







 本章探讨计算学习理论,关注PAC学习、有限假设空间及其在可分和不可分情况下的学习分析。重点介绍了VC维的概念,它是衡量假设空间复杂度的重要指标,对于理解学习算法的泛化能力具有关键作用。
本章探讨计算学习理论,关注PAC学习、有限假设空间及其在可分和不可分情况下的学习分析。重点介绍了VC维的概念,它是衡量假设空间复杂度的重要指标,对于理解学习算法的泛化能力具有关键作用。
第十二章 计算学习理论
- 概述
- 关注的问题
- 一些概念及记号
- 可学习性
- 什么是“学习”
- 什么是“可学习的”
- 假设空间复杂性对可学习性的影响
- 有限假设空间
- 无限假设空间:基于VC维的分析
- 无限假设空间:基于Rademacher复杂度的分析
- 稳定性
12.2 PAC学习
-
假设空间:学习算法所考虑的所有可能概念的集合 H
-
目标概念:正确的x -> y的映射 c
-
可分的:c 属于 H
-
不可分:c 不属于H (虽然目标不在假设空间中,但可找到近似的概念,在假设空间中)
-
可分 & 不可分 != 可学 & 不可学
-
给定训练集D,希望学习算法学得的模型所对应的假设h尽可能接近目标概念c
-
PAC 辨识:学得一个假设,满足误差要求,并以一定的概率出现

-
PAC可学习:利用有限样本找到目标概念类的近似
-
把对复杂算法的时间复杂度的分析转为对样本复杂度的分析
-
假设空 H 的复杂度是影响可学习性的重要因素之一
12.3 有限假设空间
1. 可分情形
-
怎么找到满足误差参数的假设?
- 任何在训练集D上出现标记错误的假设肯定不是目标概念C,一点点剔除即可,直到只剩下一个。
-
到底需要多少样例才能学得目标概念c的有效近似呢?
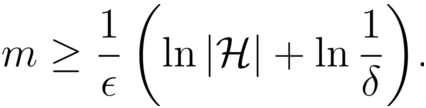
-
可分情况下的有限假设空间 H 都是PAC可学习的, 输出假设h的泛化误差随样例数目的增多而收敛到0, 收敛速率为O(1/m)
2. 不可分情况
- 找泛化误差最小的假设 近似
- 有限假设集是不可知PAC可学习的
12.4 VC维
-
针对无限假设
-
增长函数(growth function)
- 随着m的增大, H 中所有假设对 D 中的示例所能赋予标记的可能结果数也会增大.
- H 对示例所能赋予标记的可能结果数越大, H 的表示能力越强, 对学习任务的适应能力也越强.
- 增长函数表述了假设空间 H 的表示能力, 由此反映出假设空间的复杂度
-
对分(dichotomy)
- 对二分类问题来说, H 中的假设对 D 中示例赋予标记的每种可能结果称为对 D 的一种“对分”.
-
打散(shattering)
- 假设空间 H 能实现实例集 D 上的所有对分(对所有结果都表现出)
-
基于VC维的泛化误差界是分布无关、数据独立的, 这使得基于 VC维的可学习性分析结果具有一定的“普适性”。
-
无论基于VC维和Rademacher复杂度来分析泛化性能, 得到的结果均与具体的学习算法无关, 这使得人们能够脱离具体的学习算法来考虑学习问题本身的性质。
-
若学习算法L 满足经验风险最小化且稳定的,则假设空间H可学习。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









