







 本文探讨了数据挖掘中的组合分类器技术,包括构造原理、偏倚-方差分解、装袋、提升(如Adaboost)和随机森林。此外,还讨论了在不平衡类问题中面临的挑战,如可选度量(如准确率、召回率、F1分数)、ROC曲线和代价敏感学习,以及基于抽样的解决方案。
本文探讨了数据挖掘中的组合分类器技术,包括构造原理、偏倚-方差分解、装袋、提升(如Adaboost)和随机森林。此外,还讨论了在不平衡类问题中面临的挑战,如可选度量(如准确率、召回率、F1分数)、ROC曲线和代价敏感学习,以及基于抽样的解决方案。
第五章 分类:其他技术
5.6 组合方法
1. 构造组合分类器的原理和方法
- 基分类器需要互相独立,且比随机猜测要好。
- 构建组合分类器的方法:
- 通过处理训练数据集:根据抽样分布对原始数据重新采样
- 装袋(bagging)、提升(boosting)
- 通过处理输入特征:选择输入特征的子集来形成每个训练集
- 随机森林
- 通过处理类标号(变换为二类问题):
- 错误-纠正输出编码
- 通过处理学习算法
- 通过处理训练数据集:根据抽样分布对原始数据重新采样
- 组合方法对于不稳定的分类器效果较好(决策树、ANN)
2. 偏倚-方差分解
- 分析预测模型的预测误差的形式化方法
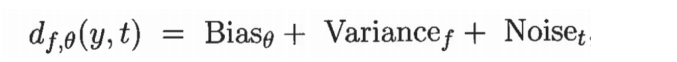
- 偏倚:分类器对它的决策边界性质所做的假定越强,分类器的偏倚就越大。
- 更下的树,假定越强
3. 组合方法技术
-
装袋
- 通过减少基分类器的方差来改善泛化误差
- 装袋有助于提升不稳定的基分类器
-
提升
- 迭代地改变训练样本的分布,提高误分类样本的权值,降低正确分类的样本的权重
- 通过聚集每个提升轮得到的基分类器,就得到最终的组合分类器。
- 提升算法的差别:
- 每轮提升结果时如何更新训练样本的权值
- 如何组合每个分类器的预测
-Adaboost
- 将注意力集中在错分的样本上,因此很容易过拟合
4. 随机森林
- 专门为决策树分类器设计的组合方法
- 采用 一个固定的概率分布来产生随机向量
5. 不平衡类问题
1) 可选度量
- 准确率度量将每个类看得同等重要,不适合用来分析不平衡数据集
- 召回率:
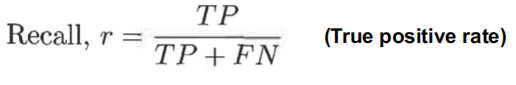
- 拥有高召回率的分类器很少将正样本误分为负样本
- 精度(precision):
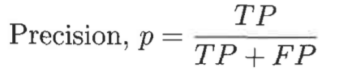
- F1度量:将精度和召回率合并成一个度量
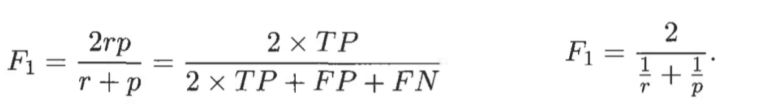
2) ROC曲线
- 显示真正率(TPR)和假正率(FPR)之间折中的一种图形化方法
- (0,0) ——> 把每个实例都预测为负类的模型
3) 代价敏感学习
- 代价矩阵对将一个类的记录分类到另一个类的惩罚进行编码
4) 基于抽样的方法
- 改变实例的分布,从而帮助稀有类在训练数据集中得到很好的表示
- 技术:
- 不充分抽样:会丢失大类的有用信息
- 过分抽样:
- 模型过拟合
- 额外的稀有类的样本会增加建模的计算时间。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









