






x-anylabeling教程以及转成ava数据集格式
x-anylabeling打包成exe文件时候遇到的问题
由于我只需要跟踪人,所以改动了 yaml文件 ,删除了car。于是我需要重新打包exe。于是乎遇到了一些问题
1、ImportError: cannot import name dataclass_transform
报错解决方法
pip install typing_extensions==4.4.0
然后再利用 命令行 进行编译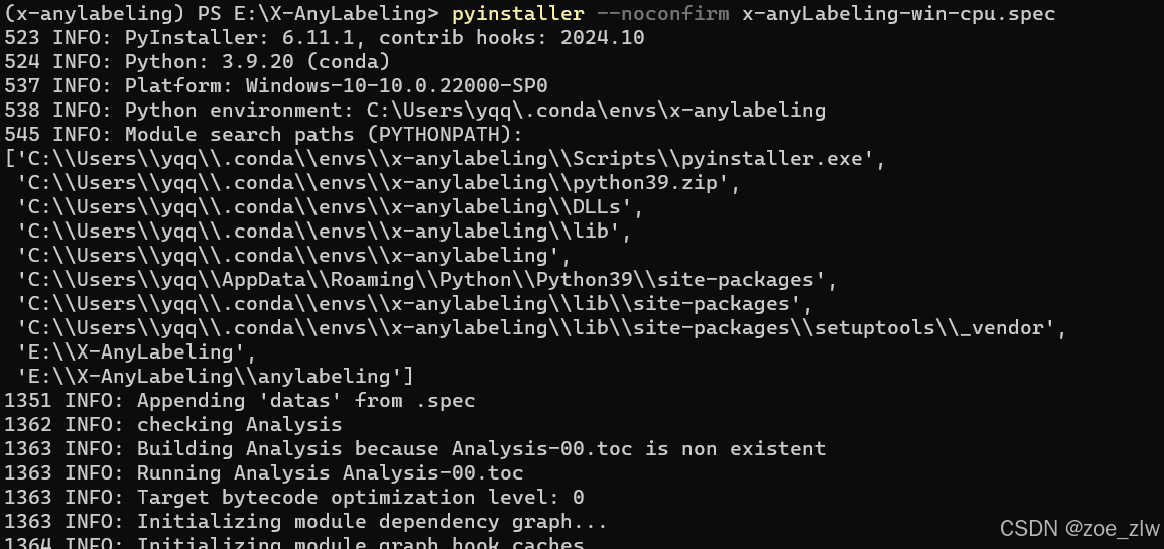
编译完成之后,点击exe

发现加载模型时候发生闪退,debug = true console = true 查看哪里报错
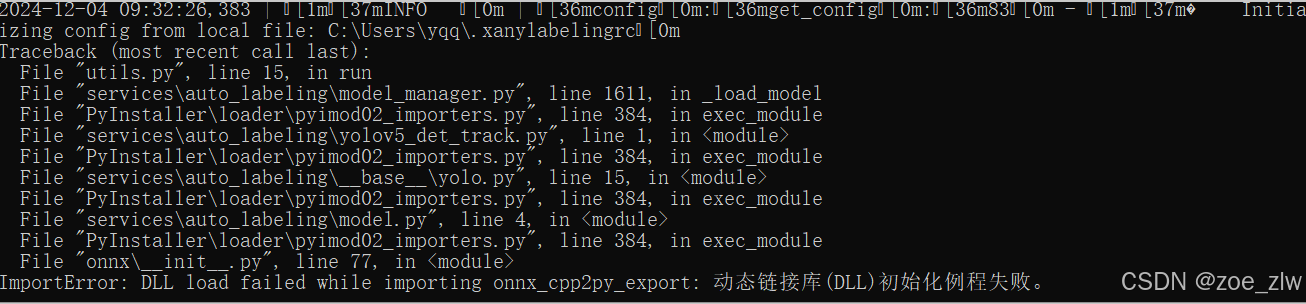
上网搜索 发现是onnx版本不对
应该是onnx = 0.16.1
重新编译
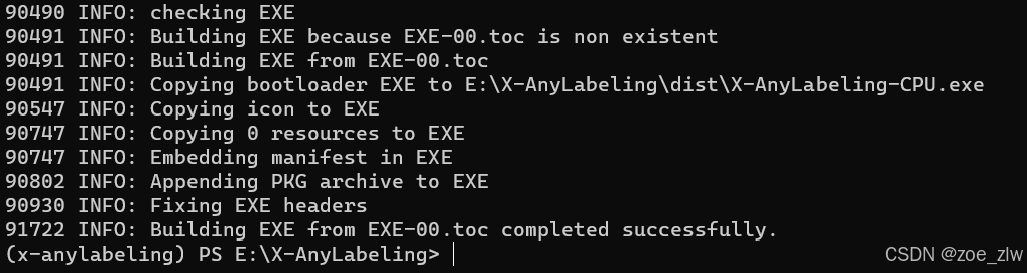
解决问题!!

