



 本文介绍了数据结构和算法的基础知识,重点讲解了计数排序和哈希表的概念。计数排序是一种非比较排序,利用哈希表实现,时间复杂度为O(n+max),优于快速排序。哈希表是一种key-value存储结构,可用于计数排序中的桶。此外,文章还对比了桶排序和计数排序,以及基数排序的区别。同时,讨论了队列、栈、链表、树和堆排序等数据结构及其应用。
本文介绍了数据结构和算法的基础知识,重点讲解了计数排序和哈希表的概念。计数排序是一种非比较排序,利用哈希表实现,时间复杂度为O(n+max),优于快速排序。哈希表是一种key-value存储结构,可用于计数排序中的桶。此外,文章还对比了桶排序和计数排序,以及基数排序的区别。同时,讨论了队列、栈、链表、树和堆排序等数据结构及其应用。
1、算法和结构简介(Introduction )
2、哈希(Hash)
3、队列(Queue)
4、栈(Stack)
5、链表(Linked List)
6、树(tree)
7、堆排序(heap sort)
8、部分总结(Partial summary)
以下部分连接需要FQ才能查看
1、算法和结构简介(Introduction )
(1)排序分类
- 排序算法列表
- 选择排序(体育老师一指禅法)
- 冒泡排序 (体育委员两两摸头法)
- 插入排序 (起扑克牌法)

- 基数排序(强迫症收扑克牌法)
- 快排
- 归并排序
- 桶排序
- 堆排序
- 其他排序:
排序可视化:
Sorting (Bubble, Selection, Insertion, Merge, Quick, Counting, Radix)visualgo.net
(2)什么是算法
https://zh.wikipedia.org/zh-hans/%E7%AE%97%E6%B3%95zh.wikipedia.org以下是高德纳在他的著作《计算机程序设计艺术》里对算法的特征归纳:
- 输入:一个算法必须有零个或以上输入量。
- 输出:一个算法应有一个或以上输出量,输出量是算法计算的结果。
- 明确性:算法的描述必须无歧义,以保证算法的实际执行结果是精确地匹配要求或期望,通常要求实际运行结果是确定的。
- 有限性:依据图灵的定义,一个算法是能够被任何图灵完备系统模拟的一串运算,而图灵机只有有限个状态、有限个输入符号和有限个转移函数(指令)。而一些定义更规定算法必须在有限个步骤内完成任务。
- 有效性:又称可行性。能够实现,算法中描述的操作都是可以通过已经实现的基本运算执行有限次来实现。
(3)什么是数据结构
- 我们要解决一个跟数据相关的问题
- 分析这个问题,想出对应的数据结构
- 分析数据结构,想出算法
大分类
- 分治法:把一个问题分区成互相独立的多个部分分别求解的思路。这种求解思路带来的好处之一是便于进行并行计算。
- 动态规划法:当问题的整体最优解就是由局部最优解组成的时候,经常采用的一种方法。
- 贪婪算法:常见的近似求解思路。当问题的整体最优解不是(或无法证明是)由局部最优解组成,且对解的最优性没有要求的时候,可以采用的一种方法。
- 线性规划法:见词条。
- 简并法:把一个问题通过逻辑或数学推理,简化成与之等价或者近似的、相对简单的模型,进而求解的方法。
前端主要使用分治法——分而治之。
(4)冒泡法和选择排序法流程图和伪代码见前面博客:
bomber:选择排序法伪代码示例zhuanlan.zhihu.com(5)其他
不加引号的表示容器,加了引号(单引号或者双引号)表示字符串。
比如:
length 表示一个容器, 'length' 表示字符串, length <- 'length' 表示将字符串放入容器
方框内表示内存里面的内容,不加引号的时候,length里面如果没有赋值就不知道是什么。
加了引号,‘length’里面就表示length这6个字符串连在一起。

JS规则,如果如果index索引是一个数字,会自动转成字符串。
2、哈希(Hash)
(1)哈希就是英文Hash中式发音演化过来的,数组其实就是哈希的一种。JS里面的对象就表示哈希,数组就是对象。
哈希表就是一个key:value数组这种结构的形式,类似:
a{'0':0;
'1':1;
key:value;
键:值;
}
上面的形式也可以不用冒号和引号,之前介绍的http请求和响应的第二部分也是哈希表:
bomber:HTTP请求和响应介绍zhuanlan.zhihu.com(2)通过哈希来介绍另一种排序——计数排序,前面说的冒泡法(体育委员两两摸头法)、选择法(体育老师一指禅法)、插入排序法(起扑克牌法)都是比较排序,必须要两个比较(两个数可以左右相邻或者相隔)。
只要作比较都至少要遍历一次然后在排序一次。
比如随机快速排序法的最快的情况的时间复杂度是nlog(2)n,括号里面的2是log的底数,但是计数排序的时间复杂度可以做到n+max即可。
百度百科中有描述到,数组n的大小是2的幂,这样分下去始终可以被2整除。假设为2的k次方,即k=log2(n)。


