






项目场景:
已经是第二次处理ava数据集,希望可以记录自己踩过的坑。 也希望自己之后可以简化一些步骤
windows和linux转化问题
路径问题
将所有路径的‘/’改成‘\\’
no module “numpy_core”
pkl的windows和linux编码处理的结果不同
教训:都在linux里面mmaction的环境中处理数据集最好了,避免很多代码修改问题。
开始帧和结束帧处理问题
开始帧和结束帧在ava_dataset.py中是固定的从900到1800.所有的视频都要从900开始取得固定的900秒而我的行为太小众了,在B站找的只有30s
最后想的方法是把这些视频都拼接起来,那分辨率一般都一样才行,不能一整个视频 忽大忽小,横竖不一吧。
那就又有好几个问题
首先视频有横屏竖屏 还有分辨率也有不同 代表我的标签不能够完全对应,万一分辨率变化了。
解决:竖屏的三个视频可以删除 ,那横屏的呢?
从网上四处找寻的小众行为就是这么的简短而多种多样。下回提前处理视频,大小相等,长度相等。
所以按照原来的分辨率合成一个视频,不转变大小和分辨率。但是moivepy是合成了之后两边还都是黑边,还是改了分辨率,按照最大的来了。
拼接成长视频:
from moviepy.editor import VideoFileClip, concatenate_videoclips
# 视频文件列表
video_files = ['video1.mp4', 'video2.mp4', 'video3.mp4'] # 替换为你的视频文件路径
# 加载视频文件
clips = [VideoFileClip(video) for video in video_files]
# 合并视频
final_clip = concatenate_videoclips(clips, method="compose")
# 输出视频文件
final_clip.write_videofile("final_video.mp4", codec="libx264") # 可以选择合适的codec
https://github.com/open-mmlab/mmaction2/issues/1279
这个改法没用,

解决方案
发现也不一定要从和视频开始,直接把图片帧合成到一起也可以呢。
但提问有个问题,前后两帧的视频可能丝毫不搭嘎,那怎么才能让机器执行中间帧数和前后30帧相关联的运动等信息的结合学习呢?
反驳 新的视频是新的ID号,就没有前后学习这一个说法了
注意事项
尽量先找长视频
少样本找不到,再去拼接。
样本比较少,学习率往下降一点。

