






Monte-Carlo Dropout: 让模型“知道自己不知道”
原创 碧沼 碧沼 2025年05月10日 00:06 陕西
Monte-Carlo Dropout: 让模型“知道自己不知道”
在机器学习和深度学习的世界里,Dropout 可以说是家喻户晓的正则化手段。它通过随机丢弃神经元,让模型在训练中学会更强的泛化能力。
最近笔者阅读一篇论文 CSPO: Cross-Market Synergistic Stock Price Movement Forecasting with Pseudo-volatility Optimization应用到了Monte-Carlo Dropout,因此对其进行学习。
传统 Dropout 在测试时是关闭的,模型其实“不知道自己的不确定性”。
Monte-Carlo Dropout(MC Dropout),是一种优雅的贝叶斯近似方法,它能让模型学会“承认自己不知道”,并量化预测的不确定性。
为什么传统 Dropout 不够用了?
我们先来看一下传统 Dropout 的工作流程:
-
训练时:随机丢弃部分神经元,避免过拟合。
-
测试时:关闭 Dropout,做确定性预测。
这种设计的问题是:
模型预测结果中没有包含任何“置信度”信息。对于金融、医疗等高风险场景,模型不仅要给出答案,更要告诉我们它对这个答案有多自信。
什么是Monte-Carlo Dropout?
蒙特卡罗 Dropout(MC Dropout)的方法非常直接:
测试阶段也开启 Dropout,多次前向传播,统计输出的均值和方差。
公式上,假设我们采样次
-
预测均值:
-
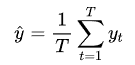
-
预测方差:
-
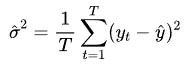
借助 MC Dropout,我们不仅能在测试阶段获取预测均值和方差,从而衡量模型的不确定性,还可以在训练阶段估计每个样本的预测方差。基于这些估计值,我们可以设计加权损失函数,让高置信度(低方差)的样本获得更高的权重,从而提升模型的稳健性与泛化能力。
MC Dropout 不仅输出预测,还能输出置信区间。
在高波动的噪声区间理论上能提供更保守的预测。
笔者在一份模拟的数据集上,基于MC Dropout的方式对损失进行修改,测试集上的loss相较于原始MSE明显观测到了收敛更快的结果。
总结:不确定性的建模工具 Monte-Carlo Dropout
传统 Dropout:
✅ 简单
✅ 减少过拟合
❌ 测试时失去不确定性
MC Dropout:
✅ 简单
✅ 提供预测分布
✅ 更适合高风险场景
下次构建模型时,不妨试试 MC Dropout,让模型不仅给出答案,还能告诉你它有多确定。
📌 附加建议:作为模型研究员,在训练过程中,可以直接用不确定性加权的损失函数替代传统 MSE,让模型在高噪声场景下表现更稳健。

















 5598
5598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