首先了解一个问题:
数组就是对象,数组不可以有负数,比如‘-1’项,列出一个数组。
a <- {
'-1':99, //数组不可以出现-1项目
'0':0,
'1':2,
'2':1,
'3':56,
'4':4,
'5':67,
'6':3,
'length:7'
}删除‘-1’项,这里面的length就是7,因为最大的索引数是6,length就是最大的索引数6+1=7
a <- {
'0':0,
'1':2,
'2':1,
'3':56,
'4':4,
'5':67,
'6':3,
'length:7'
}这里面的length是67,因为最大的索引数是66,length就是最大的索引数66+1=67
a <- {
'0':0,
'1':2,
'2':1,
'3':56,
'4':4,
'5':67,
'6':3,
'66':8
'length:67'
}所以length跟个数没关系,而是跟最大的索引有关,有部分代码是从索引1开始而不是从索引0开始,这样就可以不用+1。
在了解这个知识点的前提下我们在看下面的伪代码:
第一步(入桶)——把a数组里面的用hash数组来代替。

这样就会得到hash数组,意思是代表有几个某数字(例如第一项是有1个0,第二项有1个1,以此类推)。
hash<- {
'0':1,
'1':1,
'2':1,
'3':2,
'56':1,
'67':1
}第二步(出桶)——遍历哈希hash,并通过前面的比较排序法找到最大的数字。最大的数字加1也就是长度length。然后按照插入排序法就完成了所有的计数排序法过程。
下面代码中count==3左边的else应该是else if
count=hash[index2]下一行缺了一个if count!=undefined(也就是说必须存在)

newArr.push(index2)的过程优化后:

(3)所以前面说的计数排序的复杂度O(n+max),其实n代表遍历一遍,有n个数字就看n次,max就是哈希数组里面的最大的次数,变成哈希数组之前的数字里面的最大的数字。可以有很多用途,例如需要统计班级的各个同学的年龄(因为年龄一般都是0-300岁之间)百科上有一个256岁的不知道真假,吓呆我了。
李庆远(256岁超级老寿星)_百度百科baike.baidu.com对比1024个人的年龄(0-300岁)的时间复杂度:
计数排序就是就是1024(n一共有这么多个人)+300(年龄的最大值减去最小值)=1324次。
如果是快排来计算时间复杂度最快最优比较次数,这时候就跟年龄没有关系了,就跟人数有关系,1024log(2)1024,2的10次方=1024,这样算下来就是1024×10=10240次。
这样快排(快排是比较排序中速度最快的排序了)的最优最快的次数也比计数排序要慢,快排中最慢的次数是n的平方。也就是1024×1024次。
综上可以看到计数排序的速度是比较快的,但是有几个缺点:
第一:计数排序需要一个哈希表(hash table)作为计数的工具;
第二:因为是从0开始计数的,当然也可以改进,但是比较麻烦;小数的话需要确定精度,两个整数之间有无数个小数,就需要无数个桶,所以计数排序一般不能对小数和负数进行排序,只能排0到正无穷的正整数。
(4)桶排序与计数排序的区别
http://bubkoo.com/2014/01/15/sort-algorithm/bucket-sort/bubkoo.com常见排序算法 - 桶排序 (Bucket Sort)
常见排序算法 - 桶排序 (Bucket Sort)bubkoo.com计数排序是一个桶里面放一个数字,而桶排序是一个桶里面放多个数字。
比如把前面你的hash的计数排序按照桶排序就是这样:
hash{
1:[0,2,1,3,3] //第一个桶放小于10的整数
2:[] //第二个桶放大于10小于20的整数
3:[] //第三个桶放大于20小于30的整数
4:[] //第四个桶放大于30小于40的整数
5:[] //第五个桶放大于40小于50的整数
6:[56] //第六个桶放大于50小于60的整数
7:[67] //第七个桶放大于60小于70的整数
}这样就可以对第一个桶里面的数字在进行其他的排序(比如冒泡,选择、快排等)
第一个桶里面的数字就不需要跟二个或者其他的桶排序,也就是各个桶之间数字分开了,只有各个桶自己内在的才能继续排序。
如果做到最小,也就是只做两个桶,那效果其实就和快排一样,因为快排就是把一个值作为参考,左边的比他小,右边的比他大,这样杜宇桶排序也就是两个桶,一个是比它大的桶,一个是比它小的桶。
计数排序是最简单的,不需要做二次排序。但是浪费了很多桶。比如上面的哈希表(hash table)数组,数字最大的是67,需要68个桶。
桶排序只需要7个桶,但是需要二次排序。
所以这两者排序的区别:
桶排序少用了空间(只需要7个桶),需要二次排序浪费了时间;
计数排序少了时间不需要二次排序,浪费了空间(需要68个桶)。
空间也算是内存,时间也算是cpu。
桶排序的例子:比如高考分数按照一百分间隔排序。
(5)基数排序与计数排序的区别
常见排序算法 - 基数排序 (Radix Sort)bubkoo.com把基数排序的过程看一遍就了解啦。下列数字按照基数排序

