






 文章探讨了在步态识别中,如何通过融合局部和全局特征,以及设计基于掩码的策略来增强特征表示的鲁棒性。作者提出局部时间聚合(LTA)替代空间池化,减少冗余信息并保持空间细节。实验结果显示,动态掩码策略优于固定策略,且方法对丢弃率不敏感,展示了在复杂场景下的优越性能。
文章探讨了在步态识别中,如何通过融合局部和全局特征,以及设计基于掩码的策略来增强特征表示的鲁棒性。作者提出局部时间聚合(LTA)替代空间池化,减少冗余信息并保持空间细节。实验结果显示,动态掩码策略优于固定策略,且方法对丢弃率不敏感,展示了在复杂场景下的优越性能。
2022还在arxiv
摘要、引言
问题一
当时的模型要么全局要么局部,于是本文首次融合
问题二
并且局部的分区策略有限-》设计基于掩码的分区策略随机生成成对的互补掩码来遮挡步态序列(相当于给LFR提供有数据增强的信息吧)
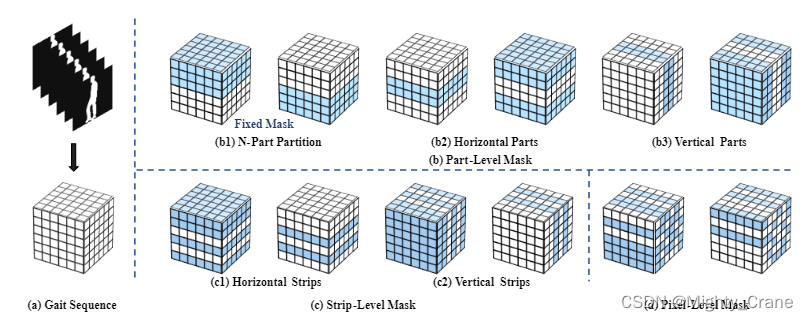
掩码大致分为上图三种:
b表示擦除/保留几大块
c表示擦除/保留几条线
d表示擦除/保留几各点
问题三
当时的sota只在特征提取阶段采用空间池化层对特征图的空间分辨率进行下采样。尽管如此,它们忽略了时间分辨率对最终识别性能的影响。直观地说,步态序列的相邻帧是相似的,因此包含许多冗余信息
↓
提出了局部时间聚合(LTA)来代替空间池化层。具体来说,所提出的 LTA 可以通过聚合局部时间信息来减少冗余信息。同时,去除空间池化层可以保持更大的空间分辨率,其中包含更多的姿态细节
(这一条没有算到贡献里面)
相关工作
基线
提到说基于模型的方法局限性在于:
它们通常依赖于从不同角度收集的几个图像来模拟有效的人体运动。然而,在现实场景中很难捕捉到几个多视角步态图像。
并且把基于模型的方法拆分成基于模型的方法(好像是特指根据姿态、轮廓。骨架等近似建模人体的方法)和基于姿态的方法(特指直接利用考察二三维姿态的方法,明明这类举例的论文名都自称是基于模型的方法了。。。)。基于姿态的方法局限性在于无法应用于真实数据
基于轮廓的方法又细分三类:基于模式的方法、基于集合的方法和基于视频的方法
基于模式的方法如GEI,聚合序列的所有时间信息
基于集合的方法如gaitset,将步态序列作为无序集
基于视频的方法是3D CNN+LSTM结合时空信息-》因此本文也是类似做法
GLFR
提取GFR主流做法是:使用2D CNN直接从每一帧中提取空间特征。然后使用集合池 (SP) 和水平金字塔映射 (HPM) 操作来生成稳健的特征表示。缺点,随着网络加深,感受野变大,局部细节丢失
