







 FastR-CNN是一种改进自R-CNN的目标检测方法,通过整合特征提取、分类和边框回归于同一网络中,实现高效准确的目标检测。该方法采用RoIPooling层统一不同大小的候选区域,并通过多任务损失函数进行联合训练。
FastR-CNN是一种改进自R-CNN的目标检测方法,通过整合特征提取、分类和边框回归于同一网络中,实现高效准确的目标检测。该方法采用RoIPooling层统一不同大小的候选区域,并通过多任务损失函数进行联合训练。
论文笔记:Fast R-CNN
1. 简介
这是ICCV 2015的一篇论文,这篇论文改进了R-CNN和SSP网络进行目标检测,实现了更快速且更精确的目标检测。
2. 动机
此前的R-CNN网络效率很低,主要体现在:
- 训练分为多个阶段进行。
- 训练过程的时间和空间消耗都特别大
- 目标检测过程很慢
3. 方法
- 区域提取沿用之前R-CNN的方法,后续的提取特征、判断类别、回归边框在同一个网络完成
- 使用RoI Pooling,将每个proposal的映射 池化到相同的尺寸作为全连接层输入,从而提取特征
- 对于提取到的特征,通过一对sibling网络,分别将特征向量进行全连接+softmax和全连接,计算得到分类和边框回归偏置。
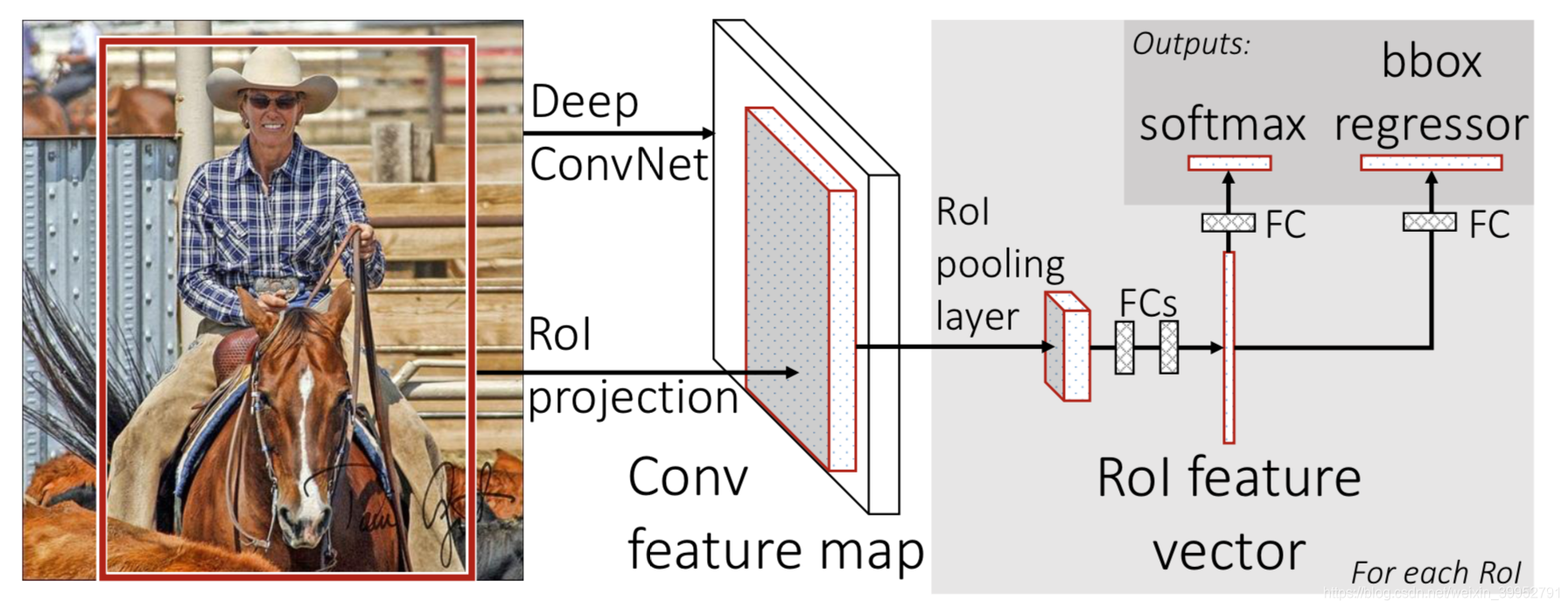
RoI pooling
对于一个尺寸为 h × w h \times w h×w的proposal,通过 h / H × w / W h/H \times w/W h/H×w/W尺寸的最大池化,将其变成 H × W H \times W H×W大小的特征图(这样的话所有尺寸的RoI池化后的大小都一样了),从而方便下一步的全连接层进行处理。
多任务训练loss定义
L
(
p
,
u
,
t
u
,
v
)
=
L
c
l
s
(
p
,
u
)
+
λ
[
u
≥
1
]
L
l
o
c
(
t
u
,
v
)
L(p,u,t^u,v) = L_{cls}(p,u) + \lambda [u \geq 1] L_{loc}(t^u,v)
L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v)
其中
L
c
l
s
(
p
,
u
)
=
−
l
o
g
P
u
L_{cls}(p,u) = -logP_u
Lcls(p,u)=−logPu,
L
l
o
c
=
L
1
s
m
o
o
t
h
(
t
u
−
v
)
L_{loc} = L_1smooth(t^u - v)
Lloc=L1smooth(tu−v) ,
[
u
≥
1
]
[u \geq 1]
[u≥1] 表示
u
≥
1
u \geq 1
u≥1 时为1否则为0,也就是类别为“背景”时不计算位置loss。
mini-batch采样
fine-tune时每个batch只输入两张图片共128个Proposals,每张图64个Proposal,加快训练速度。
Truncated SVD
将一个 u × v u \times v u×v的全连接换成两个 u × t u \times t u×t 和一个 t × v t \times v t×v的全连接。当 t < < m i n ( u , v ) t<<min(u,v) t<<min(u,v)时,可以大幅减少计算。
fine-tune 选择
不fine-tune所有layer,因为前几层fine-tune与否几乎不影响mAP,但是会拖慢训练速度,因此fine-tune从第3层开始(conv 3_1)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









