




 本文详细介绍了使用Python的Pandas库进行数据处理的基本方法,包括创建Series和DataFrame,利用date_range生成日期范围,以及如何通过标签和位置选择数据。通过实例演示了数据筛选、排序和查看数据类型的技巧。
本文详细介绍了使用Python的Pandas库进行数据处理的基本方法,包括创建Series和DataFrame,利用date_range生成日期范围,以及如何通过标签和位置选择数据。通过实例演示了数据筛选、排序和查看数据类型的技巧。
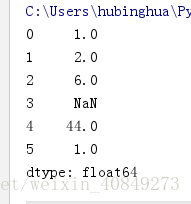
1、Series
import numpy as np
s = pd.Series([1,2,6,np.nan,44,1])
print(s)结果:
2、date_range和DataFrame
import pandas as pd
import numpy as np
dates = pd.date_range('20160101',periods=6)#时间数据
print(dates)
df = pd.DataFrame(np.random.rand(6,4),index=dates,columns=['a','b','c','c'])#建立数据框架
print(df)
df1 = pd.DataFrame(np.arange(12).reshape(3,4))#若没有规定像df中那样的标签,那么默认从0.1...开始给定标签
print(df1)
df2 = pd.DataFrame(
{'A':1.,
'B':pd.Timestamp('20130102'),
'C':pd.Series(1,index=list(range(4)),dtype='float32'),
'D':np.array([3]*4,dtype='int32'),
'E':pd.Categorical(['train','test','train','test']),
'F':'foo'
}
)
print(df2)#输出带标签的df2
print(df2.dtypes)#查看数据类型
print(df2.index)#查看队列序号
print(df2.columns)#查看每组数据名称
print(df2.values)#只看df2的值
print (df2.describe())#输出df2数据的总结,如均值等
print(df2.T)#输出翻转后的df2
print(df2.sort_index(axis = 1,ascending = False))#对df2进行排序并输出
print(df2)
print(df2.sort_values(by = 'B'))#对数值数据进行排序输出
结果:
DatetimeIndex(['2016-01-01', '2016-01-02', '2016-01-03', '2016-01-04',
'2016-01-05', '2016-01-06'],
dtype='datetime64[ns]', freq='D')
a b c c
2016-01-01 0.356549 0.411776 0.683232 0.219466
2016-01-02 0.149376 0.947306 0.564166 0.662546
2016-01-03 0.206910 0.021389 0.071939 0.064711
2016-01-04 0.780461 0.594667 0.712817 0.609230
2016-01-05 0.244687 0.384402 0.978531 0.866349
2016-01-06 0.955336 0.261315 0.476315 0.434412
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
A B C D E F
0 1.0 2013-01-02 1.0 3 train foo
1 1.0 2013-01-02 1.0 3 test foo
2 1.0 2013-01-02 1.0 3 train foo
3 1.0 2013-01-02 1.0 3 test foo
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
Int64Index([0, 1, 2, 3], dtype='int64')
Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
[[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'train' 'foo']
[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'foo']
[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'train' 'foo']
[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'foo']]
A C D
count 4.0 4.0 4.0
mean 1.0 1.0 3.0
std 0.0 0.0 0.0
min 1.0 1.0 3.0
25% 1.0 1.0 3.0
50% 1.0 1.0 3.0
75% 1.0 1.0 3.0
max 1.0 1.0 3.0
0 ... 3
A 1 ... 1
B 2013-01-02 00:00:00 ... 2013-01-02 00:00:00
C 1 ... 1
D 3 ... 3
E train ... test
F foo ... foo
[6 rows x 4 columns]
F E D C B A
0 foo train 3 1.0 2013-01-02 1.0
1 foo test 3 1.0 2013-01-02 1.0
2 foo train 3 1.0 2013-01-02 1.0
3 foo test 3 1.0 2013-01-02 1.0
A B C D E F
0 1.0 2013-01-02 1.0 3 train foo
1 1.0 2013-01-02 1.0 3 test foo
2 1.0 2013-01-02 1.0 3 train foo
3 1.0 2013-01-02 1.0 3 test foo
A B C D E F
0 1.0 2013-01-02 1.0 3 train foo
1 1.0 2013-01-02 1.0 3 test foo
2 1.0 2013-01-02 1.0 3 train foo
3 1.0 2013-01-02 1.0 3 test foo3、在pandas中选择数据
import numpy as np
import pandas as pd
dates = pd.date_range('20130101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['a','b','c','d'])
print(df)
#根据标签选择(纯标签筛选)
print(df['a'])#筛选a列
print(df.a)#筛选a列
print(df[0:3])#跨行多选
print(df['20130102':'20130104'])#跨行多选
print(df[0:1])#第一行
print(df.loc['20130102'])#以标签的名义来选择行
print(df.loc[:,['a','b']])#保留所有行的标签,列选a、b两项
print(df.loc['20130102',['a','b']])#保留20130102这一行对应a,b两列的值
#根据位置选择(纯数字筛选)
print(df.iloc[3,1])#第4行第二个数
print(df.iloc[3:5,1:3])#切片选择
print(df.iloc[[1,2,3],1:3])#不连续切片筛选
#综合loc和iloc
print(df.ix[:3,['a','c']])
print(df)
print(df[df.a>8])#只判断a,a中大于8的输出,其他列的数不进行判断,与a对应的位置上的其他列的值输出
结果:
a b c d
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
2013-01-01 0
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
Freq: D, Name: a, dtype: int32
2013-01-01 0
2013-01-02 4
2013-01-03 8
2013-01-04 12
2013-01-05 16
2013-01-06 20
Freq: D, Name: a, dtype: int32
a b c d
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
a b c d
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
a b c d
2013-01-01 0 1 2 3
a 4
b 5
c 6
d 7
Name: 2013-01-02 00:00:00, dtype: int32
a b
2013-01-01 0 1
2013-01-02 4 5
2013-01-03 8 9
2013-01-04 12 13
2013-01-05 16 17
2013-01-06 20 21
a 4
b 5
Name: 2013-01-02 00:00:00, dtype: int32
13
b c
2013-01-04 13 14
2013-01-05 17 18
b c
2013-01-02 5 6
2013-01-03 9 10
2013-01-04 13 14
a c
2013-01-01 0 2
2013-01-02 4 6
2013-01-03 8 10
a b c d
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
a b c d
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
Process finished with exit code 0

















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