LFR的局限性在于各分区之间关联性忽视了;分区策略自上而下(top-to-down),丢失其他区域细节(这个自上而下其实应该是指b1那种草率的上下分区做法)
方法
LTA
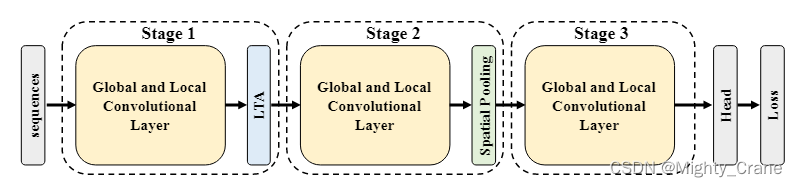
重复三个stage,不过第一个用LTA聚合时空池化,第二个单纯空域池化,第三个没有池化(这里还没说为啥这样编排,甚至在下文中还有stage2用LAT这样疑似笔误的说法)
采用LTA是因为仅下采样空间的话,冗余的时域信息炸内存
GLCL
GFR就是一个3d卷积直接提取特征
LFR则是考虑到前人只是分几个特殊的块无法充分利用步态特征图,所以设计了生成互补掩码作用到输入上(记得代码里好像是直接把特征图切条来着)
(这论文好些数学表达式操)
识别头
时间特征映射。由于在测试阶段输入步态序列的长度不同,引入了一个最大池化层来整合步态序列的所有时间信息(哦对训练时通过循环补齐了步态序列,应用测试时倒是没有,直接该多长就多长)
空间特征映射。为了保留更多的空间信息,以前的工作通常首先将特征图分割成多个水平条带,然后使用平均池化和最大池化[10]、[14]聚合每个条带的垂直信息。
因此,我们进一步引入广义均值池(GeM)[43]自适应地聚合特征图的垂直信息
(结合之前看metagait对这三种池化的分析,GeM其实就是个中间状态)
实验
CASIA
因为聚合了局部和全局,所以在CL、BG这样的复杂场景效果更佳
与先前固定掩码的工作(应该是Gait recognition via effective global-local feature representation and local temporal aggregation这一篇,readpaper上还有收录早期版本Learning Effective Representations from Global and Local Features for Cross-View Gait Recognition)对比更好,这是因为基于掩码的策略可以更好地利用局部姿态细节,从而提高特征表示的鲁棒性
OUMVLP
0° 和 180°角度上效果改善,因为聚合全局和局部特征可以更好地利用来自有限视图的局部姿态细节
GREW 和 Gait3D
由于基于局部的方法更关注局部姿态细节,因此它们更有可能过度拟合这些噪声。然而,我们的方法可以自适应地学习和融合全局视觉信息和局部姿态细节。因此,它可以产生更具辨别力的特征
消融实验
GLCL
比单纯局部或全局效果好
