






 本文介绍了如何使用灰色预测模型和支持向量回归(SVR)进行财政收入的预测分析。首先,文章阐述了灰色预测模型的构建步骤和优缺点,然后解释了SVR的基本思想和优化过程。通过Lasso回归选取关键变量,建立了灰色预测模型预测2014年和2015年的财政收入,并进一步利用SVR模型进行预测。模型评估显示,支持向量回归模型具有良好的拟合效果,可用于财政收入的预测。
本文介绍了如何使用灰色预测模型和支持向量回归(SVR)进行财政收入的预测分析。首先,文章阐述了灰色预测模型的构建步骤和优缺点,然后解释了SVR的基本思想和优化过程。通过Lasso回归选取关键变量,建立了灰色预测模型预测2014年和2015年的财政收入,并进一步利用SVR模型进行预测。模型评估显示,支持向量回归模型具有良好的拟合效果,可用于财政收入的预测。
本文为泰迪学院最新推出的数据挖掘实战专栏第三篇,本专栏将数据挖掘理论与项目案例实践相结合,可以让大家获得真实的数据挖掘学习与实践环境,更快、更好的学习数据挖掘知识与积累职业经验。
专栏中每四篇文章为一个完整的数据挖掘案例。案例介绍顺序为:先由数据案例背景提出挖掘目标,再阐述分析方法与过程,最后完成模型构建,在介绍建模过程中同时穿插操作训练,把相关的知识点嵌入相应的操作过程中。
为方便读者轻松地获取一个真实的实验环境,本专栏使用大家熟知的Python语言对样本数据进行处理以进行挖掘建模。
下面进入第三篇,数据模型构建~
灰色预测算灰色预测法是一种对含有不确定因素的系统进行预测的方法。在建立灰色预测模型之前,需先对原始时间序列进行数据处理,经过数据处理后的时间序列即称为生成列。灰色系统常用的数据处理方式有累加和累减两种。
灰色预测是以灰色模型为基础的,在众多的灰色模型中,GM(1,1)模型最为常用。
设特征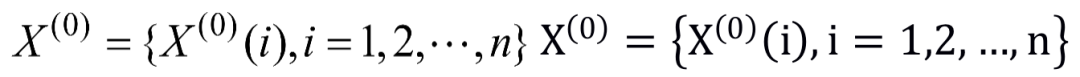 为一非负单调原始数据序列,建立灰色预测模型如下。
为一非负单调原始数据序列,建立灰色预测模型如下。
(1)首先对X(0)进行一次累加,得到一次累加序列
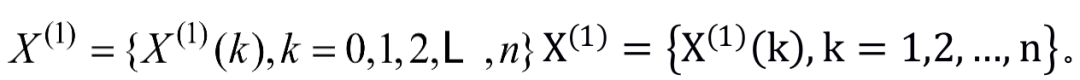
(2)对X(1)可建立下述一阶线性微分方程,如式(1-1)所示,即GM(1,1)模型
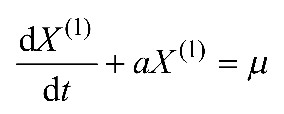 (1-1)
(1-1)
(3)求解微分方程,即可得到预测模型,如式(1-2)所示。
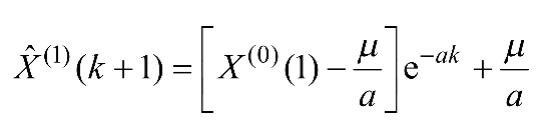 (1-2)
(1-2)
(4)由于GM(1,1)模型得到的是一次累加量,将GM(1,1)模型所得数据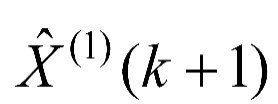 经过累减还原为
经过累减还原为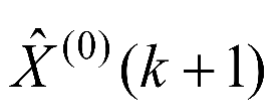 ,即的灰色预测模型如式(1-3)所示。
,即的灰色预测模型如式(1-3)所示。
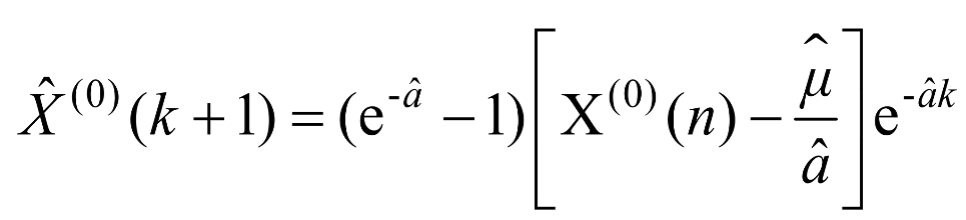 (1-3)
(1-3)
后验差检验模型精度如表1-1所示。
表 1-1后验差检验判别参照表
P |
C |
模型精度 |
>0.95 |
<0.35 |
好 |
>0.80 |
<0.5 |
合格 |
>0.70 |
<0.65 |
勉强合格 |
<0.70 |
>0.65 |
不合格 |
灰色预测法的通用性较强,一般的时间序列场合都适用,尤其适合那些规律性差且不清楚数据产生机理的情况。灰色预测模型的优点是具有预测精度高、模型可检验、参数估计方法简单、对小数据集有很好的预测效果。缺点是对原始数据序列的光滑度要求很高,在原始数据列光滑性较差的情况下灰色预测模型的预测精度不高甚至通不过检验,结果只能放弃使用灰色模型进行预测。
SVR算法SVR(Support Vector Regression,支持向量回归)是在做拟合时,采用了支持向量的思想,来对数据进行回归分析。给定训练数据集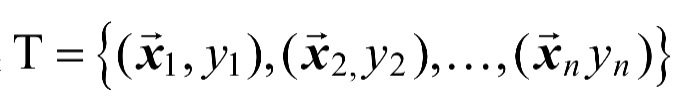 ÿ
ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5464
5464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









