






参考网址:C++核心编程
本阶段主要针对C++面向对象编程技术做详细讲解,探讨C++中的核心和精髓。
(面向对象就是将任何事物抽象成类,通过类的实例化成为对象,利用对象来实现各种功能。
面向对象的特点就是将程序分为几大块,分模块实现,再通过接口组合。优点是易维护)
(面向对象的三个基本特征是:封装、继承、多态。其中,封装可以隐藏实现细节,使得代码模块化;继承可以扩展已存在的代码模块(类);它们的目的都是为了——代码重用。而多态则是为了实现另一个目的——接口重用!)
C++面向过程和面向对象两种编程的优缺点是什么?
面向对象的优点是,把一些东西高度抽象出来,并赋予它一定的属性和方法。这样在比较大型的项目中,可以很严格的分出层次。当编程到一定的时候,你就会发现如何编这个东西已经不重要了,关键是如何很好的架构他,面向对象可以把一些东西高度重构出来,适合各个版块去重用它,编程讲究低耦合,各个层的联系尽量少,面向对象就是有这个好处。
面向过程一般用于一些追求速度和内存的编程体,比如完成某项图形算法,JAVA的手机游戏也推荐采用面向过程,因为这样可以提升程序效率和减小目标程序的大小,减少内存消耗。
一、 内存分区模型
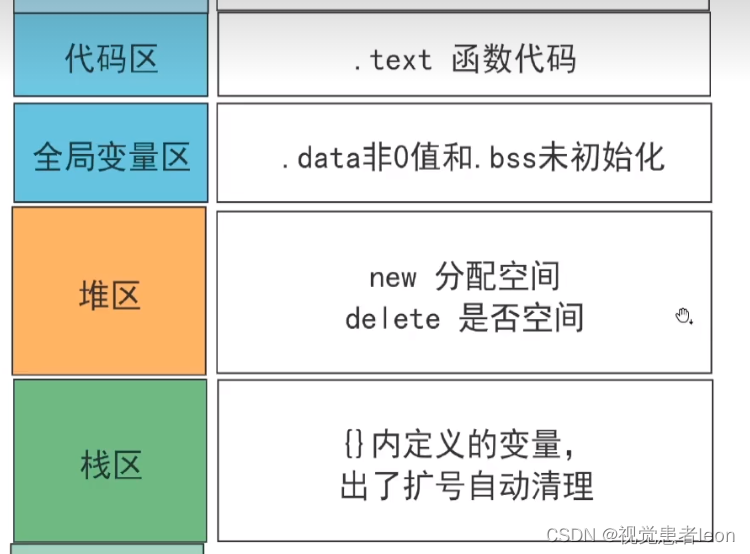
代码区:
文本区存储程序的机器代码。(函数体代码的存放位置)
只读存储区存储字符串常量。
全局区:
数据段:已初始化的全局变量和静态变量(局部+全局)。
bss 段:未初始化的全局变量和静态变量(局部+全局),被初始化为 0 的全局变量和静态变量(局部+全局)。
常量区:const修饰的全局变量(全局常量),常量必须初始化。
栈区:局部变量、局部类对象、const修饰的局部变量(局部常量)、函数的返回地址、参数、返回值。地址从高向低(反方向)
堆区: new/malloc动态分配的变量、对象等,地址从低到高。
注:
类对象也分为全局对象、局部对象,存放位置与全局变量、局部变量相同。
类中的成员函数存放在代码区,类中成员变量,成员函数中的变量存放在栈区。
静态成员变量和静态成员函数,都是所有对象共享一份存储空间。
非静态成员变量和非静态成员函数,一个对象一份存储空间。
(难道不同对象的静态成员变量都相同吗)
1. 程序运行前
(编译生成了exe文件,但未执行该程序)
在程序编译后,生成了exe可执行程序,未执行该程序前,分为两个区域。
(含义:我们在visual studio中编写的程序,如果编译生成了exe文件,就说明向内存条申请了“代码区”和“全局区”)
1)代码区
存放函数体的二进制代码,由操作系统进行管理的,不是编译器。
存放 CPU 执行的机器指令,即二进制的0和1;
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可;
代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令。
2) 全局区
该区域的数据在程序结束后由操作系统释放,不是编译器
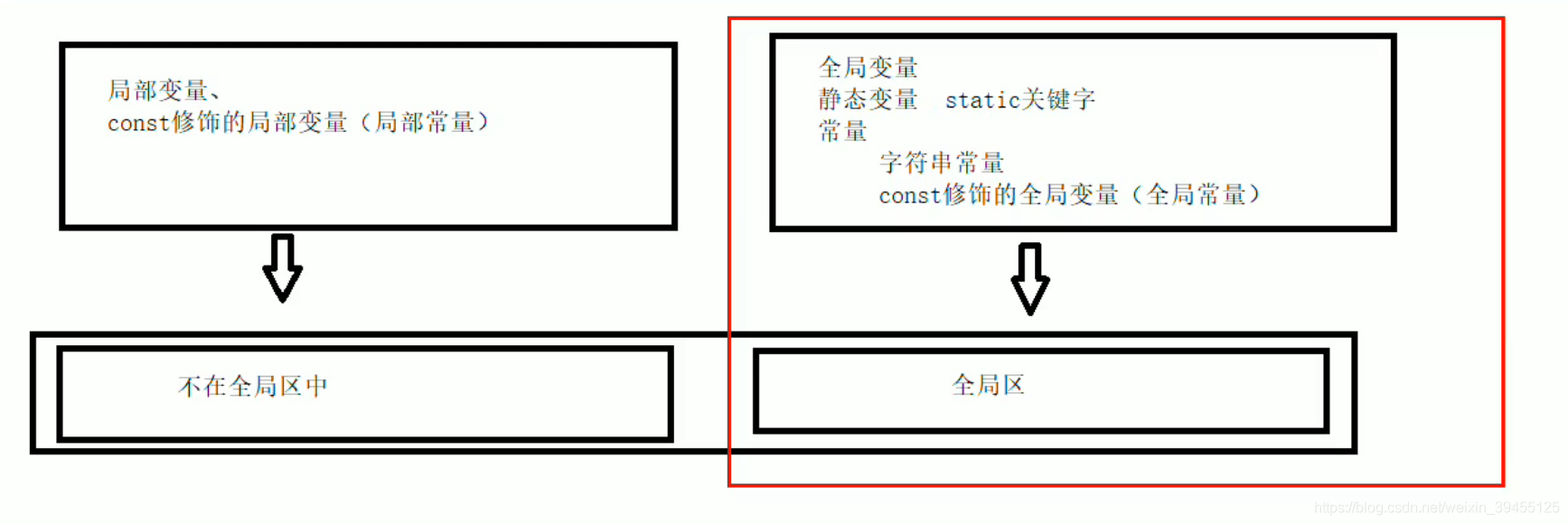
变量:
局部变量:所有函数体内定义的变量,都为局部变量。包括主函数和子函数。
全局变量:函数体外的定义的变量。
静态变量:在局部变量前,加上static。如函数体内语句static int s_a = 10;
常量:
字符串常量:双引号内的字符串。如"hello world"
const修饰的变量:
const修饰的全局变量,如函数体外语句const int c_g_a = 10;(全局常量)
const修饰的局部变量,如函数体内语句const int c_g_a = 10;(局部常量)
变量和常量在内存中的存放位置:
2. 程序运行后
(exe程序在运行中,不是退出程序)
1) 栈区
由编译器自动分配释放, 存放函数的形参,局部变量等
注意事项:不要返回局部变量的地址,栈区开辟的数据由编译器自动释放。
(可以返回局部变量,本质是拷贝了局部变量,并放在CPU寄存器中,临时右值)
(如局部变量,存放在栈区,栈区内的数据在“函数执行完成后”自己释放,那么我们将不能再次访问。
而全局变量,存放在全局区,函数执行后没有被释放,可以再次访问全局变量。)
局部变量包括了局部对象,即定义在某个函数内的对象,主函数内的对象也叫局部对象。
2)堆区
由程序员分配释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存:指针放在栈区,指针指向的数据放在堆区,从而使得堆区的数据在子函数执行完成后,仍然可以使用。常见的定义一个指针变量,如 int *p = &a,指针p和其指向的值都放在栈区,不涉及手动释放问题。
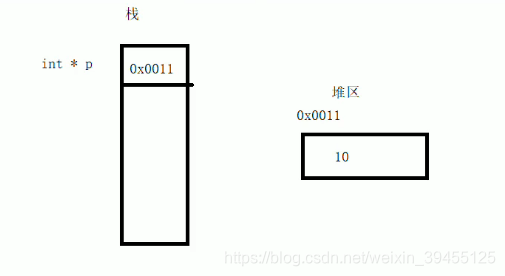

