




 这篇ICCV2019论文提出了一种简单直接的多目标跟踪(MOT)策略,摒弃复杂的过程,直接用上一帧的bounding box预测下一帧的位置并进行分类判断。通过RoI Pooling、轨迹管理和运动模型(CMC和CVA)来跟踪目标。还引入了ReID机制,在轨迹消失后有机会重新启动。
这篇ICCV2019论文提出了一种简单直接的多目标跟踪(MOT)策略,摒弃复杂的过程,直接用上一帧的bounding box预测下一帧的位置并进行分类判断。通过RoI Pooling、轨迹管理和运动模型(CMC和CVA)来跟踪目标。还引入了ReID机制,在轨迹消失后有机会重新启动。
论文笔记:Tracking without bells and whistles
简介
这是ICCV2019的一篇多目标跟踪的文章。文中指出以往的tracking by detection的方法过程有点冗杂,明明可以通过回归直接预测某个物体在下一帧的位置却偏要搞一堆bells and whistles(花里胡哨),两年过去了指标也就提高了2.4%。于是本文直接提出了一个新的MOT思路,直接用上一帧的bounding box在下一帧回归出新的检测框并进行classification判断是否需要保留这个框。目前这个算法在MOT17排名第九,速度1.5FPS。
方法
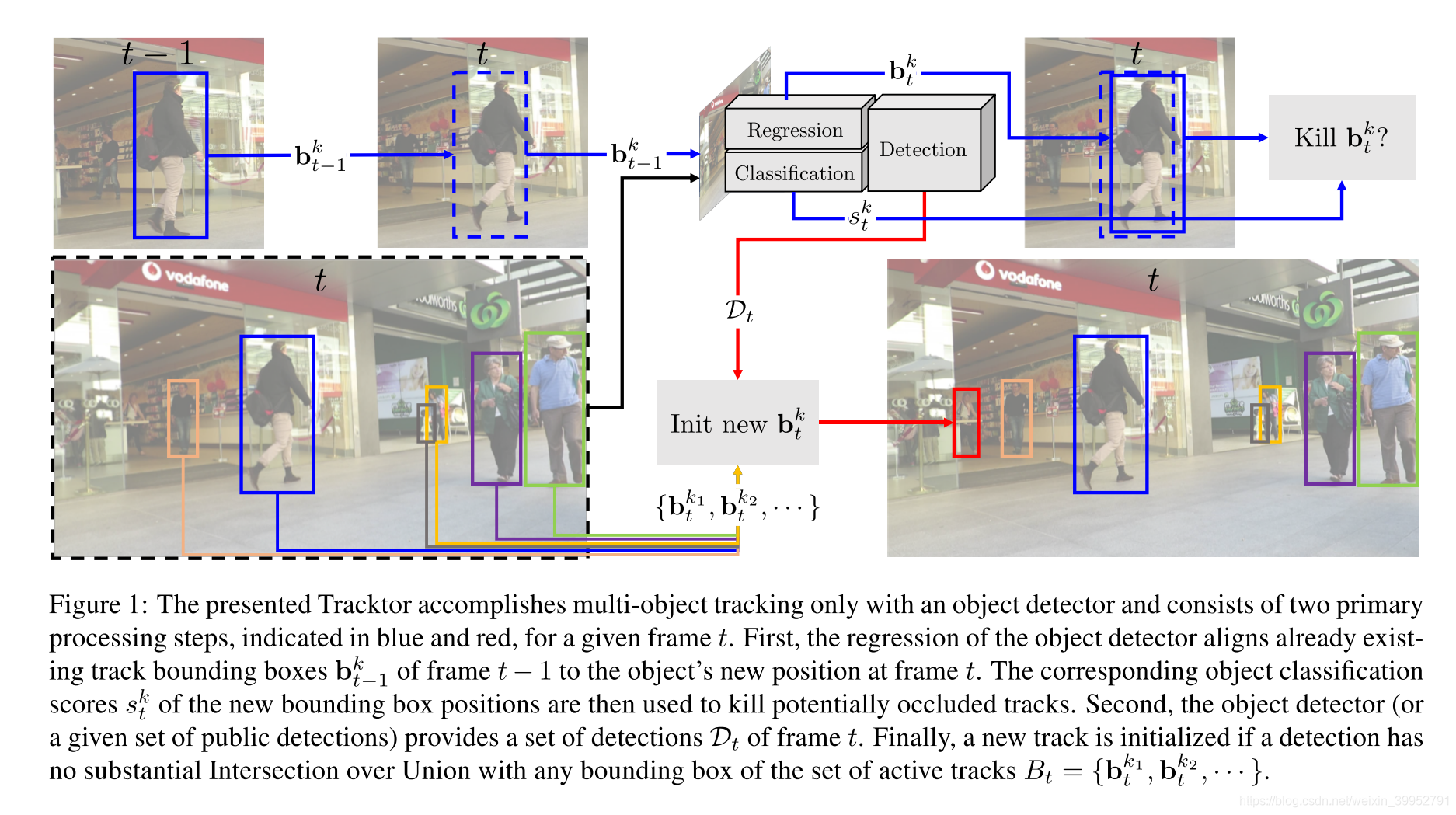
首先初始化k个跟踪序列,每个跟踪序列包含t帧图片中这条轨迹的bounding box尺寸和位置(t可以小于总共的帧数)。在新一帧的feature map用上一帧的bounding box进行RoI Pooling。当一条轨迹的分类score小于阈值,或者与其他轨迹IOU大于阈值,就kill这条轨迹;开始一条新的轨迹的条件是检测框与现有轨迹IOU小于阈值。
extensions
Motion Models
以上的回归过程基于一个假设:连续两帧之间检测框位置移动不大。然而当视频帧率比较低或者相机自身移动比较快的时候,假设不成立,因此加入了两个运动模型。camera motion compensation (CMC) 模型用来解决相机运动问题,constant velocity assumption (CVA)解决帧率不够的问题。
ReID
将之前kill过的轨迹保存一段时间,提取Reid特征,之后与新初始化的轨迹进行比较,如果特征向量距离小于阈值就重启。同时,为了减少false ReID,只考虑两条轨迹具有足够大的IOU的情况。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









