






 本文提出CPMF,一种结合手工制作的PCD描述符的局部几何信息和预训练二维网络的全局语义信息的新型方法,以改善点云异常检测性能。通过将三维和二维模态特征融合,弥补了现有方法在语义捕捉上的不足。
本文提出CPMF,一种结合手工制作的PCD描述符的局部几何信息和预训练二维网络的全局语义信息的新型方法,以改善点云异常检测性能。通过将三维和二维模态特征融合,弥补了现有方法在语义捕捉上的不足。
摘要、引言
点云(PCD)异常检测逐渐成为一个很有前途的研究领域(笑了)
提出了互补伪多模态特征(CPMF),该特征利用手工制作的PCD描述符在三维模态中包含局部几何信息
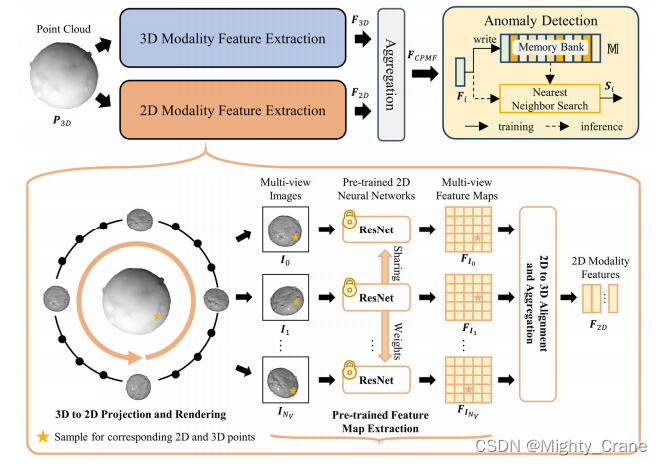
(2023还在搞手工制作描述符。。。而且还是sota。。。),并利用预先训练好的二维神经网络在生成的伪二维模态中包含全局语义信息。对于全局语义提取,CPMF将原点PCD投影到一个包含多视图图像的伪二维模态中。这些图像被传送到预先训练的二维神经网络,进行信息的二维模态特征提取。将三维和二维模态特征进行聚合,获得PCD异常检测的CPMF。
本研究主要研究PCD异常检测,并试图通过协同统一PCD的局部几何和全局语义线索来满足实际的性能要求。
(也就是说整合局部和整体?虽然对于点云这种可以理解为拓扑的结构,整体思路也挺直观,但是别人都没提出过这种想法,就有种没事找事的感觉)
BTF [3]揭示了特征描述性在PCD异常检测中的重要性。与预期相反,结果表明,经典的手工制作的PCD描述符优于基于学习的预训练特征。
(牛牛牛)
BTF将这种现象归因于目标对象和预训练的数据集之间的域分布差距(那还是预训练的泛化性能差啊,迁移后不好微调吗),这导致预训练的PCD特征的转移能力较低。然而,尽管经典的手工制作的特性取得了令人印象深刻的性能,但它们仅限于使用本地结构信息,并且无法访问全局语义上下文。由于全局语义上下文在检测语义异常时至关重要,因此[9]将其与手工特征的几何建模能力相结合可能会带来改进。
本研究提出了一种统一的PCD表示方法,即互补伪多模态特征(CPMF),以充分利用PCD中的局部几何结构和全局语义上下文。建立在手工制作的PCD描述符的基础上,所提出的CPMF进一步利用生成的伪二维模态中的描述性预训练的二维神经网络来丰富PCD描述符的语义内容
(我的理解是:先把手工3d描述符生成伪的rgb特征,然后用预训练的rgb编码器去学习它?那也就是说前面BTF指出问题也是二维预训练描述pc效果差吗?那我觉得是理所当然的吧?前一篇的3DSR好歹是认为不能直接用rgb去学习深度图,但是这里这样说感觉还是有点逆天)。虽然现有的方法[1]-[3]只用于特征提取的三维模态,但所提出的方法通过生成的伪多模态数据捕获互补的结构和语义线索,提高了PCD异常检测性能,如图1所示。(认为前人的不足在于只考虑三维特征,而没有二维特征,那还是落脚于双模态呗)
把pc转换为包含多视图二维图像的伪2D模态(那这种降维我还是能够接受的吧,不过3d本身的属性感觉还是欠缺了吧,相当于完完全全把2d视作主模态,然后把3d数据投影到2d空间咯)
提取的3D和二维模态特征具有高度的互补性,因为1)3D手工制作的特征擅长描述局部结构,但不能利用全局语义信息[3],[7]。
(所以2d的更擅长描述全局吗?下采样?如果这样来理解全局的话倒也确实比3d更方便了)2)二维预训练的网络包含了来自大规模图像数据集的深刻知识,可以捕获语义属性,但不能精确地表示局部结构(这么说有点过分吧,不都是把CNN看做局部描述嘛,当和GCN或者transformer等在一块说的时候。不过基于gaitgl里那种focal思想来说,确实还是比较弱局部的),[5],[15]。因此,CPMF开发了一个聚合模块来融合二维和三维模态特征,并获得包含全局语义和局部几何信息的特征。
相关工作
虽然手工制作的特性实现了相当的异常检测性能,但由于其启发式设计,它们很少能捕获PCD数据中的语义信息。由于语义信息对于异常检测至关重要,本研究的目标是补充语义的缺失,生成更好的PCD表示。
(所以要结合2d是吧)
大致上明白了,还是看代码吧

















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