只要堆区的数据在,那么数据和地址都在,那么栈区内指针p的内容就在,所以主函数内再次通过指针p来访问堆区的数据,就是可行的。
补充:new操作符
1) C++中利用new操作符在堆区开辟数据:
语法:new 数据类型
(利用new创建的数据,会返回该数据对应的类型的指针,即返回数据存放的地址)
2)堆区开辟的数据,由程序员手动开辟,手动释放,释放利用操作符 delete


3)在堆区利用new开辟数组:
利用new创建的数据,会返回该数据对应的类型的指针,即返回数据存放的地址。数组也是一样,这里返回连续线性空间的首地址。
(利用指针的指针,可以开辟指针数组,参考哈希表实现中的代码)
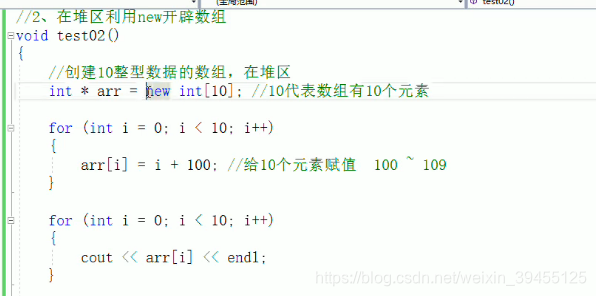
数组名arr本身也是地址,定义一个指针变量arr,指向这块数组内存,也相当于给这个数组内存命名为arr。
即定义一个指针指向数组和直接定义数组名,功能是相同的。
arr[i]和*(arr + i)是一个意思

二、引用
1.引用的作用和内存意义

引用的注意事项:引用时,必须一开始就确定其指向哪一块内存,确定后,其指向的内存地址不再改变,但这一块内存的内容可以变。
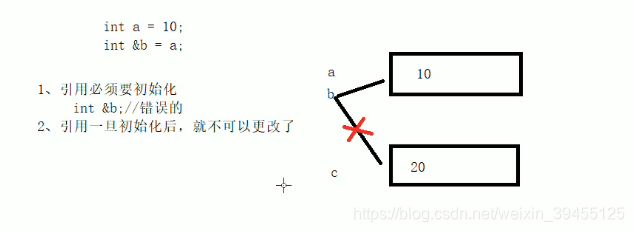
a,b,c,d打印的结果都是10.

2.引用做函数参数
作用:函数传参时,可以利用引用的技术让形参修饰实参,即形参变,实参也变,作用类似于地址传递,但原理不同。
注:上面的a,b是引用,是别名。下面的a,b是原名。即引用时可以使用相同的名字。引用名a,b的值变化了,实参a,b跟着变化。
(值传递是变量作为函数参数,子函数中的形参会另辟开一块内存,复制实参的值,所以形参不会改变实参。而引用作为函数参数,子函数中的形参是实参的别名,不会另辟开一块内存,所以形参会改变实参的值。地址传递作为函数参数,子函数中的形参是实参的地址,也不会另辟开一块内存,形参改变同样会使实参改变。)
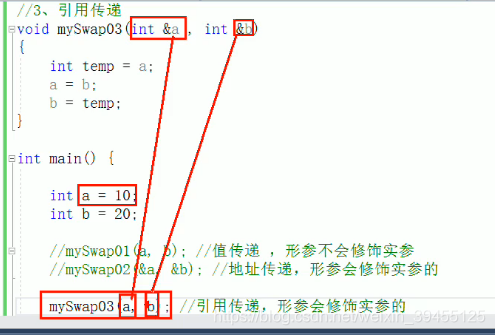
值传递:
定义函数:void mySwap03(int m,int n){}
函数调用:mSwap03(a,b);
解释:在调用时,执行int m=a, int n =b。所以在值传递时,子函数中的形参会另外开辟内存,形参值发生变化不影响实参的值。
引用传递:
定义函数:void mySwap03(int &m,int &n){}
函数调用:mSwap03(a,b);
解释:在调用时,执行int &m=a, int &n =b。在引用传递时,子函数中的形参就是实参的别名,两者指向同一块内存,形参变,实参也变。
引用时,子函数形参名可以和主函数中的实参名相同。
地址传递:
定义函数:void mySwap03(int *m,int *n){}
函数调用:mSwap03(&a,&b);
解释:在调用时,执行int *m=&a, int *n =&b。m和n的值为a,b的地址,*m和*n就是a,b的值,同样指向同一块内存。因此在地址传递时,子函数中的形参m指向的值发生变化,即*m变,实参a也发生变化。
3.引用做函数返回值
引用可以作为函数的返回值,从而可以作为左值再次被赋值。
注意:不要返回局部变量引用,因为局部变量放在栈区,函数执行完成后便释放。因此子函数中的变量前面加上static,变为静态变量,放在全局区。
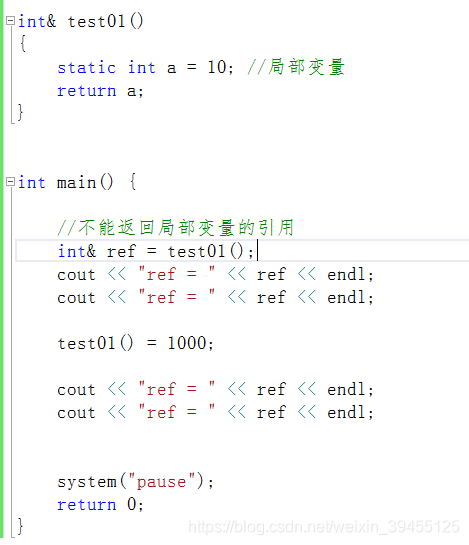
子函数test01()如果前面不加&,表示返回的是一个值,即一个常量,常量不能作为左值。
子函数test01()如果前面加&,表示返回的是一个引用,看做一个变量,变量能作为左值,即函数调用作为左值。
4.引用的本质
引用的本质在c++内部实现是一个指针常量。
(指针常量是指针的指向不可更改,即引用一旦被初始化,就不可以再更改,规定引用是哪个变量的别名后,就不能再更改;但指针指向的值可以更改,即引用可以再次被赋值)