先按照个位数排序(第一次入桶)

第一次出桶,此时个位数是从小到大排序的。

然后十位数排序(第二次入桶)

第二次出桶此时十位数是从小到大排序的。
当十位数是一样的时候,个位数是从小到大排序的。

然后百位数排序(第三次入桶)

第三次出桶此时百位数是从小到大排序的。
当百位数是一样的时候,十位数是从小到大排序的。

最后千位数排序(第四次入桶)

第四次出桶此时千位数是从小到大排序的。
当千位数是一样的时候,百位数是从小到大排序的。前面的位数也已经排好了

基数排序就适用于最大数字和最小数字相隔特别大,并且中间还有其他数字,桶数是一定的,一般都是十个桶,排序次数根据最大数字的位数(个十百千)来决定,上面的千位就需要出桶入桶各四次,先进先出的原则。
计数排序一般只需要出桶入桶各一次即可。
下面链接可以查看基数排序动态过程:
排序(冒泡排序, 选择排序, 插入排序, 归并排序, 快速排序, 计数排序, 基数排序)visualgo.net队列和栈会用到push()
Array.prototype.push()developer.mozilla.org
push() 方法将一个或多个元素添加到数组的末尾,并返回该数组的新长度。
3、队列(Queue)
先进先出的就是队列,可以用很多来实现,一般来说比较方便的可以用数组来实现。
在现实生活的例子就是排队,比如在12306排队买票排队系统中,先买票的人优先出票。
JS测试:
Array.prototype.shift()developer.mozilla.orgshift方法移除索引为 0 的元素(即第一个元素),并返回被移除的元素,其他元素的索引值随之减 1。如果length属性的值为 0 (长度为 0),则返回undefined。
shift()就可以实现先进先出:

前面的基数排序用到了队列这种先进先出的特性。
4、栈(Stack)
先进后出的就是栈,可以用很多来实现,一般来说比较方便的可以用数组来实现。
在现实生活的例子就是小时候用小瓶子装弹珠,先进去的弹珠一般在最下面,要把上面的弹珠拿出来后才能拿到下面的弹珠。
电影中的盗梦空间也是先进后出。
JS测试
Array.prototype.pop()developer.mozilla.orgpop()方法从数组中删除最后一个元素,并返回该元素的值。此方法更改数组的长度。
pop()就可以实现先进后出:

5、链表(Linked List)
数组无法直接删除中间的一项,链表可以
a <- {
'0':0,
'1':2,
'2':1,
'3':56,
'4':4,
'5':67,
'6':3,
'length:7'
}如果是上面的a数组要删除第三项‘3’:56的步骤:
第一步——把第三项‘3’:56删除;
第二步——把第四项的值4、第五项的值67、第六项的值3都往各自的前一项提一位;
第三步——把最后一项,也就是第六项删除;
第四步——把length修改为当前索引最大值(5)加一,就由7变成了6;
上面的代码经过四步才能变成下面的代码:
a <- {
'0':0,
'1':2,
'2':1,
'3':4,
'4':67,
'5':3,
'length:6'
}链表操作就简单多了,一步就可以了:
只列出前三项的数据

只需要把a1的next指向到a3就可以删除a2了。

用JS来实现这个过程

如果要删除掉第二项目——value:2,就是value:0后面接value:1;

