









 本文深入探讨了神经网络中的归一化技术,包括Batch Normalization (BN)、Layer Normalization (LN)和Instance Normalization (IN)。BN在训练时基于批次数据计算均值和方差,而在预测时使用训练期间估算的整体均值和方差。LN则对单个样本的所有维度进行归一化,适合NLP任务。IN关注单个实例的每个维度,常用于风格迁移。文章强调了在机器学习和自然语言处理中选择不同归一化方法的原因,并分析了它们的优缺点和适用场景。
本文深入探讨了神经网络中的归一化技术,包括Batch Normalization (BN)、Layer Normalization (LN)和Instance Normalization (IN)。BN在训练时基于批次数据计算均值和方差,而在预测时使用训练期间估算的整体均值和方差。LN则对单个样本的所有维度进行归一化,适合NLP任务。IN关注单个实例的每个维度,常用于风格迁移。文章强调了在机器学习和自然语言处理中选择不同归一化方法的原因,并分析了它们的优缺点和适用场景。
目录
2.2 Batch Normalization在训练和预测时候有什么区别呢?
5 Batch normalization和Layer normalization有什么区别?
5.1.1 ML & batch normalization
5.1.2 ML & layer normalization
5.2.1 NLP & batch normalization
5.2.2 NLP & layer normalization
1 概念

在介绍各个算法之前,我们先引进一个问题:为什么要做归一化处理?
神经网络学习过程的本质就是为了学习数据分布,如果我们没有做归一化处理,那么每一批次训练数据的分布不一样,从大的方向上看,神经网络则需要在这多个分布中找到平衡点;从小的方向上看,由于每层网络输入数据分布在不断变化,这也会导致每层网络在找平衡点,显然,神经网络就很难收敛了。
