









 该博客介绍了如何利用Python中的LightGBM库进行建模和调参。首先,通过减少内存使用量的函数优化数据,然后使用lightgbm进行建模,包括数据划分、模型训练、自定义f1_score评价指标以及k折交叉验证。接着,展示了使用GridSearchCV进行网格搜索调参的过程,以找到最佳模型参数。整个流程详尽地展示了LightGBM在多分类问题中的应用及其性能提升优势。
该博客介绍了如何利用Python中的LightGBM库进行建模和调参。首先,通过减少内存使用量的函数优化数据,然后使用lightgbm进行建模,包括数据划分、模型训练、自定义f1_score评价指标以及k折交叉验证。接着,展示了使用GridSearchCV进行网格搜索调参的过程,以找到最佳模型参数。整个流程详尽地展示了LightGBM在多分类问题中的应用及其性能提升优势。
今天,我们就在这里进行建模以及调参
首先一样的,我们先导入库进来
import pandas as pd
import numpy as np
from sklearn.metrics import f1_score
import os
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
因为数据比较大,所以占用内存比较多,因此,我们就调整一下数据类型,来帮助我们减少数据所占用的内存空间。以下是减少内存的函数。
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
接下来就是读取数据了,然后再做一些简单的预处理。
data = pd.read_csv('../dataset/train.csv')
data_list = []
for items in data.values:
data_list.append([items[0]] + [float(i) for i in items[1].split(',')] + [items[2]])
data = pd.DataFrame(np.array(data_list))
data.columns = ['id'] + ['s_'+str(i) for i in range(len(data_list[0])-2)] + ['label']
data = reduce_mem_usage(data)
可以看到

这里我们使用lightgbm进行建模。
LightGBM
LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架。可用于排序,分类,回归以及很多其他的机器学习任务中。
在竞赛当中,除了XGBoost还有LightGBM,LightGBM在不降低准确率的前提下,速度提升了10倍左右,占用内存下降了3倍左右。
这里对比一下XGBoost和LightGBM:

from sklearn.model_selection import train_test_split
import lightgbm as lgb
# 数据集划分
X_train_split, X_val, y_train_split, y_val = train_test_split(X_train, y_train, test_size=0.2)
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
params = {
"learning_rate": 0.1,
"boosting": 'gbdt',
"lambda_l2": 0.1,
"max_depth": -1,
"num_leaves": 128,
"bagging_fraction": 0.8,
"feature_fraction": 0.8,
"metric": None,
"objective": "multiclass",
"num_class": 4,
"nthread": 10,
"verbose": -1,
}
"""使用训练集数据进行模型训练"""
model = lgb.train(params,
train_set=train_matrix,
valid_sets=valid_matrix,
num_boost_round=2000,
verbose_eval=50,
early_stopping_rounds=200,
feval=f1_score_vali)
其中训练的参数代表意义:

训练后的结果可以看到:
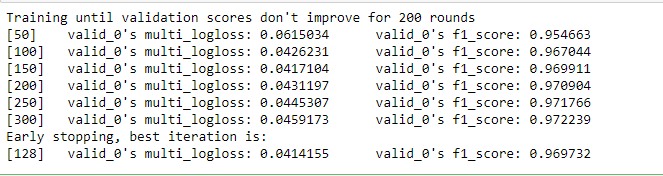
因为树模型中没有f1-score评价指标,所以需要自定义评价指标,在模型迭代中返回验证集f1-score变化情况。
def f1_score_vali(preds, data_vali):
labels = data_vali.get_label()
preds = np.argmax(preds.reshape(4, -1), axis=0)
score_vali = f1_score(y_true=labels, y_pred=preds, average='macro')
return 'f1_score', score_vali, True
训练完了之后就对验证集进行验证准确率了。
val_pre_lgb = model.predict(X_val, num_iteration=model.best_iteration)
preds = np.argmax(val_pre_lgb, axis=1)
score = f1_score(y_true=y_val, y_pred=preds, average='macro')
print('未调参前lightgbm单模型在验证集上的f1:{}'.format(score))

