θ+△θ
RMSProp算法
针对AdaGrad的改进。针对梯度平方和累计越来越大的问题,RMSProp指数加权的移动平均代替梯度的平方和。RMSProp为了使用移动平均,还引入了一个新的超参数 ρ \rho ρ,用来控制移动平均的长度范围。
- 对每个batch更新梯度得到g
- 累积平方梯度:
r
←
ρ
r
+
(
1
−
ρ
)
g
⊙
g
r\leftarrow \rho r+(1-\rho) g\odot g
r←ρr+(1−ρ)g⊙g
【 ⊙ \odot ⊙代表逐元运算】 - 计算速度: △ θ ← − λ δ + r ⊙ g \triangle \theta\leftarrow-\frac{\lambda}{\delta+\sqrt{r}}\odot g △θ←−δ+rλ⊙g
- 更新参数:
θ
←
θ
+
△
θ
\theta\leftarrow\theta+\triangle\theta
θ←θ+△θ
实践中已被证明有用。
Adam算法
Adaptive Moment Estimation本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
核心:
- 更新梯度得到g
- 更新有偏一阶矩估计: s ← ρ 1 s + ( 1 − ρ 1 ) g s\leftarrow \rho_1 s+(1-\rho_1)g s←ρ1s+(1−ρ1)g
- 更新有偏二阶矩估计: r ← ρ 2 r + ( 1 − ρ 2 ) g ⊙ g r\leftarrow \rho_2 r+(1-\rho_2)g\odot g r←ρ2r+(1−ρ2)g⊙g
- 修正一阶矩偏差: s ^ = s 1 − ρ 1 t \hat{s}=\frac{s}{1-\rho_1^t} s^=1−ρ1ts (t为时间步)
- 修正二阶矩偏差: r ^ = s 1 − ρ 2 t \hat{r}=\frac{s}{1-\rho_2^t} r^=1−ρ2ts
- 累积平方梯度: r ← ρ r + ( 1 − ρ ) g ⊙ g r\leftarrow \rho r+(1-\rho) g\odot g r←ρr+(1−ρ)g⊙g
- 计算参数更新: △ θ ← − λ δ + r ⊙ g \triangle \theta\leftarrow-\frac{\lambda}{\delta+\sqrt{r}}\odot g △θ←−δ+rλ⊙g
- 更新参数: θ ← θ + △ θ \theta\leftarrow\theta+\triangle\theta θ←θ+△θ
RMSprop、Adadelta和Adam被认为是自适应优化算法,因为它们会自动更新学习率。使用SGD时,必须手动选择学习率和动量参数,通常会随着时间的推移而降低学习率。

















 5278
5278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