5.常量引用
引用被固定为常量,即引用不再允许被赋值。
作用:“常量引用”主要用来修饰形参,防止误操作。
(在函数形参列表中,可以加const修饰形参,防止形参改变实参)
//引用使用的场景,通常用来修饰形参
void showValue(const int& v) {
//v += 10; //“常量引用”v不允许被修改,此处错误
cout << v << endl;
}
int main() {
//int& ref = 10; 引用本身需要一个合法的内存空间,因此这行错误
//加入const就可以了,编译器优化代码,int temp = 10; const int& ref = temp;
const int& ref = 10; //定义一个“常量引用”ref
//ref = 100; //加入const后不可以修改变量,此处错误
cout << ref << endl;
//子函数中利用“常量引用”防止误操作修改实参
int a = 10;
showValue(a);
system("pause");
return 0;
}
三、函数提高
1 .函数默认参数:
在C++中,函数的形参列表中的形参是可以有默认值的。
语法:返回值类型 函数名 (参数= 默认值){}
注意1: 如果某个位置参数有默认值,那么从这个位置往后,从左向右,必须都要有默认值
注意2: 如果函数声明有默认值,函数实现的时候就不能有默认参数
2.函数占位参数:
C++中函数的形参列表里可以有占位参数,用来做占位,调用函数时必须填补该位置
语法: 返回值类型 函数名 (数据类型){}
3.函数重载:定义不同的函数功能时,函数名可以相同,提高复用性
函数重载满足条件:
同一个作用域下,如全局作用域下
函数名称相同
函数“参数类型不同” 或者 “个数不同” 或者 “顺序不同”
注意事项:
1) 函数的返回值不可以作为函数重载的条件
(返回值类型不同,函数功能完全相同,这也不能作为函数重载)
2)引用作为重载条件:本质属于函数参数的类型不同
3)函数重载碰到函数默认参数:可能碰到二异性,所以尽量避免使用默认参数
四、类和对象
C++面向对象的三大特性为:封装、继承、多态
1.封装
将属性和行为封装成一个类,类的实例化就是对象了,对象就是一个实实在在的实体,性质类似于一个定义好的变量,一个定义好的数组。
类本质是一种数据类型,定义变量时,需要指定数据类型;定义对象时,需要指定类别。
1)类的一般形式
类中包含变量和函数(属性和行为),对象是类的实例化。(可没有函数的实例化,类的实例化很像定义一个结构体变量)
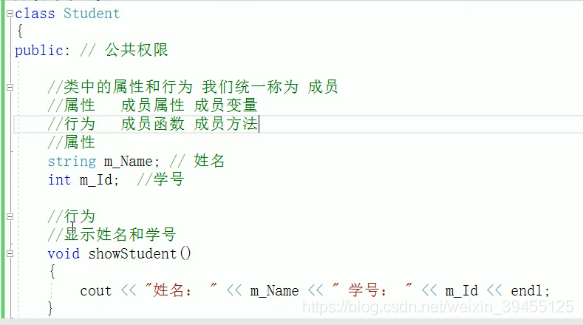
2)类在设计时,可以把属性和行为放在不同的权限下,加以控制
访问权限有三种:
//公共权限 public: 类内可以访问 ,类外可以访问。
//保护权限 protected : 类内可以访问 ,类外不可以访问,子类可以访问父类中的保护内容
//私有权限 private: 类内可以访问 ,类外不可以访问,子类不可以访问父类中的私有内容
类内访问可以认为在封装类时,不管什么权限,都可以使用。
类外访问相当于实例化了一个对象后,该对象不能轻易使用保护权限和私有权限
class Person
{
//姓名 公共权限
public:
string m_Name;
//汽车 保护权限
protected:
string m_Car;
//银行卡密码 私有权限
private:
int m_Password;
public:
void func()
{
m_Name = "张三";
m_Car = "拖拉机";
m_Password = 123456;
}
};
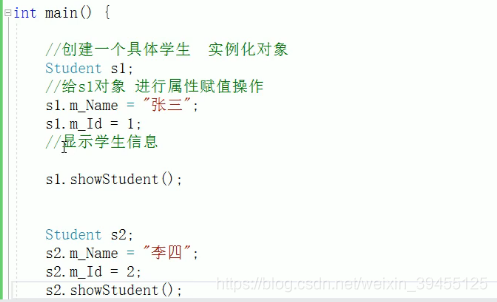
int main() {
Person p; //类的实例化:创建一个对象
p.m_Name = "李四"; //公共权限类内类外都可以访问
//p.m_Car = "奔驰"; //保护权限类外访问不到
//p.m_Password = 123; //私有权限类外访问不到
system("pause");
return 0;
}
3)结构体struct和类class区别: “默认的访问权限不同
区别:struct 默认权限为公共、class 默认权限为私有(不加public情况下),而且结构体中一般不包含成员函数

4)成员属性一般设置为私有
一般将成员属性放在private中,通过在public中定义接口,控制用户对private里的成员属性进行访问,只可读,只可写,可读可写,不可写不可读。
优点:将所有成员属性设置为私有,可以自己控制读写权限
5)类可以作为函数的参数
可以使用引用作为函数参数,以减少内存开销。(如opencv中某个函数的形参为(Mat &image),image就是类对象作为函数参数)
全局函数比较大小,传入两个类;成员函数比较大小,传入一个类即可(一主一客)。
类可以作为另一个类的成员。
类的声明和实现分开写,声明放在.h,具体功能实现放在cpp。
(立方体和点圆关系两个案例,动手敲一遍)
2.对象的初始化和清理
意义:
生活中我们买的电子产品都基本会有出厂设置,在某一天我们不用时候也会删除一些自己信息数据保证安全。C++中的面向对象来源于生活,每个对象也都会有初始设置以及 对象销毁前的清理数据的设置。
1)构造函数和析构函数的作用和定义
都是在类中定义的函数。
对象的初始化和清理也是两个非常重要的安全问题:
一个对象或者变量没有初始状态,对其使用后果是未知。同样的,使用完一个对象或变量,没有及时清理,也会造成一定的安全问题。c++利用了构造函数和析构函数解决上述问题,这两个函数将会被编译器自动调用,完成对象初始化和清理工作。对象的初始化和清理工作是编译器强制要我们做的事情,因此如果我们不提供构造和析构,编译器会提供,编译器提供的构造函数和析构函数是空实现。
构造函数:主要作用在于创建对象时,为对象的成员属性赋值,构造函数由编译器自动调用,无须手动调用。
构造函数语法:类名(){ }
构造函数,没有返回值也不写void
函数名称与类名相同
构造函数可以有参数,因此可以发生重载
程序在调用对象时候会自动调用构造,无须手动调用,而且只会调用一次
析构函数:主要作用在于对象销毁前系统自动调用,执行一些清理工作。
析构函数语法: ~类名(){ }
析构函数,没有返回值也不写void
函数名称与类名相同,在名称前加上符号 ~
析构函数不可以有参数,因此不可以发生重载
程序在对象销毁前会自动调用析构,无须手动调用,而且只会调用一次


