




pickle 是 Python 的一个强大序列化模块,它可以将几乎任何 Python 对象转换为字节流(序列化),也可以从字节流重新构造对象(反序列化)。
目录
1. 基本用法
1.1 序列化对象(pickling)
import pickle
data = {
'name': 'Alice',
'age': 30,
'scores': [85, 92, 88],
'is_active': True
}
# 序列化到字节对象
serialized = pickle.dumps(data)
print(serialized) # 输出字节序列
# 序列化到文件
with open('data.pkl', 'wb') as f: # 注意是二进制写入模式
pickle.dump(data, f)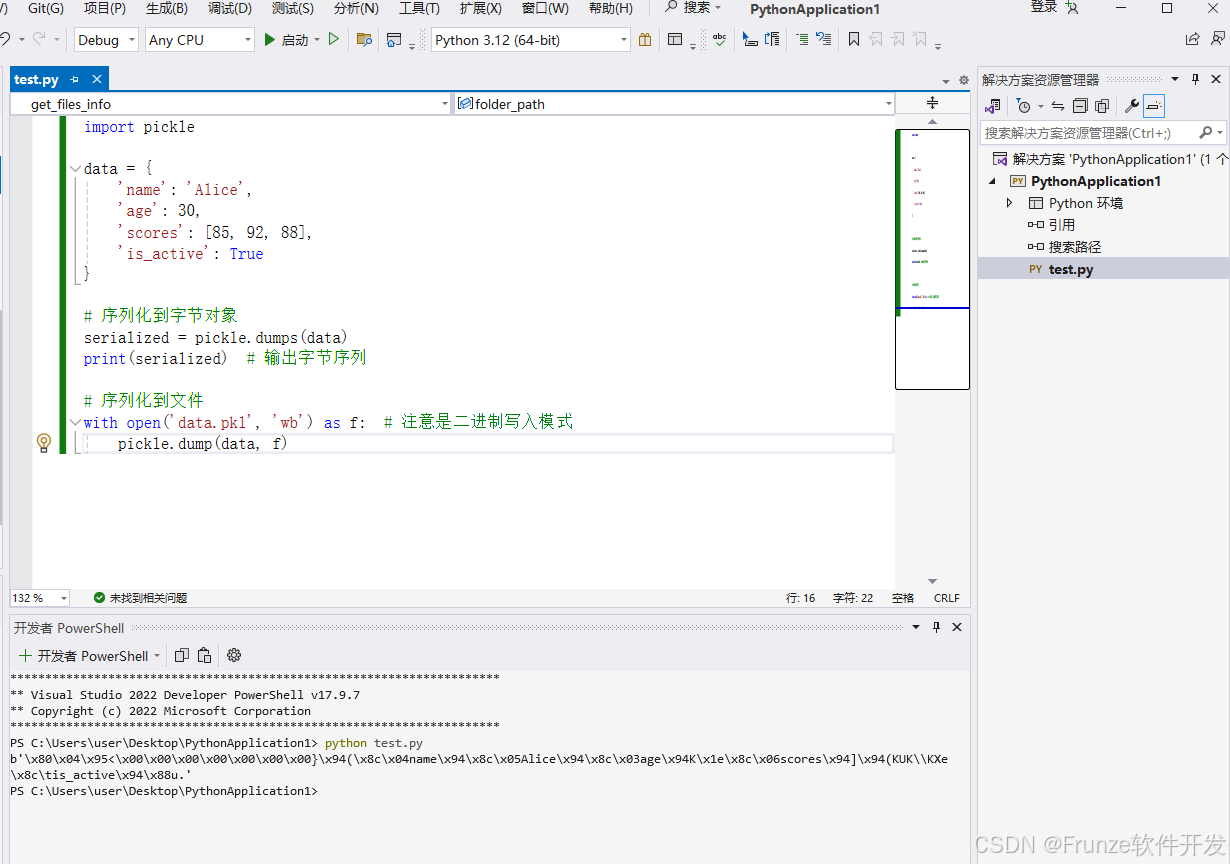
1.2 反序列化对象(unpickling)
import pickle
# 首先创建一个示例数据对象
data = {
'name': 'Alice',
'age': 30,
'scores': [85, 92, 88],
'is_active': True
}
# 1. 序列化对象到字节(创建serialized变量)
serialized = pickle.dumps(data)
print("序列化后的字节数据:", serialized)
# 2. 从字节对象反序列化
deserialized = pickle.loads(serialized)
print("反序列化后的数据:", deserialized) # 输出原始数据
# 3. 序列化到文件
with open('data.pkl', 'wb') as f: # 注意是二进制写入模式
pickle.dump(data, f)
# 4. 从文件反序列化
with open('data.pkl', 'rb') as f: # 注意是二进制读取模式