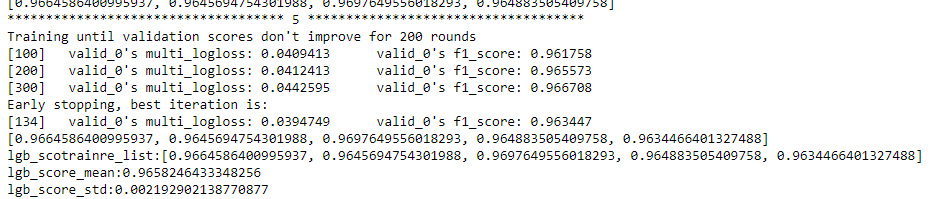
更进一步的,使用k折交叉验证进行模型性能评估,我们这里指定k为5,使用lightgbm 5折交叉验证进行建模预测
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(X_train, y_train)):
print('************************************ {} ************************************'.format(str(i+1)))
X_train_split, y_train_split, X_val, y_val = X_train.iloc[train_index], y_train[train_index], X_train.iloc[valid_index], y_train[valid_index]
train_matrix = lgb.Dataset(X_train_split, label=y_train_split)
valid_matrix = lgb.Dataset(X_val, label=y_val)
params = {
"learning_rate": 0.1,
"boosting": 'gbdt',
"lambda_l2": 0.1,
"max_depth": -1,
"num_leaves": 128,
"bagging_fraction": 0.8,
"feature_fraction": 0.8,
"metric": None,
"objective": "multiclass",
"num_class": 4,
"nthread": 10,
"verbose": -1,
}
model = lgb.train(params,
train_set=train_matrix,
valid_sets=valid_matrix,
num_boost_round=2000,
verbose_eval=100,
early_stopping_rounds=200,
feval=f1_score_vali)
val_pred = model.predict(X_val, num_iteration=model.best_iteration)
val_pred = np.argmax(val_pred, axis=1)
cv_scores.append(f1_score(y_true=y_val, y_pred=val_pred, average='macro'))
print(cv_scores)
print("lgb_scotrainre_list:{}".format(cv_scores))
print("lgb_score_mean:{}".format(np.mean(cv_scores)))
print("lgb_score_std:{}".format(np.std(cv_scores)))
然后对于调参,我们经常使用到的就是网格搜索。
sklearn 提供GridSearchCV用于进行网格搜索,只需要把模型的参数输进去,就能给出最优化的结果和参数。相比起贪心调参,网格搜索的结果会更优,但是网格搜索只适合于小数据集,一旦数据的量级上去了,很难得出结果。
同样以Lightgbm算法为例,进行网格搜索调参,通过网格搜索确定最优参数
from sklearn.model_selection import GridSearchCV
def get_best_cv_params(learning_rate=0.1, n_estimators=581, num_leaves=31, max_depth=-1, bagging_fraction=1.0,
feature_fraction=1.0, bagging_freq=0, min_data_in_leaf=20, min_child_weight=0.001,
min_split_gain=0, reg_lambda=0, reg_alpha=0, param_grid=None):
# 设置5折交叉验证
cv_fold = KFold(n_splits=5, shuffle=True, random_state=2021)
model_lgb = lgb.LGBMClassifier(learning_rate=learning_rate,
n_estimators=n_estimators,
num_leaves=num_leaves,
max_depth=max_depth,
bagging_fraction=bagging_fraction,
feature_fraction=feature_fraction,
bagging_freq=bagging_freq,
min_data_in_leaf=min_data_in_leaf,
min_child_weight=min_child_weight,
min_split_gain=min_split_gain,
reg_lambda=reg_lambda,
reg_alpha=reg_alpha,
n_jobs= 8
)
f1 = make_scorer(f1_score, average='micro')
grid_search = GridSearchCV(estimator=model_lgb,
cv=cv_fold,
param_grid=param_grid,
scoring=f1
)
grid_search.fit(X_train, y_train)
print('模型当前最优参数为:{}'.format(grid_search.best_params_))
print('模型当前最优得分为:{}'.format(grid_search.best_score_))
最后得出比较合适的参数之后,就可以进行确认调优了:
final_params = {
'boosting_type': 'gbdt',
'learning_rate': 0.01,
'num_leaves': 29,
'max_depth': 7,
'objective': 'multiclass',
'num_class': 4,
'min_data_in_leaf':45,
'min_child_weight':0.001,
'bagging_fraction': 0.9,
'feature_fraction': 0.9,
'bagging_freq': 40,
'min_split_gain': 0,
'reg_lambda':0,
'reg_alpha':0,
'nthread': 6
}
cv_result = lgb.cv(train_set=lgb_train,
early_stopping_rounds=20,
num_boost_round=5000,
nfold=5,
stratified=True,
shuffle=True,
params=final_params,
feval=f1_score_vali,
seed=0,
)
在实际调整过程中,我们可先设置一个较大的学习率比如0.1,然后通过cv函数进行树个数的确定之后,就可以进行参数的调整优化。
然后确定完其他参数之后,针对最优的参数设置一个较小的学习率,比如0.05或者0.01,同样通过cv函数确定树的个数,确定最终的参数。

















 6
6

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