修改代码的处理方式(未成功)
应该还是loading.py或者ava_dataset.py的问题
shot_info(0,27000)
标签是这个
timestamp start 900
timestamp end 1800
https://github.com/open-mmlab/mmaction2/issues/1598
这个链接有点理解 了 但是还是不知道该怎么做
感觉还是要改
ava_dataset.py里面的东西
改了ava_dataset.py
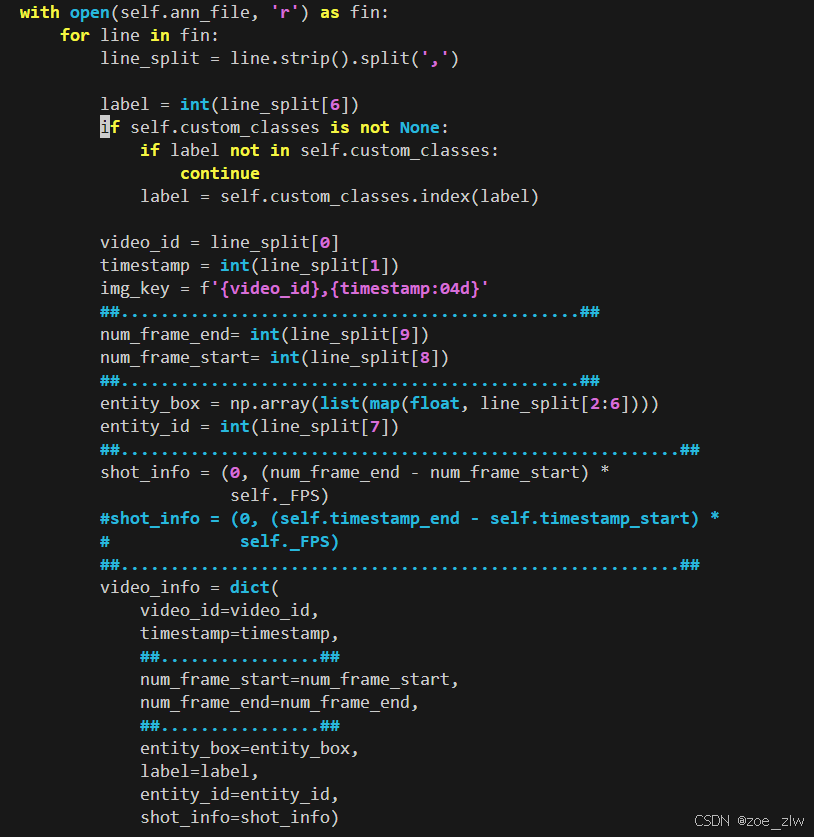
改了loading.py
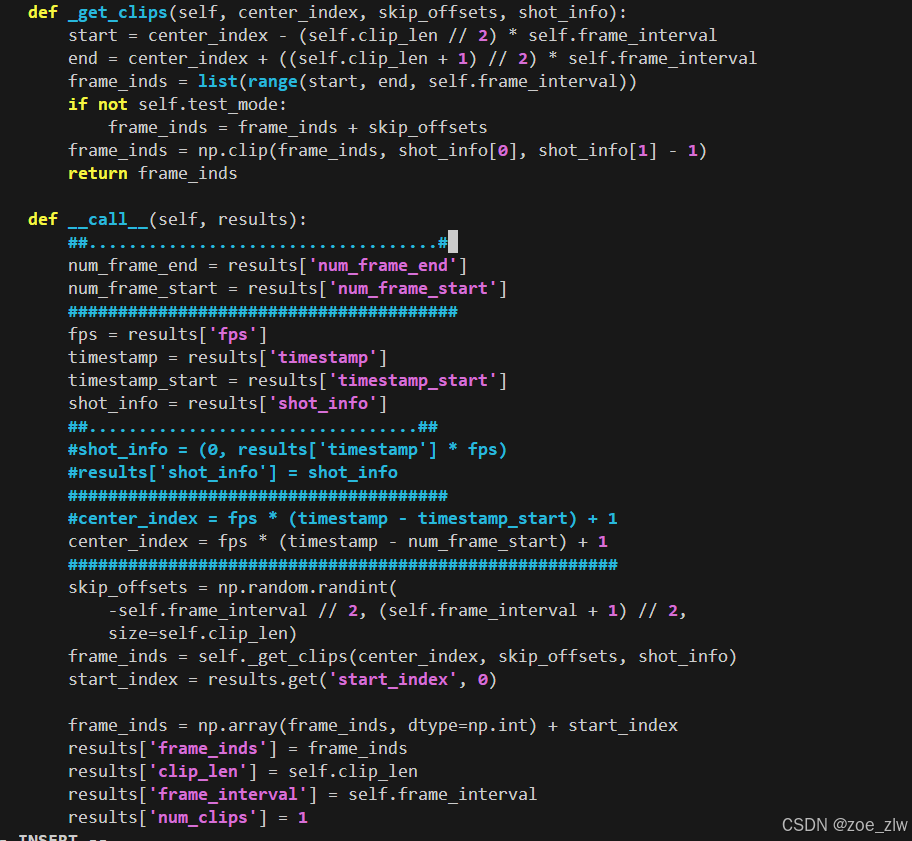
改了,但是没用
File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/registry.py", line 72, in build_from_cfg
raise type(e)(f'{obj_cls.__name__}: {e}')
IndexError: AVADataset: list index out of range
解决方案:
最后还是用了苯笨的方法
把图片帧合到一起,从img_00001.jpg到img_27000.jpg的15分钟的视频。
ava.csv从902秒到1798秒的标签。
pkl从crawl_merge,0902:到crawl_merge,1798:。
后续
将不同视频 长宽不一的视频合在一起还是不行的,因为合在一个文件夹里面,代码就认为是一个视频,就会按照 第一帧的图片去按比例缩放,这个会导致我的标签框和图片不能对应,那训练出来的效果更差了。行不通。
最后还是只用了30个30秒的视频,没有强制加在ava数据集里面。

















 1361
1361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