截取视频和frames
先点击 cut_frames.sh 再点击cut_frame.sh
具体看ava数据集处理流程
x_anylabeling使用说明
0、前期设置
键盘ctrl+R打开命令行,输入%homepath%
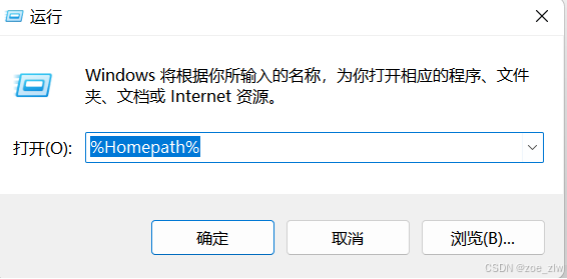
将压缩包粘贴到改目录并解压

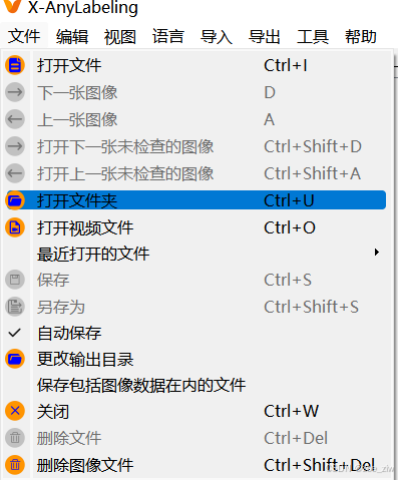
1、打开自动标注exe软件
-
点击文件,勾选自动保存,打开文件夹 .\choose_frames_middle_bing(qian)\falldown0001(2、3等)
-
点击导入,选择attributes.json
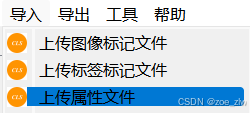
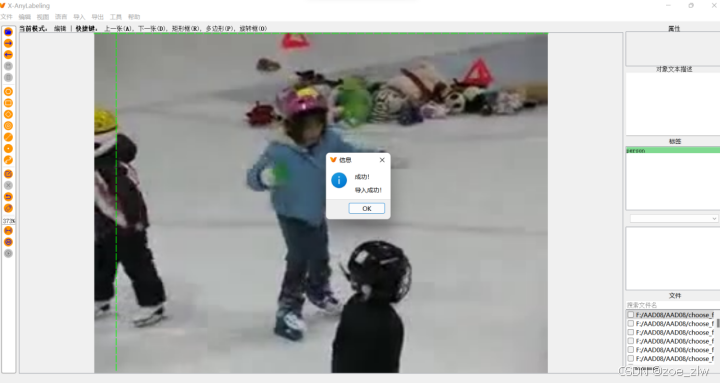
导入成功
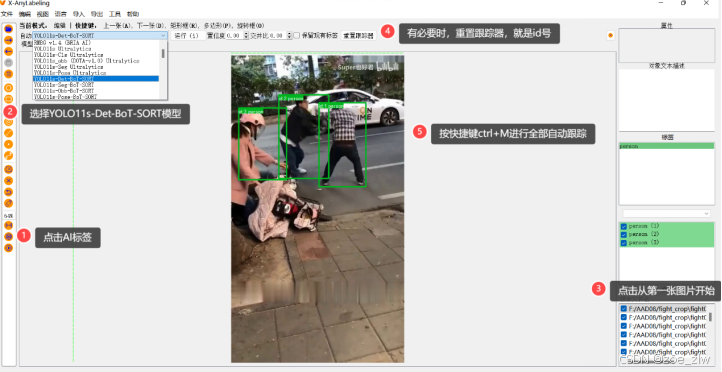
2、自动标注,选择AI按钮选择模型进行自动目标跟踪 具体步骤如图所示:
3、手动修改id号和调整框的大小以及手动对行为属性的标注
案例:
首先进行 框的删除和添加,如图为具体步骤:
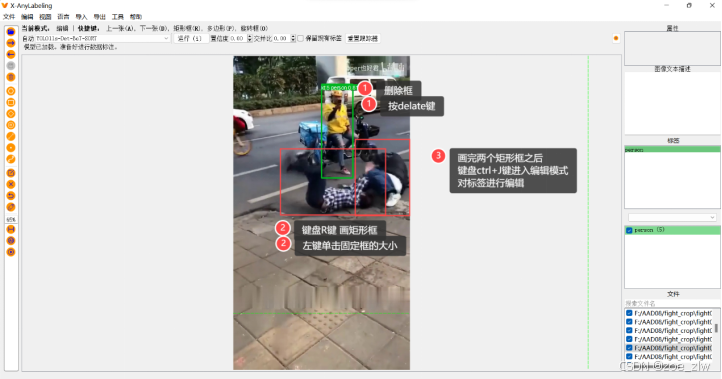
注意:因为我们要通过肢体信息和互动信息来推理人的行为,所以框尽量要覆盖到整个人。但是过度遮挡的(小于人体1/3的),不予标注。
调整框的大小
其次我们进行 标签的属性修改,如下图为具体步骤
注意:编辑属性标签时,箭头在框里面时利用滚轮上下滑动,就是选择yes和no。箭头放在外面就是属性栏上下滑动(把属性栏的大小改动一下)
因为这里面两个人在争斗 fight是yes,其他都是no
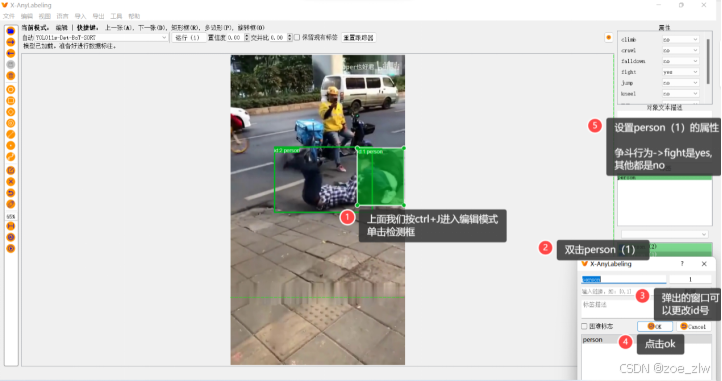
修改完成一张图片之后 按D键下一张图片(A键上一张图片), 由于设置了自动保存,所以按下一张图片会自动保存。
D:得到json文件
转成ava格式
下回分解

















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