所以以上这种一个哈希表指向另一个哈希表,以此类推的可以用链表来删除中间的数据。
不过JS中链表不常用。因为操作比较麻烦,需要a.next.next.next...........如果数据量很大,想要取到中间值就需要很多.next。第n项需要n-1个next,而数组里面取第n项目只需要a[n-1]。
n是中间数,数组查询第n项目比较快,链表删除第n项目比较快。
head——链表中的第一个哈希表的对象,就是链表的表头。类似上面的a1,有了a才能.next;
node——下面的a1,a2,a3都是,就是链表的节点,a1是head表头也是node节点;
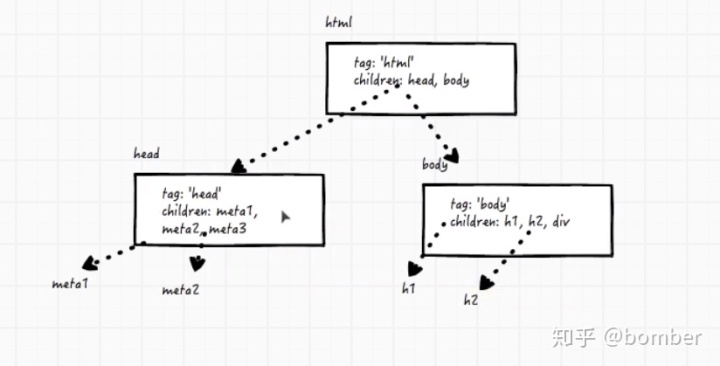
6、树(tree)
只要有层级结构就需要用到树。
最简单的,html标签里面有head和body标签,body标签里面有div、span等各种标签,这种就是层级结构。

把它倒过来就是一个类似的树的样子啦。

链表每次只有一个箭头,这里有两个或者多个箭头。这就是树。
层数:
第1层(有的情况是第0层):html;
第2层:head、body;
第3层:meta1、meta2、meta3、h1、h2、div。
深度:意思就是一共多少层,上面的树一共就是3层。
节点个数:每一个哈希都是一个节点,上面的树中html、head、body、meta1、meta2、meta3、h1、h2、div一共9个节点。
叶子节点:没有儿子的,没有下一层的,断子绝孙的节点就是叶子节点。上面的树中meta1、meta2、meta3、h1、h2、div就是叶子节点。
二叉树:
每次最多分两个叉就是二叉树,上面的树就不是二叉树。
修改成这样就是二叉树(每次分开两个叉):
修改成这样也是二叉树(有一个分开小于两个叉):

修改成这样也是二叉树(最低层有两个分开小于两个叉):

二叉树介绍链接:
https://zh.wikipedia.org/wiki/%E4%BA%8C%E5%8F%89%E6%A0%91zh.wikipedia.org满二叉树:二叉树的叶子节点必须长满两个才叫满二叉树。

二叉树的第i层最多拥有2的(i-1)次方个节点:比如上面的代码:
第1层最多有2的(1-1)次方=1个节点;
第2层最多有2的(2-1)次方=2个节点;
第3层最多有2的(3-1)次方=4个节点;
所以我们可以统计如下:

完全二叉树——在一棵二叉树中,除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边(当然左边连续也是可以的,但是一般都是习惯右边)缺少连续若干节点,则此二叉树为完全二叉树(Complete Binary Tree)
以下都是完全二叉树:



这样就不是完全二叉树,因为已经不连续了。

完全二叉树和满二叉树可以用数组来实现(存数)
比如有这样的一个数(满二叉树)

列成数组:

第3层的第一个数字就是(2的2次方减1)=3,第3个数也就是4(第0个数是1)

第4层的第一个数字就是(2的3次方减1)=7,第8个数字也就是7(第0个数是1)

第3层的第4个数字也就是(2的2次方减1)之后在加3=6,第6个数字也就是7(第0个数是1)

如果不是满二叉树或者完全二叉树,不能用以上方法,一般可以用哈希表(对象)来取,类似链表。

其他的树:
B树
https://zh.wikipedia.org/wiki/B%E6%A0%91zh.wikipedia.org红黑树
https://zh.wikipedia.org/wiki/%E7%BA%A2%E9%BB%91%E6%A0%91zh.wikipedia.orgAVL树
https://zh.wikipedia.org/wiki/AVL%E6%A0%91zh.wikipedia.org7、堆排序(heap sort)
堆——完全二叉树或者满二叉树的前提,当下一层的数字总是比上一层的数字要小的时候就是堆。
比如这样就是堆:

堆顶:就是第1层,就是根节点。
叉堆一般分为两种:最大堆和最小堆。
最大堆:
- 最大堆中的最大元素值出现在根结点(堆顶)
- 堆中每个父节点的元素值都大于等于其孩子结点(如果存在)

最小堆:
- 最小堆中的最小元素值出现在根结点(堆顶)
- 堆中每个父节点的元素值都小于等于其孩子结点(如果存在)

最大堆调整(Max-Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点。
大概步骤如下:
1、确定该数组符合完全二叉树,并且顶层往底层推进,上层的数字都大于下一层的数字的时候就是堆;
2、取n层的第一个数字就是2的n次方减1,这样就可以找到该层的所有数字;
3、通过这种找法,找到每层树最底层的最大值往上一层调换数字,并且保证调换后的数字的上一次和下一层同样保证为堆(也就是儿子的数字小于父亲的数字),然后依次调换推进到顶层,这样顶层就是最大的数字;
4、把顶层最大的数字与底层最右边(为了保证为完全二叉树)的数字调换,然后隐藏掉最大的数字(目的是为了最大的数字不在参与排序);
5、底层最右边的数字调换到最堆顶了,这样再次使得堆顶必须大于下一层的数字大小的规律进行调换(类似于做最大堆调整);
6、重复4、5。

完全二叉树或者满二叉树每1层对应的索引

例如下面的截图就是
第4层中的最后两个数字(689和776)对比,第4层中最后两个数字的索引是(2的5次方-1)-1=30和2的5次方-1)-2=29,选出最大值,跟上一层中的数字(384)对比,上一层(第3层)中最后一个数字的索引是(2的4次方-1)-1=14,如果叶子节点数字比上一层要大,就调换,依次推进到堆顶。

堆排序的时间复杂度是nlog(2)n,(2)为log的底数。跟快排最优的情况是一样,但是比快排除了最优的情况要快(因为快排最差的的情况的时间复杂度是n的平方)。但是堆排序需要用到的数据结构知识特别多,计算量也比较大。
堆排序可视化:
Heap Sort Visualizationwww.cs.usfca.edu堆排序JS代码完整讲解(看到最后),堆排序的截图来自于以下链接:
常见排序算法 - 堆排序 (Heap Sort)bubkoo.com8、部分总结(Partial summary)
哈希表(Hash Table)就是一个或者多个key:value,对象和数组都是哈希表,只要能满足key:value的都是哈希表。
- 计数排序中的桶(复杂度 O(n+max),比快排还快(因为额外用到了哈希表来装桶,快排没有用到桶)
- 桶排序 与计数排序的区别,桶排序的桶比计数排序的要少,节约桶,但是要进行二次排序。
- 基数排序 与计数排序的区别,基数排序适用的数字最小值和最大值相隔特别大,比如1和10000,中间还有一些其他值,桶数是一定的,一般都是十个桶,排序次数根据最大数字的位数(个十百千)来决定,千位就需要出桶入桶各四次,先进先出的原则。
队列(Queue)
- 先进先出
- 可以用数组实现
- 举例:排队
栈(Stack)
- 先进后出
- 可以用数组实现
- 举例:盗梦空间
链表(Linked List)
- 数组无法直接删除中间的一项,链表可以
- 用哈希表(JS里面用对象表示哈希表)实现链表
- head、node 概念
链表很少用,了解链表是为了了解树。一叉树、三叉树、四叉树不能用数组表示,一般都是用链表表示,但是链表很麻烦。二叉树满足一定条件就可以用数组来实现。
树(tree)
- 举例:层级结构、DOM
- 概念:层数、深度、节点个数
- 二叉树,最多分两个叉。
- 满二叉树,二叉树的叶子节点长满了。
- 完全二叉树,二叉树的叶子按照顺序长。
- 完全二叉树和满二叉树可以用数组实现
- 其他树可以用哈希表(对象)实现,哈希表就是多个链表连起来。
- 操作:增删改查
- 堆排序用到了 tree,堆就是符合完全二叉树或者满二叉树的前提下,下面的数字要比上面的数字要小。最大堆就是最大的数字在堆顶。最大对调整,将堆的末端子节点作调整,使得子节点永远小于父节点。时间复杂度nlog(2)n,(2)为log的底数,要对比n次,每一次的个数是log(2)n个。
- 其他:B树、红黑树、AVL树
以上部分链接需要FQ。
以上部分截图来自于饥人谷。
本文为本人的原创文章,著作权归本人和饥人谷所有,转载务必注明来源


















 5028
5028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