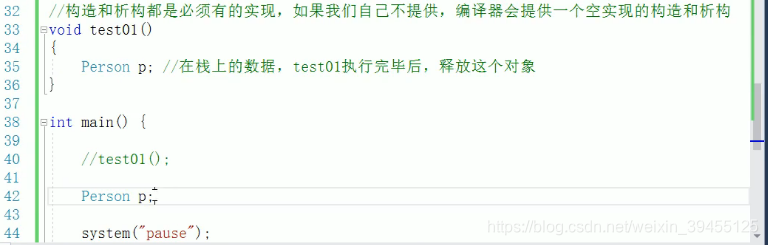
注意:
在子函数中进行类的实例化,即定义了一个局部对象,存放在栈区,当子函数执行完成后,会释放这个对象。(主函数中,执行完子函数后,会在终端显示析构函数打印的内容)-----参考C++内存分区模型之栈区
当在主函数中进行类的实例化,那么由于主函数中system(“pause”)的存在,在按任意键结束之前,主函数始终没有结束,那么这个对象就无法释放,所有终端看不到析构函数打印的内容;当按任意键后,主函数结束,在终端关闭瞬间,出现析构函数打印的内容。
(在主函数中进行类的实例化,即定义一个对象,本质也是局部对象,也是存放在栈区,主函数结束后,对象会被释放)
2)构造函数的分类及调用方式
两种分类方式:
按参数分为: 有参构造和无参构造
按类型分为: 普通构造和拷贝构造(将对象1的所有属性,拷贝到当前对象身上。引用方式传递,且前面加const限制,保证当前对象不对被调用对象的属性进行更改)
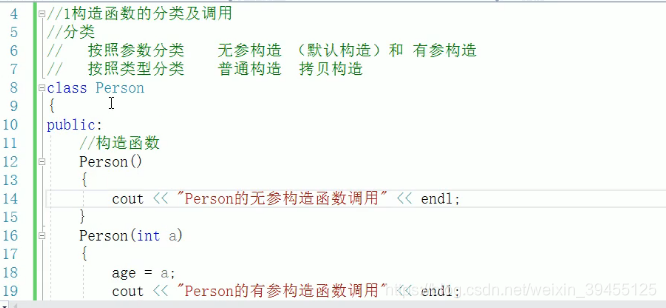

三种调用方式:括号法、 显示法、隐式转换法



补充:构造函数之“拷贝构造函数”调用时机:什么情况下,我们程序会用拷贝构造函数,而不用默认构造函数和有参构造函数。(记住:先创建一个新对象,才会进行对象的初始化,从而才有是否进行调用拷贝构造函数来初始化对象。当然,我们必须保证得有拷贝构造函数,即在类的封装时,我们就定义好了拷贝构造函数,我们不写的话,编译器也会提供一个默认拷贝构造函数)
C++中拷贝构造函数调用时机通常有三种情况:
A:使用一个已经创建完毕的对象来“初始化”一个新对象(构造函数就是来初始化对象的)
B:旧对象作为函数参数,并且采用值传递的方式给函数参数传值。在调用这个子函数时,即会创建一个新对象,此时新对象在初始化时,会调用旧对象里的拷贝构造函数来初始化(对象(类)作为函数参数,性质等同于变量作为函数参数)
C:子函数返回值是个对象,并以值方式返回局部对象,也就是重新拷贝一个对象来返回。那么在调用这个函数时,其实就是创建一个对象,并且这个对象的初始化使用的是拷贝构造函数。
调用拷贝构造函数的时机,都会有一个旧对象可以被使用。
3)构造函数调用规则
默认情况下,只要我们创建一个类,c++编译器至少自动给这个类添加3个函数:
1.默认构造函数(无参,函数体为空)
2.默认析构函数(无参,函数体为空)
3.默认拷贝构造函数,新对象对旧对象的属性进行“值拷贝”(说明我们即使不写拷贝构造函数,编译器也会提供)
构造函数调用规则如下:
1.如果用户定义有参构造函数,c++编译器不在提供“默认无参构造”,但是会提供“默认拷贝构造”。(此时如果调用默认无参构造函数,编译器会报错,因为在用户提供有参和拷贝构造函数时,c++编译器不会再自动提供默认构造函数)
2.如果用户定义拷贝构造函数,c++不会再提供其他构造函数
4)拷贝构造函数之深拷贝与浅拷贝
面试经典问题,也是常见的一个坑。
浅拷贝:简单的赋值拷贝操作。(浅拷贝的问题是,如果拷贝的数据有存放在堆区的,那么在后续使用析构函数,释放数据时,会导致重复释放,即旧对象和新对象都是释放同一块堆区数据,因而拷贝的是指针,而两个指针指向的堆区空间是相同的)
深拷贝:在堆区重新申请空间,进行拷贝操作。(即不仅拷贝了指针,而且重新在堆区申请了空间用于存放数据,即旧对象和新对象,指针和指针指向的空间,都是独立的,因而不存在重复释放)
浅拷贝内存原理:
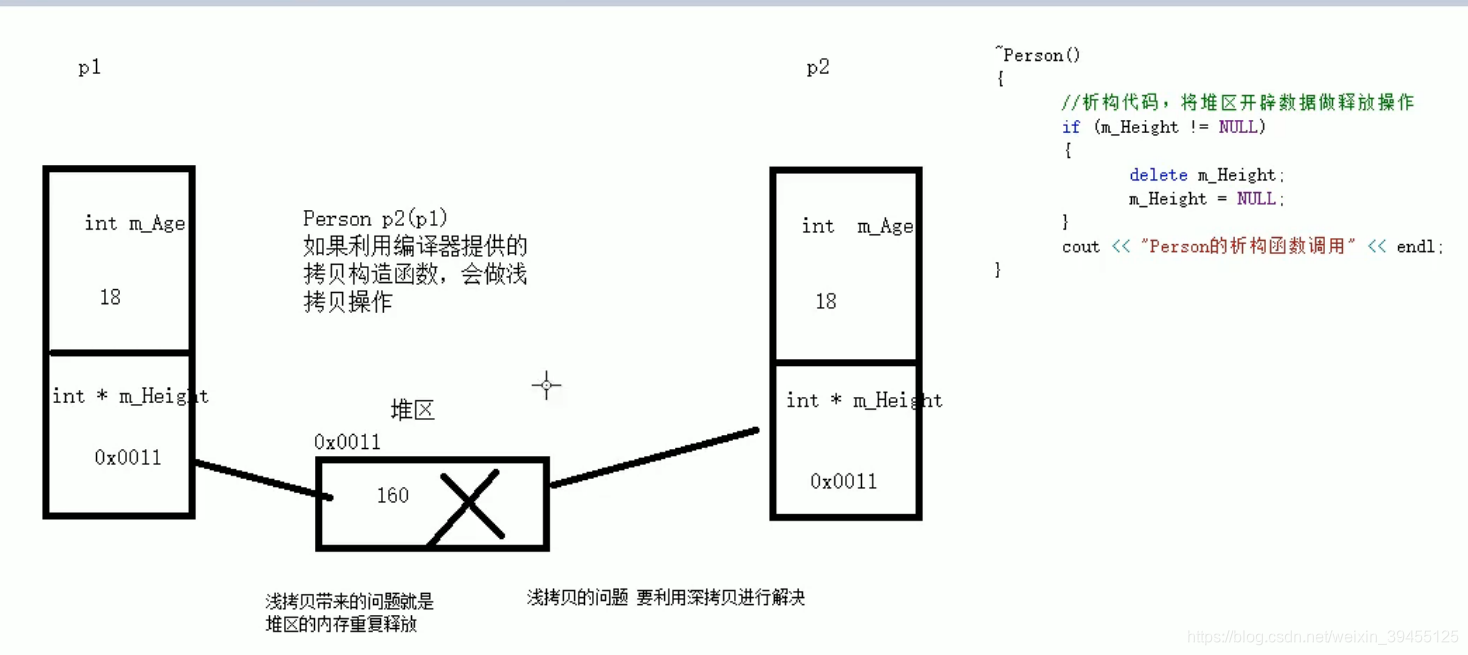
深拷贝内存原理:

