







第十一章 特征选择与稀疏学习
-
特征选择:子集选择、子集评价
- 过滤式选择
- 包裹式选择
- 嵌入式选择:用L1Z正则化
-
稀疏表示:
- 字典学习
- 压缩感知
11.1 子集搜索与评价
-
特征的分类
- 相关特征: 对当前学习任务有用的属性
- 无关特征: 与当前学习任务无关的属性(会增加构建学习器的难度)
- 冗余特征*: 其所包含信息能由其他特征推演出来(有用的不需要去掉,使得学习算法更有利求解)
-
特征选择的一般方法:
- 遍历所有可能的子集 ——> 计算上遭遇组合爆炸,不可行
- 可行方法:
- 产生初始候选子集
- 评价候选子集的好坏
-
两个关键环节:
- 子集搜索(贪心算法)
- 前向搜索:逐渐增加相关特征
- 后向搜索:从完整的特征集合开始,逐渐减少特征
- 双向搜索:每一轮逐渐增加相关特征,同时减少无关特征
- 子集评价
- 使用信息增益,选择信息增益大的属性
- 子集搜索(贪心算法)
11.2 常见的特征选择方法
- 将特征子集搜索机制与子集评价机制相结合,即可得到特征选择方法
1. 过滤式
- 先用特征选择过程过滤原始数据,再用过滤后的特征来训练模型;特征选择过程与后续学习器无关
- Relief (Relevant Features) 方法 [Kira and Rendell, 1992]
- 为每个初始特征赋予一个“相关统计量”,度量特征的重要性
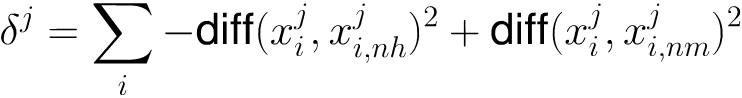
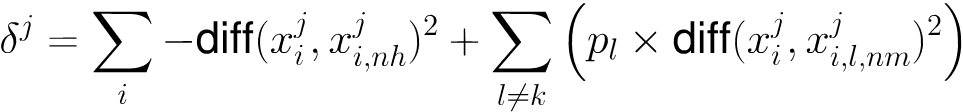
- 为每个初始特征赋予一个“相关统计量”,度量特征的重要性
- 同类样本属性尽可能相似,不同类上属性差异越大越好。
2. 包裹式
-
特征选择与算法结合,量身定制。不同分类算法选出的特征不一致。
-
从最终学习器性能来看,包裹式特征选择比过滤式特征选择更好;计算开销通常比过滤式特征选择大得多
-
LVW包裹式特征选择方法:
- LVW(Las Vegas Wrapper)[Liu and Setiono, 1996] 在拉斯维加斯方法框架下使用随机策略来进行子集搜索,并以最终分类器的误差作为特征子集评价准则
-
基本步骤:
- 在循环的每一轮随机产生一个特征子集
- 在随机产生的特征子集上通过交叉验证推断当前特征子集的误差
- 进行多次循环,在多个随机产生的特征子集中选择误差最小的特征子集作为最终解*
- *若有运行时间限制,则该算法有可能给不出解
3. 嵌入式
- 嵌入式特征选择是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,在学习器训练过程中自动地进行特征选择
- 求解L1范数正则化的结果是得到了仅采用一部分初始特征的模型。即,基于L1Z正则化的学习方法就是一种嵌入式特征选择方法(因为L1不易于获得“稀疏解”),其特征选择过程与学习器训练过程融为一体。
- 可以使用近端梯度下降去求解L1正则化问题。
11. 5稀疏表示与字典学习
- 稀疏表达的优势:
- 文本数据线性可分
- 存储高效
1. 字典学习
- 为普通稠密表达的样本找到合适的字典,将样本转化为稀疏表示,这一过程称为字典学习
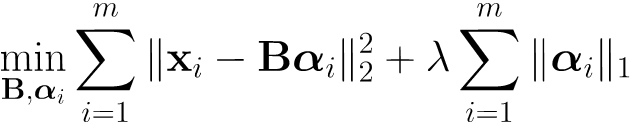
- 可以采用变换交替优化的策略来求解上式,B&ai,用户能通过设置词汇量k的大小来控制字典的规模,从而影响到稀疏程度。
11.6 压缩感知
- 利用部分数据恢复全部数据


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