局部的掩码策略
优于固定掩码策略 0.6%。这是因为所提出的掩码策略生成各种局部特征图来训练局部特征提取器。因此,局部特征提取器可以有效地利用特征图的局部信息。另一方面,我们还观察到,在垂直轴上使用带条级掩码的方法比其他掩码策略取得了更好的性能。因此,我们最终选择它来实现我们的模型。
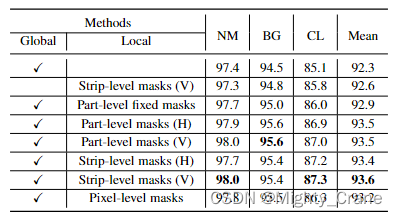
与其说是消融实验不如说是选型实验,还是个部分糅合,后五行是前面分析过的五种掩码策略(水平、竖直的条带、部分、像素)
第三行其实是固定掩码和新设计掩码的对比(这里为啥只有part级的掩码做这样的对比)
前两行是只有全局或局部的对比(为什么只对比strip级的仅局部情况)总之表里考虑的不够全面啊
掩码率
可以观察到,不同下降比的掩模策略的精度曲线是稳定的。这意味着我们的方法对丢弃率的设置不敏感。这是因为所提出的三种掩码策略生成成对的互补掩码来遮挡步态特征图。然后,我们提取每个遮挡特征图的局部特征。之后,将被遮挡的特征图融合到特征图中。融合后的地图不会丢失任何区域的信息。因此,生成的特征表示对具有不同丢弃率的掩码策略具有鲁棒性。因此,我们不需要仔细设置不同数据集上的丢弃率。
也就是说其实掩码是有形成互补的,所以不需要怎么考虑掩码面积比例什么的
空域池化
解释说GeM就已经是自适应组合最大、平均池化了,而不像其他人那样简单求和(表现在那个学习参数p上吧)
LTA
解释了为什么两个stage分别用LTA和SP,因为要综合时空性能(具体谁先谁后倒是没有分析,甚至正文和图示还不太一样)
————————
顺便再看看Gait Recognition via Effective Global-Local Feature Representation and Local Temporal Aggregation
2021年CVPR
这时的GLCL叫做GLFE,这时提出的理由是解决3d卷积无法应对训练序列可能变长的问题(但是之前用过gaitset应该也是支持循环补齐的吧)
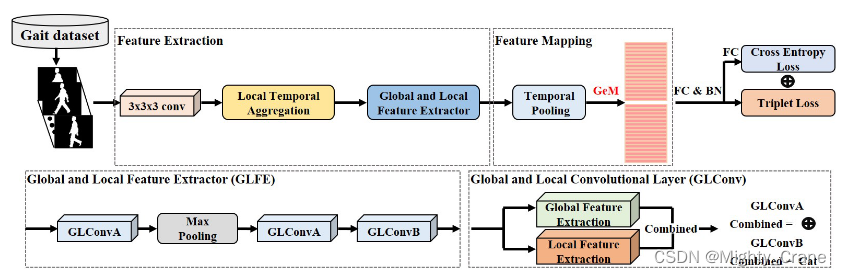
(感觉这个图比gaitgl上的好)
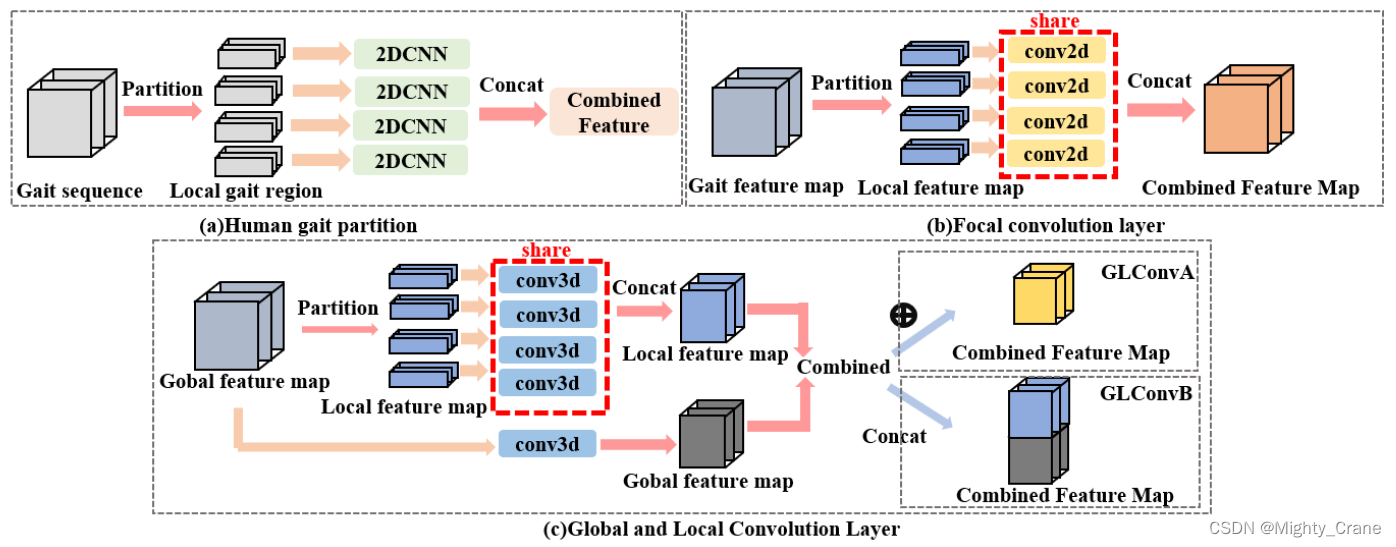
(这里的分区局部就比较符合代码)
实验部分提到CASIA中有三种尺度?

















 3040
3040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









