






为了里哦阿姐模型的泛化能力,我们需要用某个指标来衡量,有了一个指标就可以对比不同的模型,从而知道那个模型相对较好,哪个相对较差,同通过这个指标进一步调参逐步优化我们的模型
1.准确率
准确率是预测正确的结果占总样本的百分比。
准确率 = (TP+TN)/(TP+TN+FP+FN)
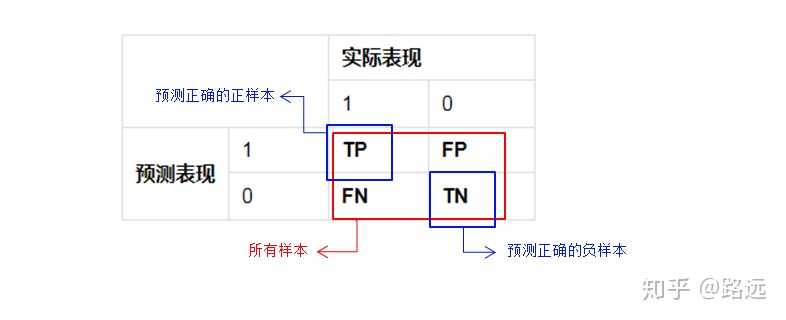
由于样本不平衡的问题,导致了高准确率结果含有很大的水分,即如果样本不平衡,准确率就会失效。
2.精准率(precision)
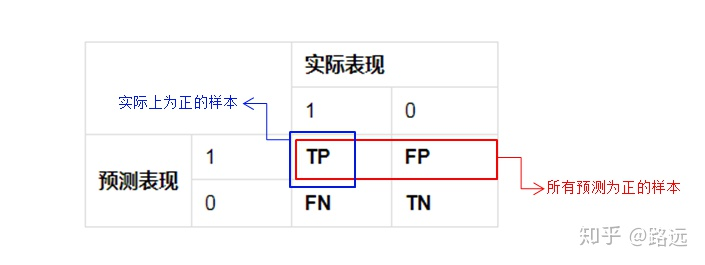
精准率也叫查准率,是针对预测结果而言,是在所有被预测为证的样本中实际为正样本的概率
精准率 = TP / (TP+FP)
3.召回率(Recall)
也叫查全率,他是针对原样本而言,是在实际为正的样本中被预测为正样本的概率。
召回率 = TP /(TP+FN)

召回率越高,代表世界坏用户被预测出来的概率越高,哪网贷违约率为例,相对好用户,我们更关心坏用户,如果过多的将坏用户当成好用户,就会损失严重。
4.F1分数
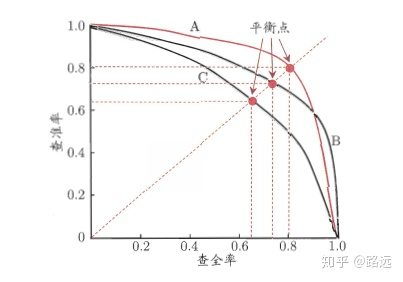
F1分数考虑了查准率和查全率,让两者同时达到最高,取一个平衡
F1 = 2×查准率×查全率 / (查准率 + 查全率)
逻辑回归输出是一个0到1之间的概率数字,如果需要判断用户好坏,就必须定义一个阈值,即阈值为0.5的情况下,可以得到相应的查准率和查全率,若要找到一个最合适的阈值满足要求,我们就需要便利0到1之间的所有阈值,而每一个阈值下都对应着一对查准率和查全率,从而得到我们这条曲线。

















 989
989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









