







 本文探讨了在CloudRA平台中,生产环境与测试环境对于MapReduce任务内存配置的不同需求。在生产环境中,由于主要处理日志解析,1GB的默认内存配置已足够;而在测试环境下,进行TPCx-BB基准测试时,因更复杂的数据处理需求,将内存配置提升至10GB以避免运行错误。文章深入分析了不同场景下内存需求变化的原因。
本文探讨了在CloudRA平台中,生产环境与测试环境对于MapReduce任务内存配置的不同需求。在生产环境中,由于主要处理日志解析,1GB的默认内存配置已足够;而在测试环境下,进行TPCx-BB基准测试时,因更复杂的数据处理需求,将内存配置提升至10GB以避免运行错误。文章深入分析了不同场景下内存需求变化的原因。
诡异问题
生产环境 mr 运行任务 map端和reduce 的运行内存都设置的为0 (此为cloudra 的默认配置)
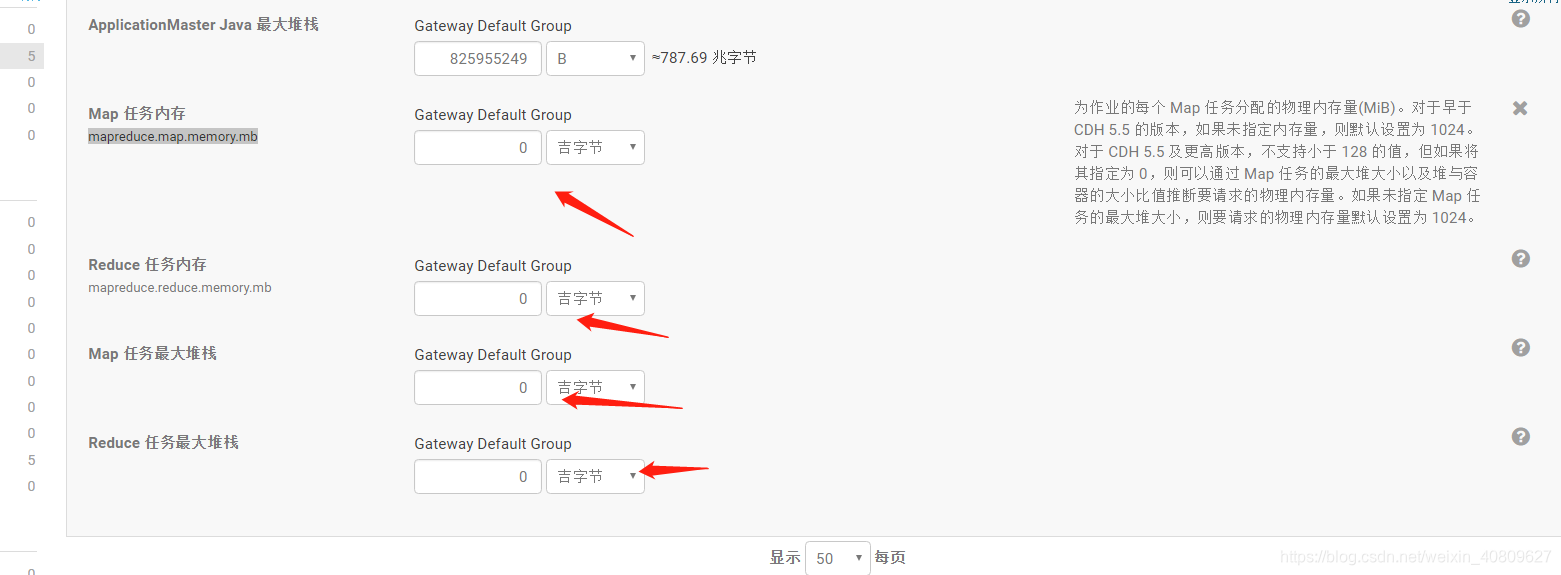
为作业的每个 Map 任务分配的物理内存量(MiB)。对于早于 CDH 5.5 的版本,如果未指定内存量,则默认设置为 1024。对于 CDH 5.5 及更高版本,不支持小于 128 的值,但如果将其指定为 0,则可以通过 Map 任务的最大堆大小以及堆与容器的大小比值推断要请求的物理内存量。如果未指定 Map 任务的最大堆大小,则要请求的物理内存量默认设置为 1024。
根据提示 他会参考 最大堆的 参数(也为0) 所有更加配置得出 其map 端和reduce 端 都取默认值 1G
但是同样的配置 在测试环境报错 143 (既运行内存不够的情况)
修改配置如下 数据成功跑出
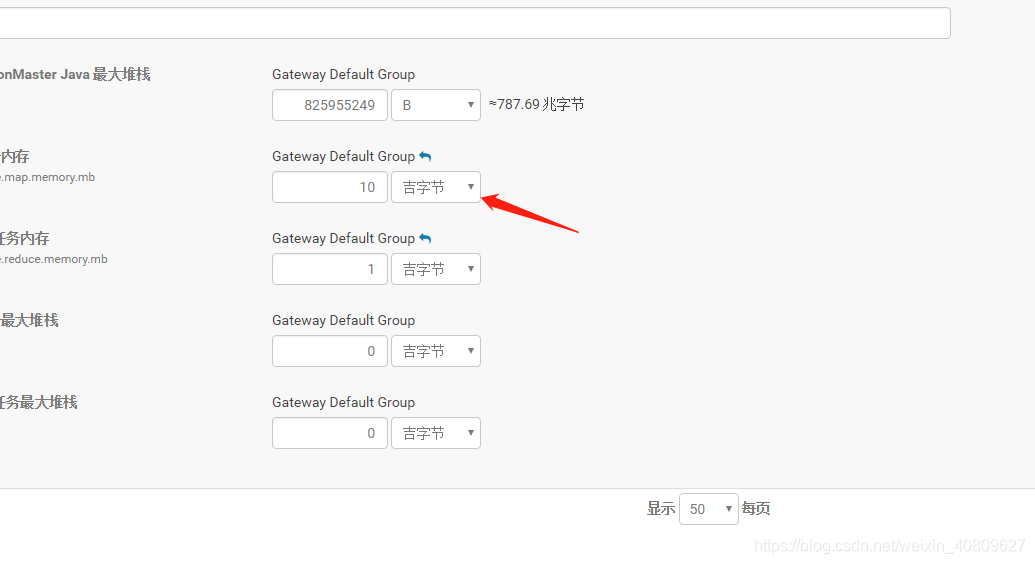
问题推测原因: 可能是线上运行的主要是解析日志需求 1G 已经足够,但是测试环境因运行TPCx-BB 基准测试时所需的mr 程序需要更大的运行内存 所以改成10G
问题注意此配置


















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