那么如何通过实现深拷贝,以此来解决浅拷贝的问题:就是不使用编译器自带的默认拷贝构造函数,程序员自己实现拷贝构造函数

源码:
class Person {
public:
//无参(默认)构造函数
Person() {
cout << "无参构造函数!" << endl;
}
//有参构造函数
Person(int age ,int height) {
cout << "有参构造函数!" << endl;
m_age = age;
m_height = new int(height);
//利用new创建的数据,会返回该数据对应的类型的指针,即返回数据存放的地址
//所以m_height是个指针,指针(地址)放在栈区,指向的数据为height,该数据放在堆区。
//(堆区申请的内存空间需要程序员手动释放,因而这时需要用到析构函数,来手动释放堆区中的数据)
}
//拷贝构造函数
Person(const Person& p) {
cout << "拷贝构造函数!" << endl;
//如果不利用深拷贝在堆区创建新内存,会导致浅拷贝带来的重复释放堆区问题
m_age = p.m_age;
m_height = new int(*p.m_height);
//new int(*p.m_height)意思是,解出指针p.m_height指向的数据,并在堆区重新开辟空间,用于存储此数据,返 回的是该堆区数据的指针,因而m_height是指针
}
//析构函数
~Person() {
cout << "析构函数!" << endl;
//析构代码,将堆区开辟的数据进行释放
if (m_height != NULL) //如果指针m_height不是空指针,那么说明此时指针m_height仍然有指向的值,需要被释放
{
delete m_height; //释放指针指向的内存空间
m_height = NULL //防止野指针存在,将指针置空,强行变成空指针
}
}
public:
int m_age;
int* m_height;
};
void test01()
{
Person p1(18, 180);
Person p2(p1);
cout << "p1的年龄: " << p1.m_age << " 身高: " << *p1.m_height << endl;
cout << "p2的年龄: " << p2.m_age << " 身高: " << *p2.m_height << endl; //*表示解引用,找到指针指向的数据
}
int main() {
test01();
system("pause");
return 0;
}
总结:
浅拷贝就是在初始化新对象时,拷贝了某个对象的指针,且该指针指向的数据放在堆区(通过new创建),而堆区的数据需要程序员手动释放,那么在释放新对象和旧对象时,对同一块内存数据进行了重复释放,故而出错。如果这个指针指向的数据放在栈区,不会出错。因为栈区的数据不需要程序员手动释放,函数执行完成后会自动释放。
所以,浅拷贝就是拷贝了指针,且该指针指向的内容放在堆区。
深拷贝之所以能解决浅拷贝问题,是因为我们并没有拷贝指针,而是解出旧对象的数据,并在新对象中向堆区申请一个新的空间存放它。即new创建一个堆区数据,返回其指针。
5)对象初始化之初始化列表
作用:
C++提供了初始化列表语法,用来初始化对象的属性。传统初始化对象的属性是使用有参构造函数和拷贝构造函数。
语法:构造函数():属性1(值1),属性2(值2)… {}
源码:
class Person {
public:
传统方式初始化
//Person(int a, int b, int c) {
// m_A = a;
// m_B = b;
// m_C = c;
//}
//初始化列表方式初始化
Person(int a, int b, int c) :m_A(a), m_B(b), m_C(c) {}
void PrintPerson() {
cout << "mA:" << m_A << endl;
cout << "mB:" << m_B << endl;
cout << "mC:" << m_C << endl;
}
private:
int m_A;
int m_B;
int m_C;
};
int main() {
Person p(1, 2, 3);
p.PrintPerson();
system("pause");
return 0;
}
6)类对象作为类成员
C++类中的成员可以是另一个类的对象,我们称该成员为 对象成员
例如:
class A {}
class B
{
A a;
}
B类中有对象A作为成员,A为对象成员。
当创建B对象时,A与B的构造和析构的顺序是谁先谁后?
//构造的顺序是 :先调用对象成员的构造,再调用本类构造
//析构顺序与构造相反
class Phone
{
public:
Phone(string name)
{
m_PhoneName = name;
cout << "Phone构造" << endl;
}
~Phone()
{
cout << "Phone析构" << endl;
}
string m_PhoneName;
};
class Person
{
public:
//初始化列表可以告诉编译器调用哪一个构造函数
Person(string name, string pName) :m_Name(name), m_Phone(pName)
{
cout << "Person构造" << endl;
}
~Person()
{
cout << "Person析构" << endl;
}
void playGame()
{
cout << m_Name << " 使用" << m_Phone.m_PhoneName << " 牌手机! " << endl;
}
string m_Name;
Phone m_Phone;
};
void test01()
{
Person p("张三" , "苹果X");
p.playGame();
}
int main() {
test01();
system("pause");
return 0;
}
7)类对象之静态成员
成员是属于类中的一个词,变量和函数都是类中的成员。
静态成员就是在成员变量和成员函数前加上关键字static,称为静态成员。
静态成员放在全局区。
静态成员分为:
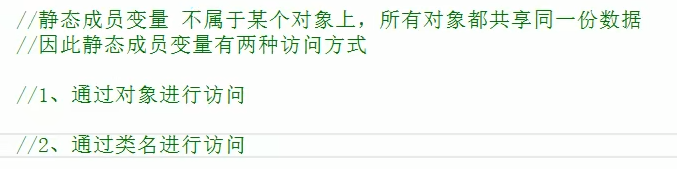
1.静态成员变量:
#所有对象共享同一份数据
#在编译阶段分配内存
#类内声明,类外初始化(定义)(https://www.cnblogs.com/ceason/articles/12852889.html)
2.静态成员函数
#所有对象共享同一个函数
#静态成员函数只能访问静态成员变量
静态成员的作用:
由于C+ + 类中的静态成员,不属于某个对象上,而是所有对象共享同一份。所以,多个对象实例之间可以进行 通 信,传 递信息。
例1:静态成员变量
class Person
{
public:
static int m_A; //静态成员变量:类内声明(在类中,这样写只是声明了静态变量,并没有定义)
//静态成员变量特点:
//1 在编译阶段分配内存
//2 类内声明,类外初始化
//3 所有对象共享同一份数据
private:
static int m_B; //静态成员变量也是有访问权限的
};
int Person::m_A = 10; //类Person作用域下的静态成员变量:类外初始化(在创建类对象之前,应该完成静态成员变量的初始化)
int Person::m_B = 10;
void test01()//测试案例
{
//静态成员变量两种访问方式
//1、通过对象
Person p1;
p1.m_A = 100;
cout << "p1.m_A = " << p1.m_A << endl;
Person p2;
p2.m_A = 200;
cout << "p1.m_A = " << p1.m_A << endl; //共享同一份数据
cout << "p2.m_A = " << p2.m_A << endl;
//2、通过类名:之所以能通过类名访问静态变量,就是因为它不属于某一个对象,而是所有对象共享
cout << "m_A = " << Person::m_A << endl;
//cout << "m_B = " << Person::m_B << endl; //私有权限访问不到
}
int main() {
test01();//调用测试案例
system("pause");
return 0;
}
例2:静态成员函数
class Person
{
public:
//静态成员函数特点:
//1 程序共享一个函数
//2 静态成员函数只能访问静态成员变量
static void func()
{
cout << "func调用" << endl;
m_A = 100;
//m_B = 100; //错误,静态成员函数不可以访问非静态成员变量
}
static int m_A; //静态成员变量
int m_B; // 非静态成员变量
private:
//静态成员函数也是有访问权限的
static void func2()
{
cout << "func2调用" << endl;
}
};
int Person::m_A = 10; //类Person作用域下的静态成员变量m_A:类外初始化
void test01() //测试案例
{
//静态成员函数两种访问方式
//1、通过对象
Person p1;
p1.func();
//2、通过类名
Person::func();
//Person::func2(); //私有权限访问不到
}
int main() {
test01(); //调用测试案例,验证静态成员函数的特点
system("pause");
return 0;
}
3.C++对象模型和this指针
1) 成员变量和成员函数分开存储
在C++中,类内的成员变量和成员函数分开存储
只有非静态成员变量才属于类的对象上,即统计某个类对象占多大的内存时,只有该对象内的“非静态成员变量”才占其内存,静态成员变量,静态成员函数,非静态成员函数都不属于该对象,不占该对象的内存。