loaded_data = pickle.load(f)
print("从文件加载的数据:", loaded_data)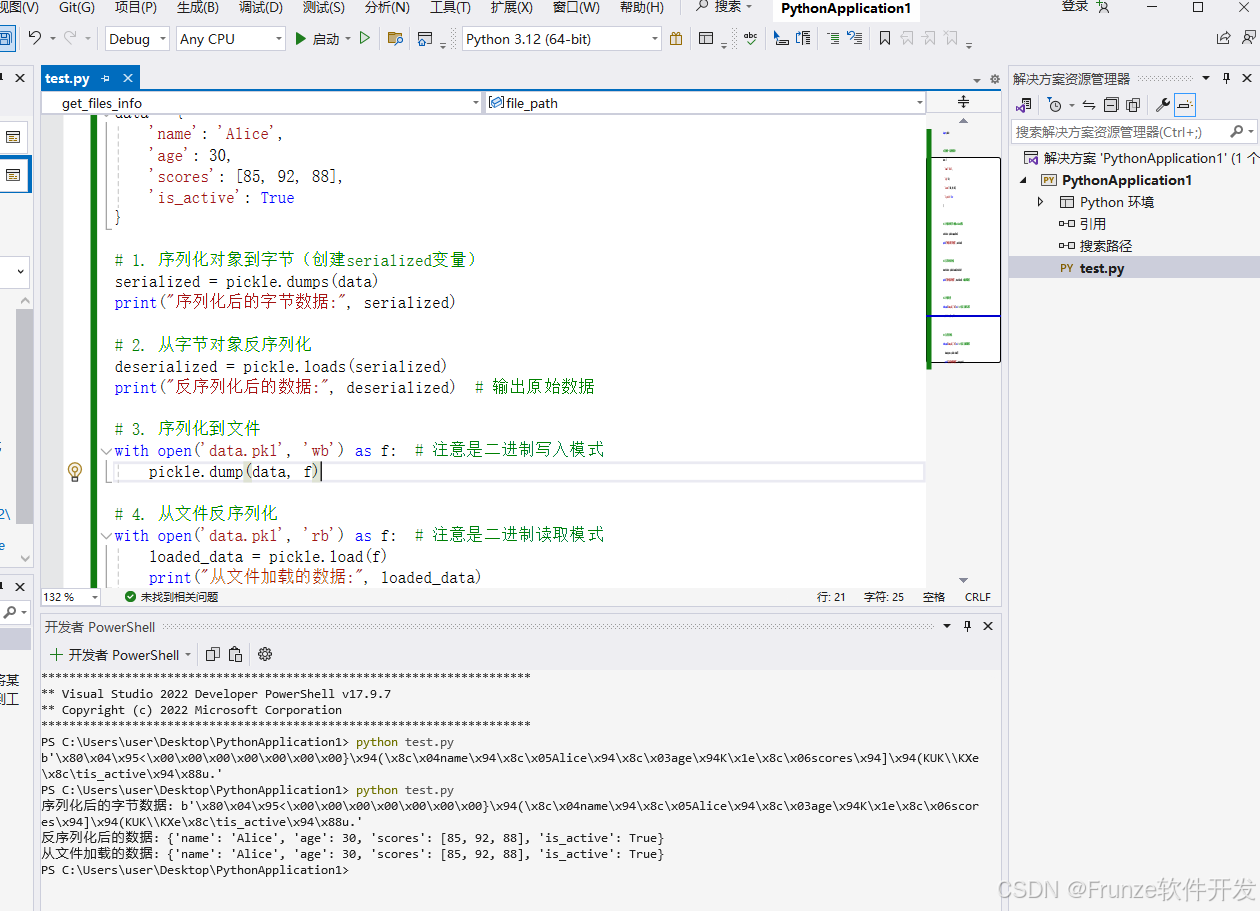
2. 可序列化的对象类型
pickle 可以序列化大多数 Python 对象,包括:
-
基本数据类型(int, float, bool, str 等)
-
容器类型(list, tuple, dict, set)
-
函数和类(只序列化名称,不序列化代码)
-
类的实例(包括自定义类)
-
模块级函数和类
3. 高级特性
3.1 自定义类的序列化
import pickle
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __repr__(self):
return f"Person(name='{self.name}', age={self.age})"
alice = Person('Alice', 30)
# 序列化自定义类实例
with open('person.pkl', 'wb') as f:
pickle.dump(alice, f)
# 反序列化
with open('person.pkl', 'rb') as f:
loaded_person = pickle.load(f)
print(loaded_person) # Person(name='Alice', age=30)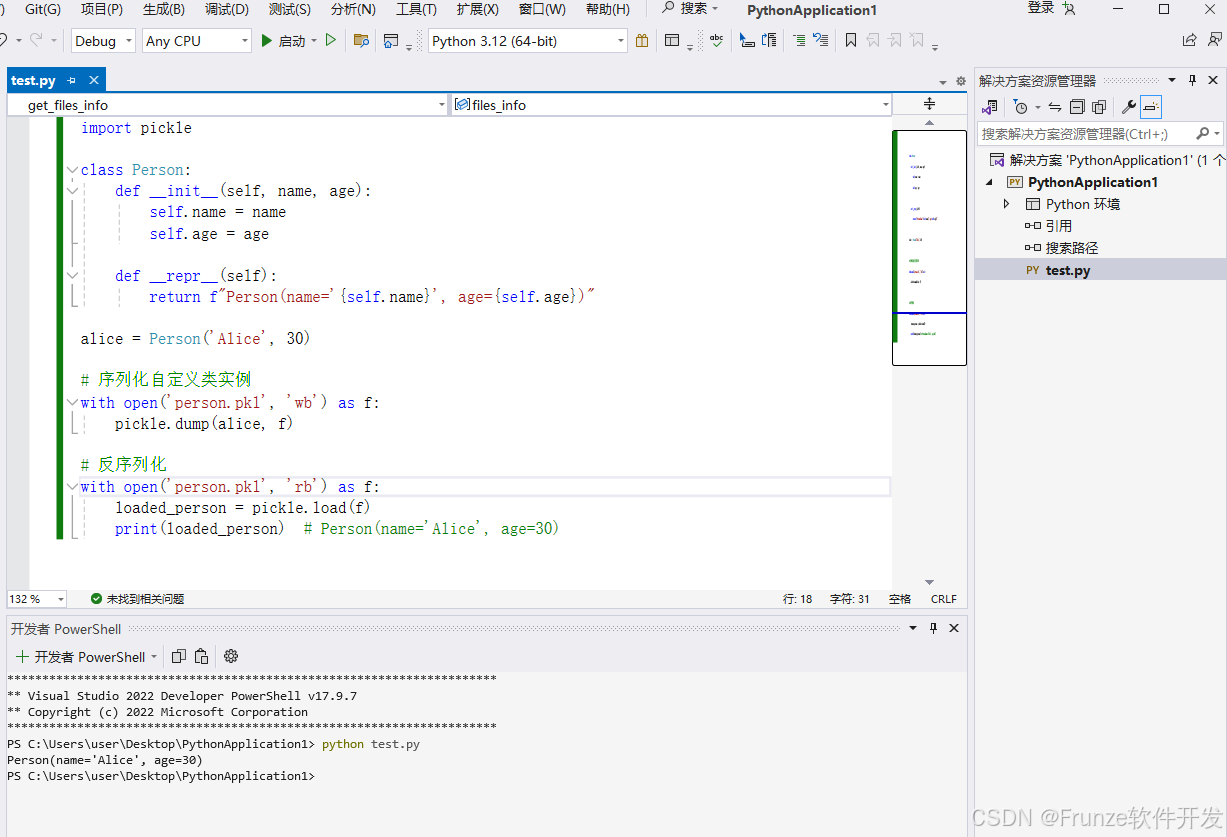
3.2 序列化协议版本
pickle 有多个协议版本,可以通过 protocol 参数指定:
# 使用最高效的协议版本(Python 3.8+默认使用协议4)
pickle.dumps(data, protocol=pickle.HIGHEST_PROTOCOL)
