




字典(Dictionary)是Python中一种可变容器模型,可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,整个字典包括在花括号 {} 中。
目录
1. 创建字典
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
# 创建空字典
dict1 = {}
dict2 = dict()
# 创建有初始值的字典
dict3 = {'name': 'Alice', 'age': 25}
dict4 = dict(name='Bob', age=30)
# 使用zip创建字典
keys = ['name', 'age']
values = ['Charlie', 35]
dict5 = dict(zip(keys, values))
# 使用字典推导式创建字典
dict6 = {x: x**2 for x in (2, 4, 6)}2. 访问字典里的值
person = {'name': 'David', 'age': 40}
# 通过键访问值
print(person['name']) # 输出: David
# 使用get()方法访问(更安全,键不存在时返回None或默认值)
print(person.get('age')) # 输出: 40
print(person.get('address', 'Not Found')) # 输出: Not Found
# 获取所有键
print(person.keys()) # 输出: dict_keys(['name', 'age'])
# 获取所有值
print(person.values()) # 输出: dict_values(['David', 40])
# 获取所有键值对
print(person.items()) # 输出: dict_items([('name', 'David'), ('age', 40)]))3. 修改字典
person = {'name': 'Eva', 'age': 28}
# 更新现有键的值
person['age'] = 29
# 添加新键值对
person['address'] = 'New York'
# 使用update()方法合并字典
person.update({'job': 'Engineer', 'age': 30}) # age会被更新
# 合并字典的另一种方式(Python 3.5+)
other_info = {'hobby': 'reading', 'email': 'eva@example.com'}
person = {**person, **other_info}4. 删除字典元素
person = {'name': 'Frank', 'age': 45, 'job': 'Doctor'}
# 删除指定键值对
del person['age']
# 使用pop()删除并返回指定键的值
job = person.pop('job') # job变量现在为'Doctor'
# 使用popitem()删除并返回最后插入的键值对(Python 3.7+保证)
key, value = person.popitem()
# 清空字典
person.clear() # 现在person是空字典{}
# 删除整个字典
del person5. 字典内置函数
| 序号 | 函数及描述 | 实例 |
|---|---|---|
| 1 | len(dict) 计算字典元素个数,即键的总数。 | >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
>>> len(tinydict)
3 |
| 2 | str(dict) 输出字典,可以打印的字符串表示。 | >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
>>> str(tinydict)
"{'Name': 'Runoob', 'Class': 'First', 'Age': 7}" |
| 3 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 | >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
>>> type(tinydict)
<class 'dict'> |
person = {'name': 'Grace', 'age': 50}
# len() - 获取字典长度
print(len(person)) # 输出: 2
# str() - 字典的字符串表示
print(str(person)) # 输出: {'name': 'Grace', 'age': 50}
# type() - 检查类型
print(type(person)) # 输出: <class 'dict'>
# sorted() - 获取排序后的键列表
print(sorted(person)) # 输出: ['age', 'name']6. 字典内置方法
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| 5 | key in dict 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回一个视图对象 |
| 7 | dict.keys() 返回一个视图对象 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 返回一个视图对象 |
| 11 | dict.pop(key[,default]) 删除字典 key(键)所对应的值,返回被删除的值。 |
| 12 | dict.popitem() 返回并删除字典中的最后一对键和值。 |
# copy() - 浅拷贝字典
original = {'a': 1, 'b': [2, 3]}
new_dict = original.copy()
# fromkeys() - 从序列创建新字典
keys = ['name', 'age', 'job']
default_value = 'unknown'
person = dict.fromkeys(keys, default_value)
# setdefault() - 获取键值,如果键不存在则设置默认值
age = person.setdefault('age', 0) # 返回'unknown'因为键已存在
salary = person.setdefault('salary', 5000) # 添加'salary': 5000
# items(), keys(), values() - 视图对象
for key, value in person.items():
print(f"{key}: {value}")7. 字典的作用
字典是Python中最强大、最常用的数据结构之一,它以键值对(key-value)的形式存储数据,具有以下重要作用和应用场景:
1. 高效的数据查找与存储
-
快速访问:通过键(key)可以快速查找对应的值(value),时间复杂度为O(1)
-
无序集合:存储无需考虑顺序的数据集合(注:Python 3.7+字典保持插入顺序)
2. 数据关联与结构化存储
-
存储对象属性:如学生信息、商品详情等结构化数据
student = { 'name': '张三', 'age': 20, 'major': '计算机科学', 'grades': {'数学': 90, '英语': 85} } -
表示关系型数据:如数据库记录、API返回的JSON数据等
3. 计数与统计
-
元素频率统计:统计列表中各元素出现的次数
from collections import defaultdict word_list = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple'] word_count = defaultdict(int) for word in word_list: word_count[word] += 1
4. 缓存与记忆化(Memoization)
-
函数结果缓存:存储昂贵计算的结果以避免重复计算
cache = {} def expensive_func(n): if n not in cache: cache[n] = ... # 复杂计算过程 return cache[n]
5. 配置与设置管理
-
存储程序配置:集中管理应用程序的各种设置
config = { 'debug': True, 'database': { 'host': 'localhost', 'port': 5432, 'user': 'admin' }, 'max_connections': 100 }
6. 实现高级数据结构
-
模拟图结构:表示图的邻接表
graph = { 'A': ['B', 'C'], 'B': ['A', 'D'], 'C': ['A', 'D'], 'D': ['B', 'C'] } -
稀疏矩阵:高效表示大部分元素为0的矩阵
7. 函数编程应用
-
处理可变关键字参数:在函数定义中使用
**kwargsdef print_info(**kwargs): for key, value in kwargs.items(): print(f"{key}: {value}") print_info(name='Alice', age=25, city='New York') -
动态参数传递:使用字典解包传递参数
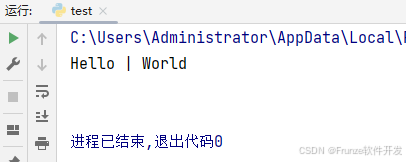
params = {'sep': ' | ', 'end': '\n\n'} print('Hello', 'World', **params)
8. 数据转换与映射
-
值转换:建立映射关系进行数据转换
month_map = { 1: 'January', 2: 'February', # ... 12: 'December' } print(month_map[3]) # 输出'March'(假设已定义)
9. JSON数据处理
-
与JSON互转:字典结构与JSON格式天然兼容
import json data = {'name': 'John', 'age': 30} json_str = json.dumps(data) # 字典转JSON字符串 new_dict = json.loads(json_str) # JSON字符串转字典
10. 替代多重if-else
-
调度表模式:用字典代替复杂的条件判断
def operation_add(a, b): return a + b def operation_sub(a, b): return a - b operations = { 'add': operation_add, 'subtract': operation_sub } result = operations['add'](5, 3) # 返回8
字典因其高效的查找性能(O(1)时间复杂度)和灵活的结构,成为Python中处理关联数据的首选工具,广泛应用于Web开发、数据分析、人工智能等各个领域。


















 1466
1466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