2)this指针概念
this指针只能在非静态成员函数内进行使用。
就是我们在封装一个类时,对于该类的非静态成员函数,我们可以在这样的函数里面使用this指针。
1.this指针的存在意义?
答:
解决非静态成员函数只有一份实例的问题,从而让非静态成员函数知道当前时刻哪一个对象在调用自己。
通过1),我们知道C++中成员变量和成员函数是分开存储的。
每一个非静态成员函数只会诞生一份函数实例,即只占一份内存,也就是说多个同类型的对象在调用非静态成员函数时,会共用一块代码,共用一块内存。
2.this指针如何区分哪个对象正在调用非静态成员函数?
答:
this指针是隐含每一个非静态成员函数内的一种指针,因此在非静态成员函数内部,我们可以使用该指针。this指针不需要定义,直接使用即可。
this指针也叫对象指针。this指针指向的值是,被调用的成员函数所属的对象,即谁调用类中的非静态成员函数,this指针就指向谁。
(指针的指向是指针变量p保存的内容,即地址;指针指向的值是以地址(指针的指向)来寻址得到的内容。)
3.this指针的用途?
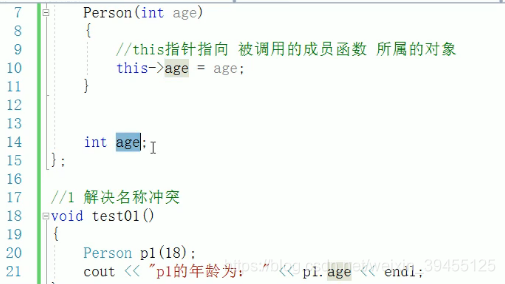
答:
当类中非静态成员函数的形参和类中的成员变量同名时,可用this指针来区分:这里this->age其实也是类中成员变量中的age,并不是形参age。尽管类中成员变量和形参同名了,但是使用this指针后,便可以进行赋值操作,否则,同名赋值,识别不出类中成员变量的age。
4.this指针的本质
答:this指针本质是指针常量,指针的指向不可以修改,即我们规定this指针指向的对象后,我们不可以再给this指针赋其他地址,如this->NULL是非法的。但指针指向的值是可以修改的,即我们可以这样做this->m_age = 10。
在类的非静态成员函数中,返回对象本身,可使用return *this
问题:
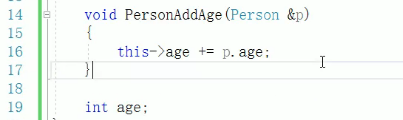
这里由于函数PersonAddAge()的返回值是空,因此对象p2在调用此函数后,返回值为空,就不能再叠加调用此函数,或其他属性和方法。即p2.PersonAddAge(p1)后面就无效了。
解决办法:
如果对象p2在调用此函数后,返回值不为空,而仍然是对象,那么后续便可无限调用此函数。因此需要将函数PersonAddAge()的返回值设置为对象。对于类中的非静态成员函数,我们返回this指针指向的值,就是让函数返回了对象。
解决源码:
class Person
{
public:
Person(int age)
{
//1、当形参和成员变量同名时,可用this指针来区分
this->age = age;
}
Person& PersonAddPerson(Person p) 返回本体,需要用引用的方式返回。如果采用值返回,会重新拷贝一个对象,即返回的就不是p2了,而是一个新对象。
{
this->age += p.age;
//返回对象本身:this指针的指向是p2的指针(对象p2的地址),故*this就是对象p2的本体(即this指针的指向是对象p2的地址,this指针指向的值是对象p2的本体)
return *this;
}
int age;
};
void test01()
{
Person p1(10);
cout << "p1.age = " << p1.age << endl;
Person p2(10);
p2.PersonAddPerson(p1).PersonAddPerson(p1).PersonAddPerson(p1);//链式编程思想
cout << "p2.age = " << p2.age << endl;//这也是链式编程思想
}
int main() {
test01();
system("pause");
return 0;
}
注:不采用引用返回,而采用值返回的结果:
(子函数返回值是个对象,并以值方式返回局部对象,也就是重新拷贝一个对象来返回。那么在调用这个函数时,其实就是创建一个对象,并且这个对象的初始化使用的是拷贝构造函数。)
所以p2’、p2’‘、p2’''这三个新对象会进行初始化,调用拷贝构造函数,初始化的年龄也是10。后面每个对象再使用类中非静态成员函数PersonAddAge()后,每个对象的年龄都是20岁。
3)空指针访问成员函数
我们在访问类中的成员函数时,除了使用“对象+函数”的方法(如p2.func())来调用成员函数,也可以使用空指针调用成员函数。因此我们可以定义一个空指针,指针的数据类型为类,使用该空指针即可访问对象中的成员函数。
(注意:定义一个数据类型为类的空指针,实质上并没有创建一个对象实体,因为指针的指向为空,指针指向的值并非是一个对象实体)
但是也要注意有没有用到this指针,如果用到this指针,需要加以判断保证代码的健壮性。
源码分析:
//空指针访问成员函数
class Person {
public:
void ShowClassName() { //成员函数:显示类名
cout << "我是Person类!" << endl;
}
void ShowPerson() { //成员函数:打印年龄
if (this == NULL) { //如果我们传入的指针是空,函数直接结束,不会执行下面的语句,提高代码的健壮性
return;
}
cout << mAge << endl;
//此语句的本质为cout << this->mAge << endl(表示这是当前对象的属性,this是确切对象的指针,当我们传入的指针是空,是不能访问属性的)
}
public:
int mAge;
};
void test01()
{
Person * p = NULL; //定义的空指针,可以用于调用类中的成员函数
p->ShowClassName(); //空指针,可以调用成员函数
p->ShowPerson(); //但是如果成员函数中用到了this指针,就不可以了
}
int main() {
test01();
system("pause");
return 0;
}
4)const修饰成员函数

目的是让类中的函数,不能轻易访问类中的属性。(不加const,在同一个权限下,类中的函数是可以访问类中的属性的)
成员函数没有用const修饰:类中成员函数可以访问类中成员属性

写在之前:了解this指着的本质

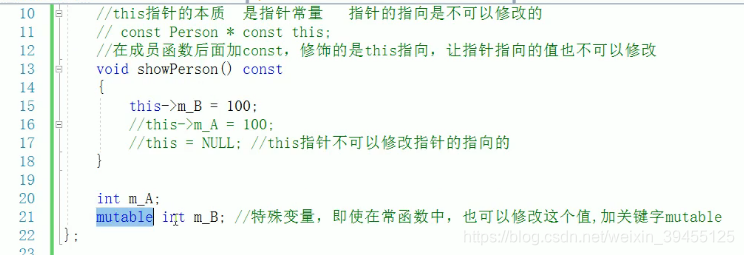
this指针加const后:表示这个指针的指向,和这个指针指向的值,都被固定死,都不允许修改了。

1.常函数:
成员函数后面加const:我们称为这个函数为常函数
常函数内不可以修改成员属性(即在常函数内部不可以操作成员属性)

成员属性声明时,加关键字mutable后,我们就又可以在常函数中修改成员属性(因此这里成员属性m_A不可以修改,m_B可以修改)
2.常对象:常对象不可以修改普通的成员属性,也不能调用普通的成员函数。只能调用特殊变量和常函数。
声明对象前加const称该对象为常对象
常对象只能调用常函数

