









 本文介绍了PyTorch中的detach()函数,用于在训练过程中切断部分网络分支的反向传播,使得这部分变量不再计算梯度。文章通过实例解释了detach()的作用,指出即使detach后的tensor与原始tensor共享内存,但反向传播时会停止在detach点,不影响主网络的梯度计算。
本文介绍了PyTorch中的detach()函数,用于在训练过程中切断部分网络分支的反向传播,使得这部分变量不再计算梯度。文章通过实例解释了detach()的作用,指出即使detach后的tensor与原始tensor共享内存,但反向传播时会停止在detach点,不影响主网络的梯度计算。
前言:当我们再训练网络的时候可能希望保持一部分的网络参数不变,只对其中一部分的参数进行调整;或者值训练部分分支网络,并不让其梯度对主网络的梯度造成影响,这时候我们就需要使用detach()函数来切断一些分支的反向传播
一、说明
返回一个新的tensor,从当前计算图中分离下来的,但是仍指向原变量的存放位置,不同之处只是requires_grad为false,得到的这个tensor永远不需要计算其梯度,不具有grad。
即使之后重新将它的requires_grad置为true,它也不会具有梯度grad
这样我们就会继续使用这个新的tensor进行计算,后面当我们进行反向传播时,到该调用detach()的tensor就会停止,不能再继续向前进行传播
注意:
使用detach返回的tensor和原始的tensor共同一个内存,即一个修改另一个也会跟着改变。
二、实例
x=T.ones(10, requires_grad=True)
y=x**2
z=x**3
r=(y+z).sum()
make_dot(r).render("attached", format="png")这个代码的graph应该是如下所示:

所以,反向传播的结果应该是5,因为求导是2+3:
>>> r.backward()
>>> x.grad
tensor([5., 5., 5., 5., 5., 5., 5., 5., 5., 5.])接下来,我们对x分量detach,然后进行反向传播的操作:
y=x**2
z=x.detach()**3
r=(y+z).sum()
make_dot(r).render("detached", format="png")上述代码的graph如下所示,这里是少了x部分的反向传播,所以结果都是2
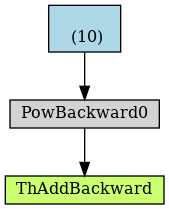
>>> r.backward()
>>> x.grad
tensor([2., 2., 2., 2., 2., 2., 2., 2., 2., 2.])总结:
detach就是把网络中的一部分分量从反向传播的流程中拿出来,使之requires_grad=False
但是拿出来的时候,还是指向原向量的地址,所以对拿出来的向量进行操作的时候,也会影响原向量。
参考:
http://www.bnikolic.co.uk/blog/pytorch-detach.html
https://blog.youkuaiyun.com/qq_27825451/article/details/95498211

















 2689
2689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