当然,如果我们只是对输入的数据进行归一化处理(比如将输入的图像除以255,将其归到0到1之间),只能保证输入层数据分布是一样的,并不能保证每层网络输入数据分布是一样的,所以也需要在神经网络的中间层加入归一化处理。
2 Batch Normalization
2.1 介绍
28 批量归一化【动手学深度学习v2】_哔哩哔哩_bilibili






如果想用BN来控制模型复杂度,就没必要跟丢弃法混合使用。

2.2 Batch Normalization在训练和预测时候有什么区别呢?
BN,batch normalization,是对数据的规范化,使每层的数据输入都保持在相近的范围内。
BN和核心计算公式:
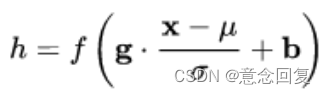
其实是一个均值 ![]() 、方差
、方差 ![]() 的标准分布。
的标准分布。
在训练时,由于是一个batch一个batch的给模型投喂数据,模型只能计算当前batch的均值和方差,当所有的batch都投喂完成,模型对每个batch上的均值和方差做指数平均,来得到整个样本上的均值和方差的近似值。
在预测时,一般不必要去计算的均值和方差,比如测试仅对单样本输入进行测试时,这时去计算单样本输入的均值和方差是完全没有意义的。因此会直接拿训练过程中对整个样本空间估算的均值和方差直接来用。
3 图解
在输入图片的维度为(NCHW)中,HW是被合成一个维度,这个是方便画出示意图,C和N各占一个维度。
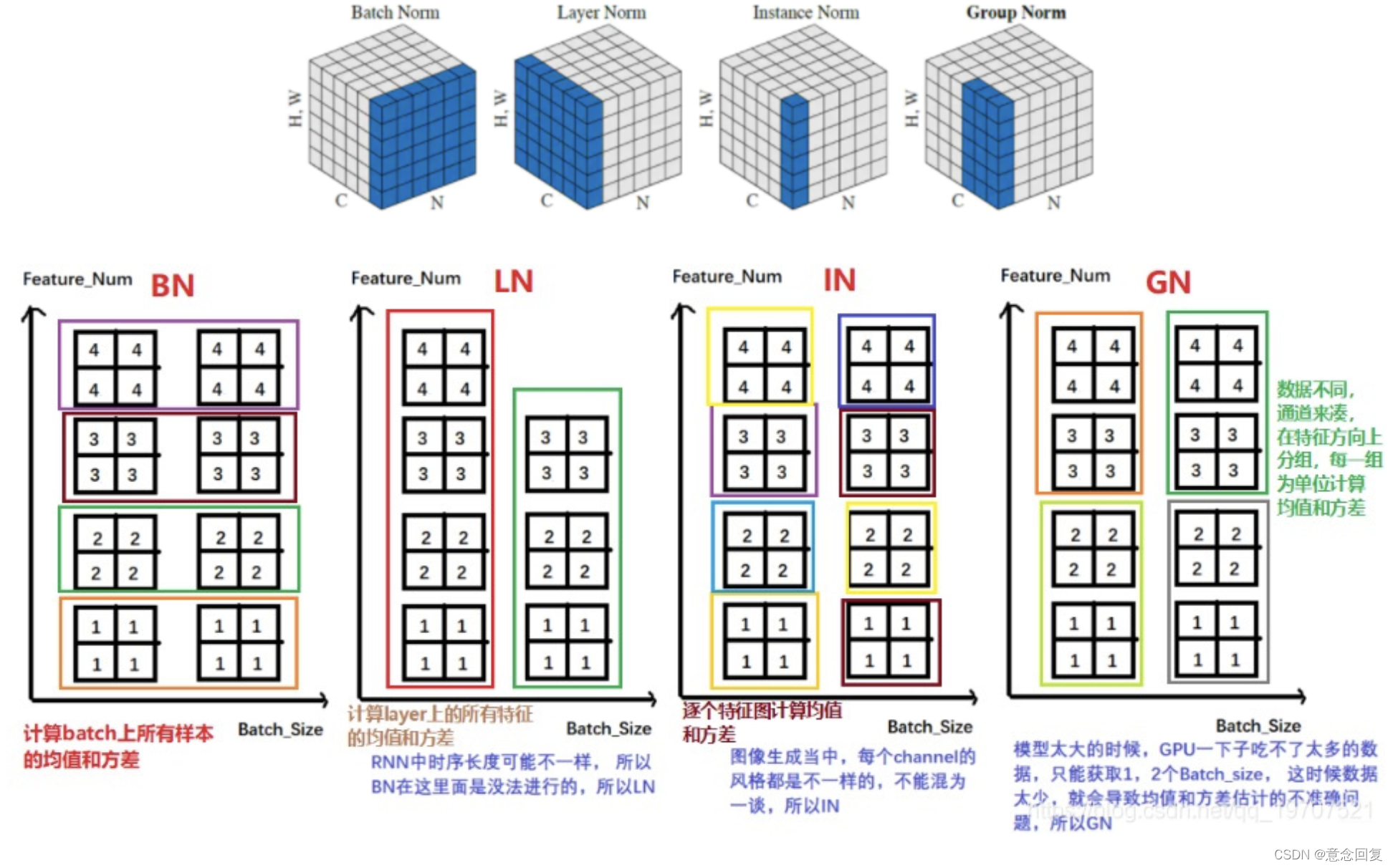
Batch Normalization:
- BN的计算就是把每个通道的NHW单独拿出来归一化处理
- 针对每个channel我们都有一组γ,β,所以可学习的参数为2*C
- 当batch size越小,BN的表现效果也越不好,因为计算过程中所得到的均值和方差不能代表全局
Layer Normalizaiton:
- LN的计算就是把每个CHW单独拿出来归一化处理,不受batchsize 的影响
- 常用在RNN网络,但如果输入的特征区别很大,那么就不建议使用它做归一化处理
Instance Normalization:
- IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batchsize 的影响
- 常用在风格化迁移,但如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理
Group Normalization:
- GN的计算就是把先把通道C分成G组,然后把每个gHW单独拿出来归一化处理,最后把G组归一化之后的数据合并成CHW
- GN介于LN和IN之间,当然可以说LN和IN就是GN的特列,比如G的大小为1或者为C
Switchable Normalization:
- 将 BN、LN、IN 结合,赋予权重,让网络自己去学习归一化层应该使用什么方法
- 集万千宠爱于一身,但训练复杂
4 公式
BN、LN、IN和GN这四个归一化的计算流程几乎是一样的,可以分为四步:
1.计算出均值
2.计算出方差
3.归一化处理到均值为0,方差为1
4.变化重构,恢复出这一层网络所要学到的分布
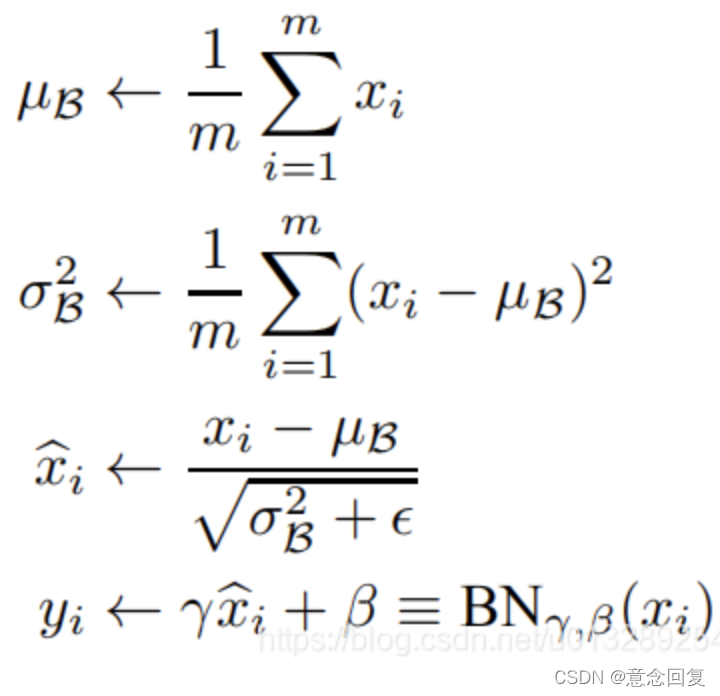
训练的时候,是根据输入的每一批数据来计算均值和方差,那么测试的时候,平均值和方差是怎么来的?
对于均值来说直接计算所有训练时batch 均值的平均值;然后对于标准偏差采用每个batch 方差的无偏估计。
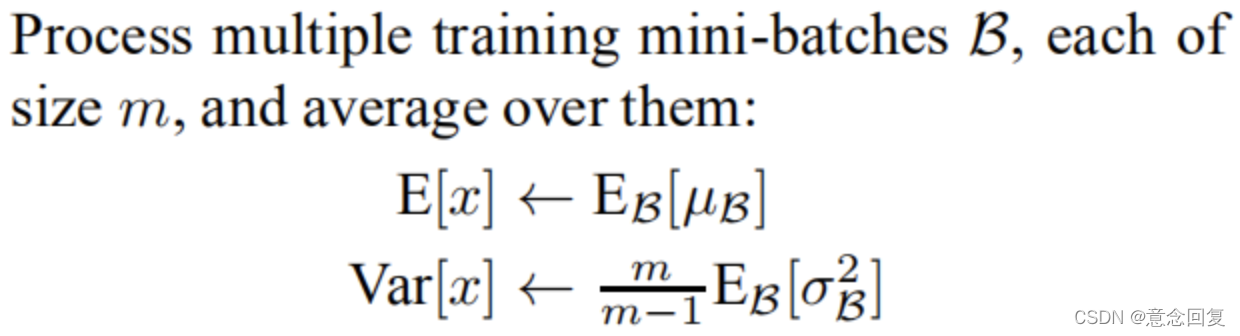
5 Batch normalization和Layer normalization有什么区别?
ML、CV里常用Batch Normalization,NLP里常用Layer Normalization。
5.1 为什么ML中用BN比较多?