4.友元
就是让一个函数或者类 能够访问另一个类中私有成员
在程序里,类中的私有属性,是不允许类外的函数和其它类进行访问的。 但为了让类外特殊的一些函数或者其它类进行访问,就需要用到友元的技术。
友元的关键字为 friend
友元的三种实现:全局函数做友元、类做友元、成员函数做友元
源码1:全局函数做友元:全局函数可以访问一个类中的私有属性
class Building
{
//告诉编译器 goodGay全局函数 是 Building类的好朋友,可以访问类中的私有内容
friend void goodGay(Building * building);
public:
Building() //构造函数,在类的实例化中,进行对象初始化
{
this->m_SittingRoom = "客厅";
this->m_BedRoom = "卧室";
}
public: //类的公共属性,类外可以访问
string m_SittingRoom; //客厅
private: //类的私有属性,一般不允许类外访问
string m_BedRoom; //卧室
};
void goodGay(Building * building)//全局对象
{
cout << "好基友正在访问: " << building->m_SittingRoom << endl;
cout << "好基友正在访问: " << building->m_BedRoom << endl;
}
void test01()
{
Building b; //类的实例化,创建一个类为Building的对象(创建对象时,会自动进行初始化)
goodGay(&b); //通过指针传递对象(地址传递)
}
int main(){
test01();
system("pause");
return 0;
}
源码2:类做友元:一个类可以访问另一个类中的私有属性
class Building;//类的声明
class goodGay
{
public:
goodGay();
void visit(); //参观函数,访问building类中的属性
private:
Building *building;
};
class Building
{
//告诉编译器 goodGay类是Building类的好朋友,可以访问到Building类中私有内容
friend class goodGay;
public:
Building();
public:
string m_SittingRoom; //客厅
private:
string m_BedRoom;//卧室
};
Building::Building() //类外实现类中的函数,从而将类中成员函数声明和实现分开
{
this->m_SittingRoom = "客厅";
this->m_BedRoom = "卧室";
}
goodGay::goodGay()
{
building = new Building;//在堆区创建一个building对象,返回指针
}
void goodGay::visit()
{
cout << "好基友正在访问" << building->m_SittingRoom << endl;
cout << "好基友正在访问" << building->m_BedRoom << endl;
}
void test01()
{
goodGay gg; //创建一个goodgay对象gg
gg.visit();//调用对象gg里面的成员函数
}
int main(){
test01();
system("pause");
return 0;
}
源码3:成员函数做友元:一个类中的成员函数,可以访问另一个类中的私有属性。
(一个类中的某个函数可以访问另一个类中的私有属性,而不是整个类都可以访问另一个类的私有属性)
class Building;
class goodGay
{
public:
goodGay();
void visit(); //只让visit函数作为Building的好朋友,可以发访问Building中私有内容
void visit2(); //visit2函数不允许访问building类中的私有属性
private:
Building *building;
};
class Building
{
//告诉编译器 goodGay类中的visit成员函数 是Building好朋友,可以访问私有内容
friend void goodGay::visit();
public:
Building();
public:
string m_SittingRoom; //客厅
private:
string m_BedRoom;//卧室
};
Building::Building() //类Building的构造函数
{
this->m_SittingRoom = "客厅";
this->m_BedRoom = "卧室";
}
goodGay::goodGay() //类goodGay的构造函数
{
building = new Building; //在类对象goodGay初始化时,在堆区创建了一个building对象,并使用一个指针变量维护它。
//由于指针building已经在类中定义,这里相当于给指针赋值。new Building意思是创建一个类对象Building,并返回它的地址。地址值赋给指针变量Building
}
void goodGay::visit()
{
cout << "好基友正在访问" << building->m_SittingRoom << endl;
cout << "好基友正在访问" << building->m_BedRoom << endl;
}
void goodGay::visit2()
{
cout << "好基友正在访问" << building->m_SittingRoom << endl;
//cout << "好基友正在访问" << building->m_BedRoom << endl;
}
void test01()
{
goodGay gg;
gg.visit();
}
int main(){
test01();
system("pause");
return 0;
}
技巧:类内声明成员函数,类外实现成员函数功能
5.运算符重载
概念:对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型。
编译器定义了运算符重载函数名,我们实现其函数内部功能。从而使得运算符不仅可以处理内置数据类型,还可以处理自定义的数据类型。
当我们在后续让两个自定义数据类型的数据,进行运算符操作时,会自动调用编译器的函数operator来实现。
重载后的运算符是处理自定义数据类型的,即编译器在遇到自定义数据类型时,会自动调用。而对于编译器内置的数据类型,仍然正常处理,两者互不影响。
运算符重载函数定义在类中,为某个类的成员函数,因为自定义的数据类型也是在类中实现的。
1)加号运算符重载
成员函数实现重载加号,全局函数实现重载加号
作用:实现两个自定义数据类型相加的运算

1.成员函数实现重载加号:
要实现加号重载,且在类中的成员函数实现,就是需要在类中定义一个成员函数,来实现自定义数据的加法运算。这里实现两个类相加,把两个类中的成员属性对应相加。
由于是成员函数实现重载加号,因此只需要传入一个类即可。由于实现的是两个类的相加,成员函数的返回值是个对象,该对象将对象1和对象2进行了相加。

2.全局函数实现重载加号:重载的本质是加法的对象和加法的结果都是相同的数据类型,如两个类相加,结果返回仍是一个类。
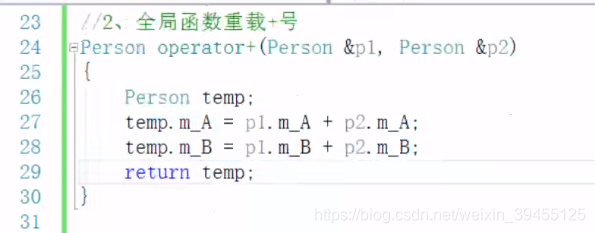

补充:运算符重载,也可以发生函数重载。即运算符重载函数operator可以同名,但因为传入的形参不同,导致功能也不同。

注意:
总结1:对于内置的数据类型的表达式的的运算符是不可能改变的
总结2:不要滥用运算符重载
2)左移运算符重载
作用:可以输出自定义数据类型。
(未经重载的左移运算符<<,只能输出内置的数据类型)
重载后的左移运算符和未经重载的左移运算符区别:

注意:
cout是一个类对象,是由标准库中ostream这个类,所创建的对象。
cout这个对象,全局只有一个,只能用引用的方式。返回的仍然是对象cout,以便后面可以继续输出(链式编程)
由于采用引用的方式返回对象,这里的全局函数中cout 可以是其他符号,如out,因为引用就是起别名,别名out和原名cout可以不一致。

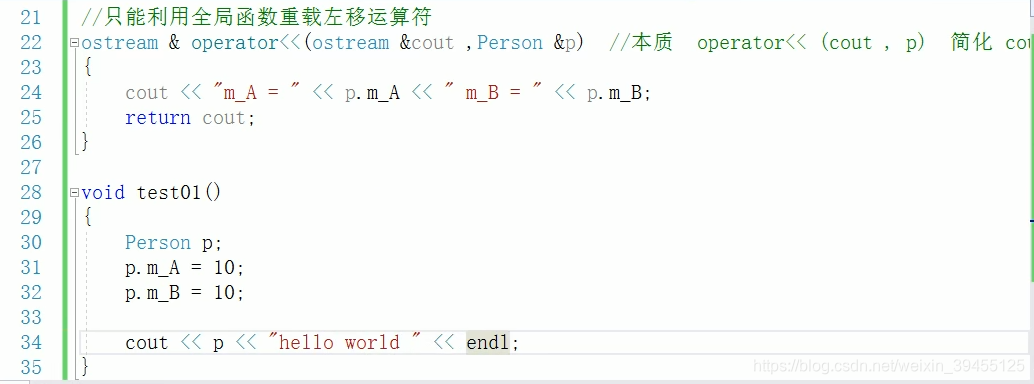
3)递增运算符重载
作用: 通过重载递增运算符,实现自己的整型数据。
++a是a先自身加1,再作为表达式的值进行运算;
a++是a先作为表达式的值进行运算,再自身加1。

