







scipy.io.savemat
首先上代码,用scipy.io.savemat将numpy数组持久化保存到mat文件里:
scipy.io.savemat('/data/weiyuhua/AFClassification/preprocessed_data_new/data_aug_1.mat',
mdict={'trainset': trainset[0:half_l],'traintarget': traintarget[0:half_l], 'trainsetSpec': trainsetSpec[0:half_l]})
但是由于数据太大(trainset的shape是(7000,12,30000),已经将数据减半了还是过大),出现错误提示无法保存到mat中,如果仍要保存为mat,有两个办法:1.进一步切分数据,分成多个mat文件保存; 2. 考虑采用v7.3版本的.mat文件保存(没试过,不知道行不行),可以参考:https://www.cnblogs.com/yymn/p/11285811.html
pickle和joblib
此外,其他方式可以使用pickle和joblib,可以参考:https://redstonewill.blog.youkuaiyun.com/article/details/71156441
如果用pickle,上面的程序可以这样写:
data_path = '/data/weiyuhua/data/Challenge2018/preprocessed_data_new/'
res = {'trainset':trainset, 'traintarget':traintarget,'trainsetSpec':trainsetSpec}
with open(os.path.join(data_path, 'data_aug_train.pkl'), 'wb') as fout:
dill.dump(res, fout)
结果是又出现一个错误:“cannot serialize a bytes object larger than 4 GiB”,意思是是数据超过4G,无法序列化, 查看pickle的文档这样写到:
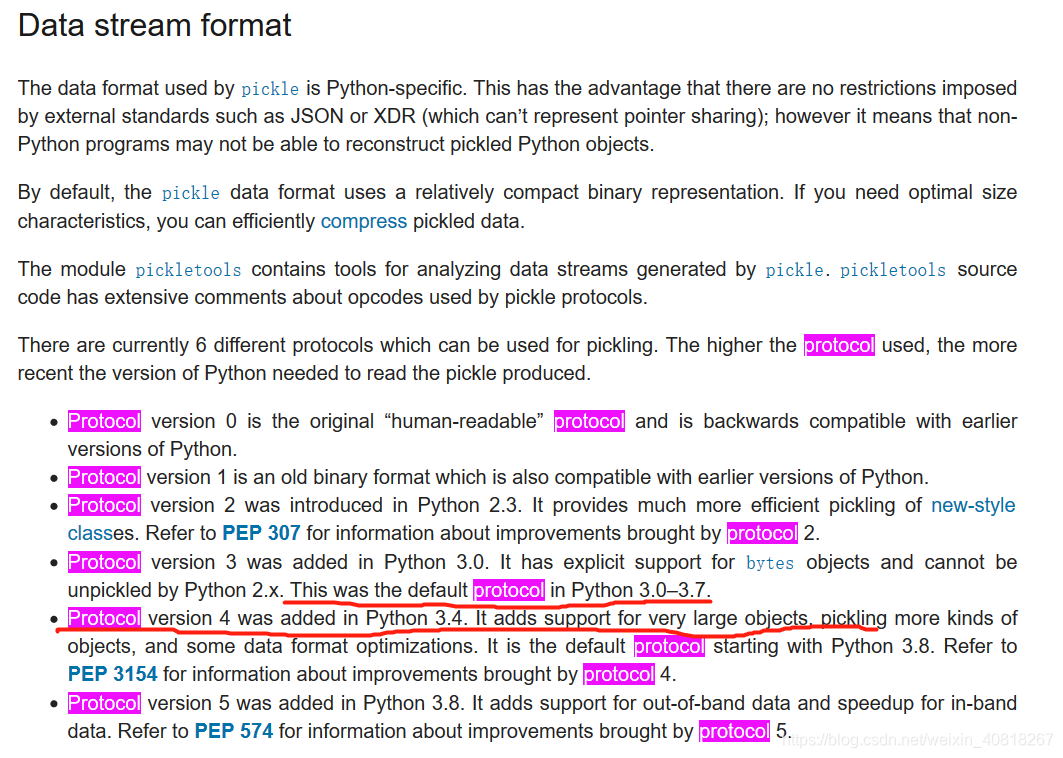 目前有6种不同的协议用于pickling,协议越高,需要的Python版本就越新。
目前有6种不同的协议用于pickling,协议越高,需要的Python版本就越新。
version3 是Python3.0-3.7默认版本,而我的python是3.6,此外,重要的一点是,version4 增加了对非常大的object的支持,可以提取更多类型的对象,以及一些数据格式优化。基于此,如果指定protocol=4,或许就可以保存更大的数据,将代码做以下修改,结果保存成功。
dill.dump(res, fout,protocol=4)
此外,关于joblib,很多blog说:joblib更适合大数据量的模型,且只能往硬盘存储,不能往字符串存储(我没试过,不过应该没问题)。joblib文档:https://joblib.readthedocs.io/en/latest/generated/joblib.dump.html
joblib.dump:


















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