# 可用的协议版本:
# 0 - 原始ASCII协议(兼容旧版本)
# 1 - 旧二进制格式
# 2 - Python 2.3引入
# 3 - Python 3.0引入(默认Python 3.0-3.7)
# 4 - Python 3.4引入(默认Python 3.8+)
# 5 - Python 3.8引入(支持带外数据)4. 安全注意事项
⚠️ 重要警告:pickle 反序列化可以执行任意代码,永远不要反序列化不受信任来源的数据!
# 不安全的做法(可能执行恶意代码)
malicious_data = b"cos\nsystem\n(S'rm -rf /'\ntR." # 模拟恶意pickle数据
# pickle.loads(malicious_data) # 危险!会执行系统命令安全替代方案:
-
对于不受信任的数据,使用
json模块 -
或者使用
ast.literal_eval()处理简单数据结构
5. 特殊方法控制序列化
自定义类可以通过实现特殊方法来控制序列化行为:
import pickle
class CustomObject:
def __init__(self, value):
self.value = value
self._internal = "secret"
# 定义序列化时要保存的属性
def __getstate__(self):
state = self.__dict__.copy()
del state['_internal'] # 不序列化内部属性
return state
# 定义反序列化时的行为
def __setstate__(self, state):
self.__dict__.update(state)
self._internal = "restored" # 恢复时重新设置
obj = CustomObject(42)
serialized = pickle.dumps(obj)
new_obj = pickle.loads(serialized)
print(new_obj.value) # 42
print(new_obj._internal) # "restored"
6. 性能优化
对于大型对象的序列化:
# 使用更高效的协议
data = [i**2 for i in range(100000)]
# 比较不同协议的大小
for proto in range(pickle.HIGHEST_PROTOCOL + 1):
size = len(pickle.dumps(data, protocol=proto))
print(f"协议 {proto}: {size} 字节")
# 使用更快的pickle实现(需要安装)
# pip install pickle5 # 对于Python < 3.8想使用协议57. 实际应用场景
7.1 缓存计算结果
import pickle
import hashlib
import os
def compute_expensive_operation(params):
cache_file = f"cache_{hashlib.md5(str(params).encode()).hexdigest()}.pkl"
if os.path.exists(cache_file):
with open(cache_file, 'rb') as f:
return pickle.load(f)
# 模拟耗时计算
result = sum(x**2 for x in range(params['n']))
# 缓存结果
with open(cache_file, 'wb') as f:
pickle.dump(result, f)
return result7.2 进程间通信
import pickle
from multiprocessing import Pool
# 在多进程中使用pickle传递数据
def process_data(data):