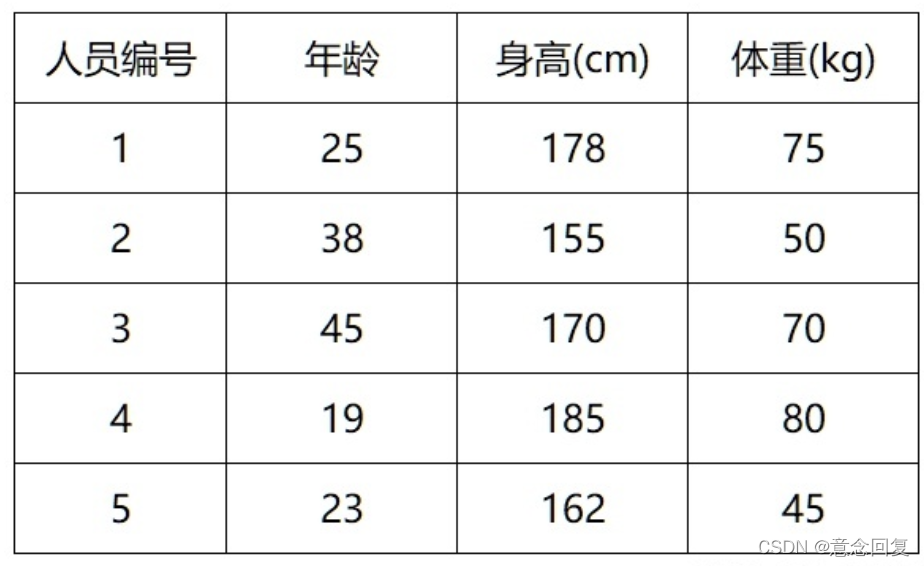
现在有一个batch内的人员特征数据,分别是年龄、身高和体重,我们需要根据这3个特征进行性别预测,在预测之前首先要进行归一化处理。
5.1.1 ML & batch normalization
BN是针对每一列特征进行归一化,例如下图中计算的均值:
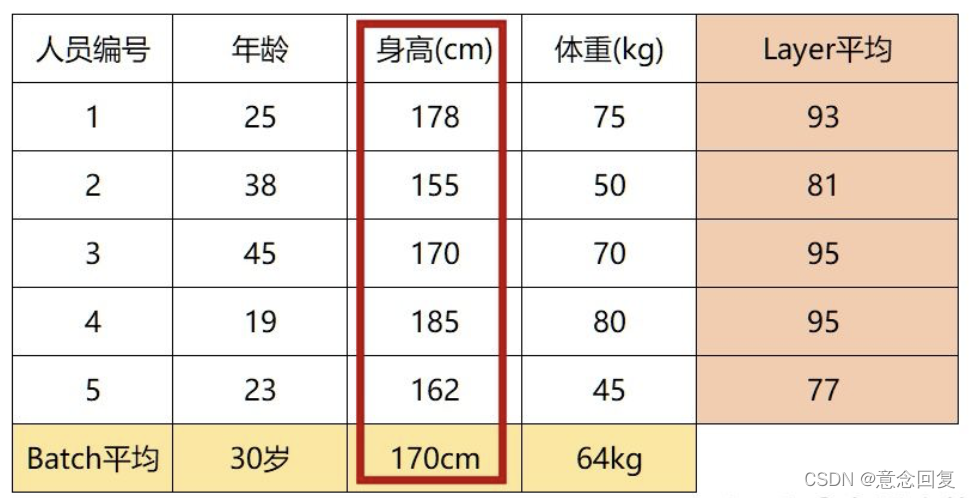
BN这是一种“列归一化”,同一batch内的数据的同一纬度做归一化,因此有3个维度就有3个均值。
5.1.2 ML & layer normalization
而LN则相反,它是针对数据的每一行进行归一化。即只看一条数据,算出这条数据所有特征的均值,例如下图:
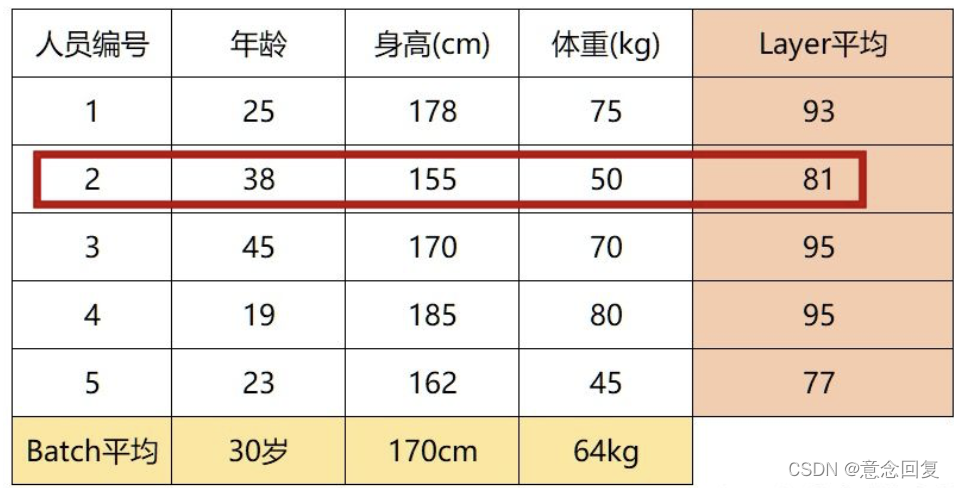
LN是一种“行归一化”,是对单个样本的所有维度来做归一化。
5.1.3 Why ML&BN?
这里大家就可以看出,LN计算出一个人的年龄、身高、体重这三个特征的均值并对其归一化,完全没有道理和可解释性,但是BN则没有这个影响,因为每列的单位属性都是相同的。
在机器学习任务中,数据往往是每列数据为一特征,处理的数据通常具有解释性,而列与列之间的单位属性并不相同,所以机器学习任务中用BN比较多。
5.2 为什么NLP中用LN比较多?
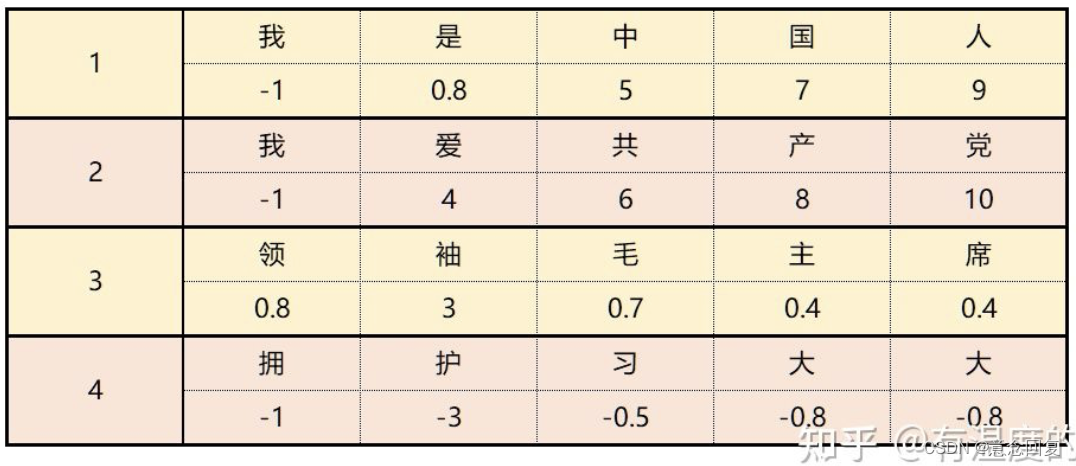
上图是4条文本数据组成了一个batch,我们假设每个字的embedding都为1。
5.2.1 NLP & batch normalization
那么BN是针对每一列特征进行归一化,就会把4条文本相同位置的字来做归一化处理,例如:我、我、领、拥。
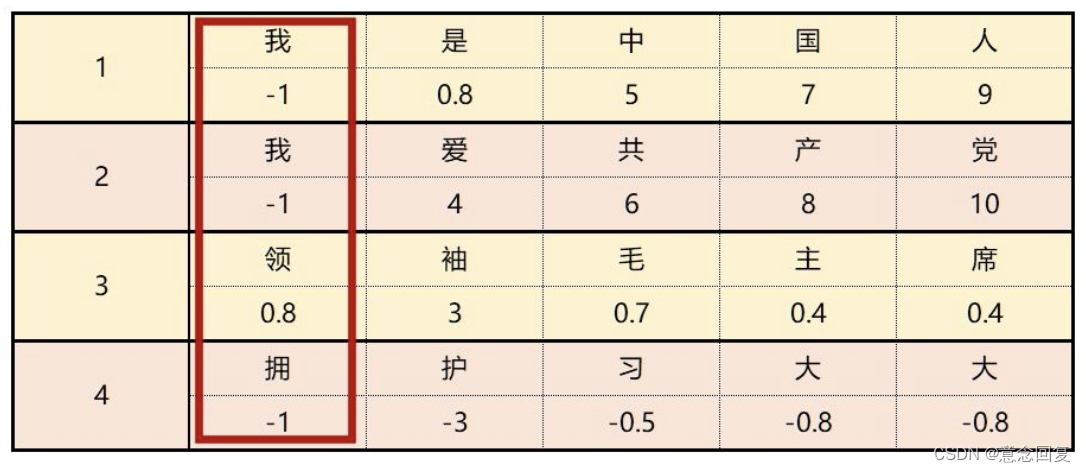
而这样做的话就破坏了一个字在原句中的原有含义。
5.2.2 NLP & layer normalization
而LN则是针对每一句话做归一化处理。
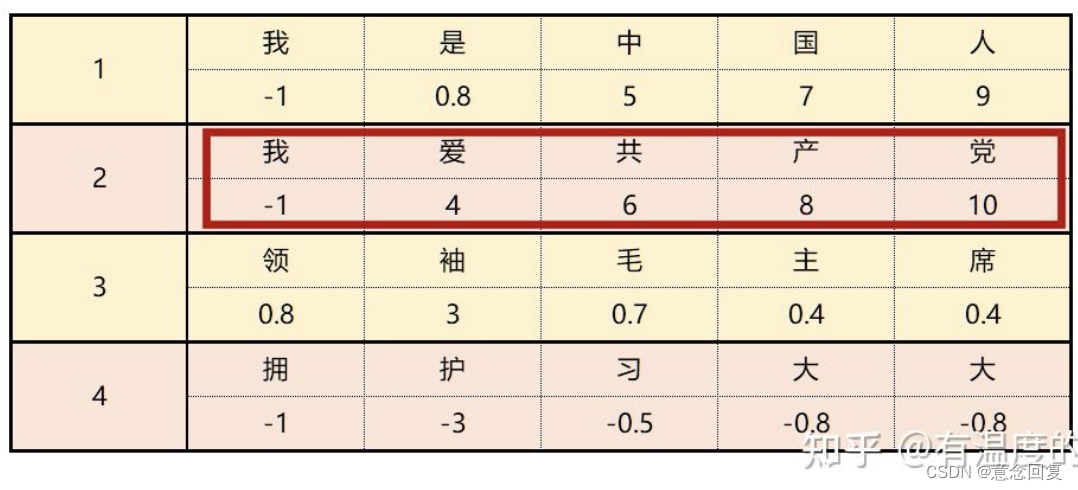
在归一化后使一句话中的embedding处于同分布。
5.3 根本原因
在ML中输入的数据一般是矩阵,每列数据都具有相同属性,所以使用BN较多。
在NLP中,因为数据维度一般都是[batch_size, seq_len, dim_size],我们最终希望将一句话中的词向量进行归一化,所以使用LN较多。
5.4 总结
从操作过程上来讲,BN针对的是同一个batch内的所有数据,而LN则是针对单个样本。
从特征维度来说,BN对同一batch内的数据的同一纬度做归一化,因此有多少维度就有多少个均值和方差;而LN则是对单个样本的所有维度来做归一化,因此一个batch中就有batch_size个均值和方差。
深度学习加速策略BN、WN和LN的联系与区别,各自的优缺点和适用的场景? - 知乎
1. Batch Normalization,其论文:https://arxiv.org/pdf/1502.03167.pdf
2. Layer Normalizaiton,其论文:https://arxiv.org/pdf/1607.06450v1.pdf
3. Instance Normalization,其论文:https://arxiv.org/pdf/1607.08022.pdf
4. Group Normalization,其论文:https://arxiv.org/pdf/1803.08494.pdf
5. Switchable Normalization,其论文:https://arxiv.org/pdf/1806.10779.pdf

















 2176
2176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









