




 本文深入探讨了超松弛迭代法(SOR)的原理与应用,通过数学公式详细解释了SOR法如何通过调整松弛因子ω来加速收敛过程。并提供了Python实现示例,展示了不同ω值对迭代次数的影响。
本文深入探讨了超松弛迭代法(SOR)的原理与应用,通过数学公式详细解释了SOR法如何通过调整松弛因子ω来加速收敛过程。并提供了Python实现示例,展示了不同ω值对迭代次数的影响。
二、超松弛迭代法(SOR)
1.原理:
回顾:
在一般情况下 : 收敛过慢甚至不收敛的BBB与fff,经过对系数矩阵AAA分裂成A=M−NA = M - NA=M−N的形式, 使得迭代公式变为: xk+1=(I−M−1)Axk+M−1fx^{k+1}=(I-M^{-1})Ax^{k}+M^{-1}fxk+1=(I−M−1)Axk+M−1f
***雅克比迭代法***选取 : 现将AAA如下分解A=D−L−UA = D-L-UA=D−L−U,DDD为对角阵,LLL为下三角阵,UUU为上三角阵,取M≡DM \equiv DM≡D,取N≡L+UN \equiv L+UN≡L+U,
在这一章中我们选取下三角矩阵M=1ω(D−ωL),ω>0M=\frac{1}{\omega}(D-\omega L),\omega>0M=ω1(D−ωL),ω>0,其中ω\omegaω为松弛因子,我们可以发现当ω\omegaω为1时,M=D−LM=D-LM=D−L,正是***高思-赛德尔***迭代法,下面推导迭代公式:
xk+1=I−M−1Axk+M−1b
\textbf{x}_{k+1}=I-M^{-1}A\textbf{x}_{k}+M^{-1}b
xk+1=I−M−1Axk+M−1b
xk+1=I−ω(D−ωL)−1Axk+ω(D−ωL)−1b \textbf{x}_{k+1}=I-\omega(D-\omega L)^{-1}A\textbf{x}_{k}+\omega (D-\omega L)^{-1}b xk+1=I−ω(D−ωL)−1Axk+ω(D−ωL)−1b
xk+1=(D−ωL)−1((1−ω)D+ωU)xk+ω(D−ωL)−1b \textbf{x}_{k+1}=(D-\omega L)^{-1}((1-\omega)D+\omega U)\textbf{x}_{k}+\omega (D-\omega L)^{-1}b xk+1=(D−ωL)−1((1−ω)D+ωU)xk+ω(D−ωL)−1b
推导完毕,我们较为常用的是下式:
(D−ωL)xk+1=((1−ω)D+ωU)xk+ωb
(D-\omega L)\textbf{x}_{k+1}=((1-\omega)D+\omega U)\textbf{x}_{k}+\omega b
(D−ωL)xk+1=((1−ω)D+ωU)xk+ωb
以及:
{x(0)=(x1(0),...,xn(0))T,xi(k+1)=xi(k+)+ΔxiΔxi=ωbi−∑j=1i−1aijxj(k+1)−∑j=1naijxj(k)aiii=1,2,...,n,k=0,1,...,ω为松弛因子
\left\{
\begin{matrix}
\textbf{x}^{(0)} &=& (x_1^{(0)},\textbf{...},x_n^{(0)})^{T}, \\
x_i^{(k+1)} &=& x_i^{(k+)}+ \Delta x_{i} \\
\Delta x_{i} &=& \omega \frac{b_{i}- \sum\limits_{j=1}^{i-1}a_{ij}x_{j}^{(k+1)}-\sum\limits_{j=1}^{n}a_{ij}x_{j}^{(k)}}{a_{ii}} \\
i &=&1,2,...,n,k=0,1,...,\\
\omega为松弛因子
\end{matrix}
\right.
⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧x(0)xi(k+1)Δxiiω为松弛因子====(x1(0),...,xn(0))T,xi(k+)+Δxiωaiibi−j=1∑i−1aijxj(k+1)−j=1∑naijxj(k)1,2,...,n,k=0,1,...,
当ω>1\omega>1ω>1时为超松弛迭代,当ω<1\omega<1ω<1时为低松弛迭代
迭代终止条件:max1≤i≤n∣Δxi∣=max1≤i≤n∣xi(k+1)−xi(k)∣<ε\mathop{max}\limits_{1\le i\le n}|\Delta x_{i}| = \mathop{max}\limits_{1\le i\le n}|x_{i}^{(k+1)}-x_{i}^{(k)}|<\varepsilon1≤i≤nmax∣Δxi∣=1≤i≤nmax∣xi(k+1)−xi(k)∣<ε,下面我们试试用Python实现这一功能.
2.实现:
import numpy as np
import matplotlib.pyplot as plt
MAX = 110 # 遍历最大次数
A = np.array([[-4, 1, 1, 1], [1, -4, 1, 1], [1, 1, -4, 1], [1, 1, 1, -4]])
b = np.array([[1], [1], [1], [1]]) # 注意这里取列向量
omega_list = [1 + 0.005 * i for i in range(100)] # 取到不同的omega值,观察趋势
length = len(A)
count = [] # 记录遍历的次数
for omega in omega_list: # 遍历每一个omega值
times = 0
x_0 = np.zeros((length, 1))
x_hold = x_0 + np.ones((length, 1))
while (np.linalg.norm(x_hold - x_0, ord=2) >= 10 ** (-5)) and (times <= MAX):
# 遍历停止条件以k+1次与k次迭代的向量差的二范数以及遍历最大次数为标准
x_hold = x_0.copy() # 这里不要用赋值,要用copy
x_new = x_0.copy()
for i in range(length):
# 根据迭代公式迭代
x_new[i][0] = x_0[i][0] + omega * (b[i][0] - sum([A[i][j] * x_new[j][0] for j in range(i)]) - sum(
[A[i][j] * x_0[j][0] for j in range(i, length)])) / A[i][i]
x_0 = x_new.copy()
times += 1
count.append(times)
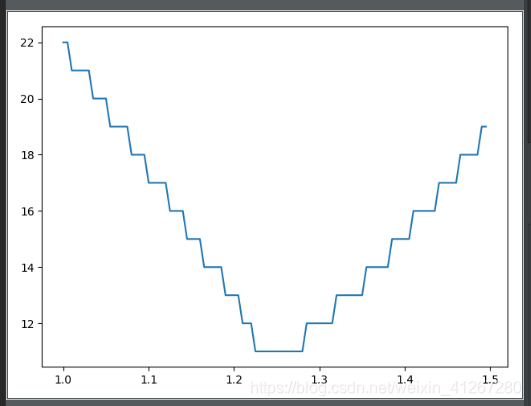
plt.plot(omega_list, count) # 观察omega与迭代次数的关系
plt.show()
思路:
1.遍历设限:第一种是到达精度,到达精度停止迭代,第二种是到达规定最大次数,这个可以自己设定.
2.在根据迭代公式改变各个向量分量时,要注意遍历范围.
结果:

















 4263
4263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