# 处理数据...
return data * 2
if __name__ == '__main__':
data = [1, 2, 3, 4, 5]
with Pool() as pool:
results = pool.map(process_data, data)
print(results) # [2, 4, 6, 8, 10]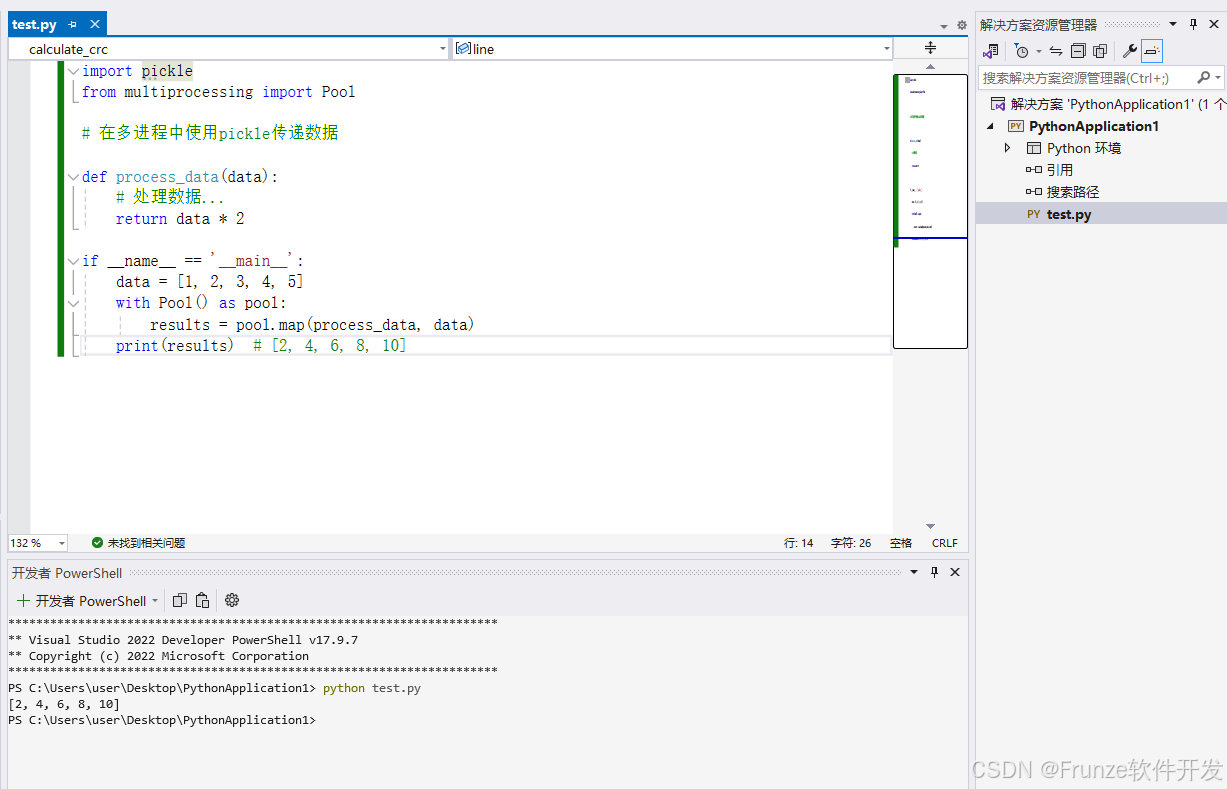
8. 替代方案比较
| 特性 | pickle | json | marshal | shelve |
|---|---|---|---|---|
| 人类可读 | ❌ | ✅ | ❌ | ❌ |
| 跨语言支持 | ❌ | ✅ | ❌ | ❌ |
| 序列化复杂对象 | ✅ | ❌ | ⚠️ | ✅ |
| 安全性 | ❌ | ✅ | ❌ | ❌ |
| 内置支持 | ✅ | ✅ | ✅ | ✅ |
总结
pickle 是 Python 中最强大的序列化工具,适合:
-
需要保存 Python 特有对象(如自定义类实例)
-
临时存储 Python 数据
-
进程间传递复杂对象
但需要注意:
-
永远不要反序列化不受信任的数据
-
pickle 文件不能跨 Python 版本/实现(如 CPython 和 PyIron)兼容
-
对于长期存储或跨语言场景,考虑使用 JSON 或其他格式



















 1477
1477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