//MyInteger是自定义数据类型(其实是个类),myInt是个自定义数据类型的变量。
源码分析:
//自定义数据类型
class MyInteger {
friend ostream& operator<<(ostream& out, MyInteger myint);//友元技术允许类外访问类内的私有属性
public:
MyInteger() {
m_Num = 0;
}
//前置++
//如果采用值返回,而不是引用返回:子函数返回值是个对象,并以值方式返
//回局部对象,也就是重新拷贝一个对象来返回。
//那么在调用这个函数时,其实就是创建一个对象,并且这个对象的初始化使
//用的是拷贝构造函数,拷贝前对象的属性。
拷贝构造函数的深度说明:
//将对象1的所有属性,拷贝到当前对象身上。引用方式传递,且前面加const
//限制,保证当前对象不对被调用对象的属性进行更改。
//调用拷贝构造函数(这里是编译器自带的默认拷贝构造函数,其实存在浅拷
//贝问题,即拷贝的数据如果存放在堆区,那么我们会拷贝指针,导致新对象
//和旧对象在析构时,都会对内存释放,从而导致内存重复释放),调用的是
//拷贝构造函数,而不是默认构造函数,所以新对象的m_Num初值就是1,而不是0。
//所以,如果这里采用值返回,那么会新创建一个对象(这里假设为myInt_1),对象的属性m_Num=1。
//即我们如果对其再自加,即再调用此函数,那么操作的对象不在是原先的对象myInt,而是myInt_1,
//虽然处理后m_Num也是2,但是原理不同。这也是语句++(++myInt)的含义,该语句最终又返回一个新对象myInt_2。
//所以返回引用,是为了对一个对象进行操作
MyInteger& operator++() {
//先++
m_Num++;
//再返回
return *this; //返回自身对象
}
//后置++
MyInteger operator++(int) { //int表示占位参数,用于区分函数重载
//先返回
MyInteger temp = *this; //记录当前本身的值,然后让本身的值加1,但是返回的是以前的值,达到先返回后++;
m_Num++;
return temp; //返回之前记录的值,从而相当于先返回,再自加
//由于temp是个局部对象,因此我们不能引用返回此对象,否则会在该operator++(int)函数执行完,对象temp就被释放了,
后续对其的操作都属于非法操作。
//因此我们采用值返回,直接拷贝一个对象出来。值返回的缺点是不能链式操作,因此后置++不能像前置++那样操作。
}
private:
int m_Num; //类的私有属性不允许类外访问,可以通过友元技术访问
};
//重载左移运算符<<
ostream& operator<<(ostream& out, MyInteger myint) {
out << myint.m_Num;
return out;
}
//前置++ 先++ 再返回
//test01函数里面代码的含义:首先,创建了一个类为MyInteger的对象myInt;
//然后执行 ++myInt,这是调用“前置自身加1函数”operator++(),对该对象myInt中的成员属性m_Num加1,
//且“前置自身加1函数”operator++()的返回值仍然是这个对象(引用返回),只不过m_Num值比之前加了1。
//(第二步必须返回一个对象,因为第三步要用到这个对象)。
//最后,执行cout << 前置自加后的myInt,此时会调用“重载左移运算符函数”operator<<(),对该对象myInt中的m_Num值进行输出。
void test01() {
MyInteger myInt;
cout << ++myInt << endl; //要输出自定义数据类型的值,必须先进行左移运算符重载,因为编译器的左移运算符识别不出我们自定义的数据类型。
cout << myInt << endl; //此处的对象 myInt为最开始的MyInteger myInt中的myInt。
}
//后置++ 先返回 再++
void test02() {
MyInteger myInt;
cout << myInt++ << endl;
cout << myInt << endl;
}
int main() {
test01();
//test02();
system("pause");
return 0;
}
注意:主函数在执行子函数test01()是,第一个cout为2,第二个cout为1。原理解释参考源码解析

4)赋值运算符重载
c++编译器至少给一个类添加4个函数
默认构造函数(无参,函数体为空)
默认析构函数(无参,函数体为空)
默认拷贝构造函数,对属性进行值拷贝
赋值运算符 operator=, 对属性进行值拷贝
如果类中有属性指向堆区,做赋值操作时也会出现深浅拷贝问题。
为了解决这个问题,我们需要自己写拷贝构造函数,也可以通过在类中写一个函数,实现赋值运算符重载,来实现深拷贝。
从而实现在对象之间进行赋值时,避免浅拷贝带来的内存重复释放问题。


重载赋值运算符的意义:对于自定义数据类型(自己定义的类),对象之间进行赋值时,可以自动解决浅拷贝的问题,从而我们可以使用编译器自带的拷贝构造函数。
5)关系运算符重载
==与!=
作用:重载关系运算符,可以让两个自定义类型对象进行对比操作

重载 == 号
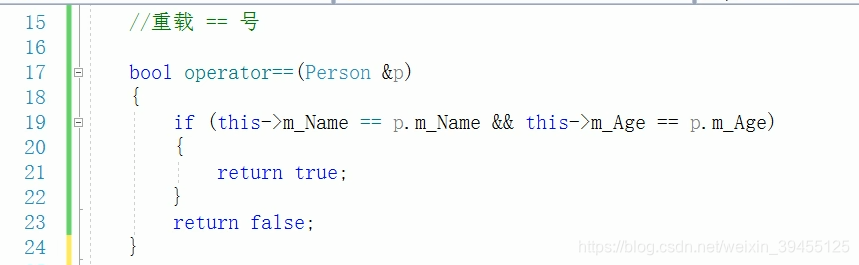
重载 != 号
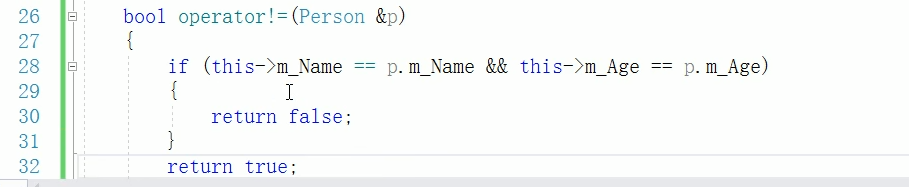
6)“函数调用运算符”重载
小括号()也可以重载
函数调用运算符 () 也可以重载
由于重载后使用的方式非常像函数的调用,因此称为仿函数
仿函数没有固定写法,非常灵活
源码分析:
class MyPrint
{
public:
void operator()(string text) //函数运算符()重载
{
cout << text << endl;
}
};
void test01()
{
//重载的()操作符 也称为仿函数
MyPrint myFunc;
myFunc("hello world"); //重载后的(),使用非常像函数调用,但注意此时我们并没有定义一个函数来打印字符串,所以这里是重载技术。
}
class MyAdd
{
public:
int operator()(int v1, int v2)
{
return v1 + v2;
}
};
void test02()
{
MyAdd add;
int ret = add(10, 10);
cout << "ret = " << ret << endl;
//匿名函数对象 :MyAdd()是匿名对象,后面(100,100)是使用重载“函数运算符",所以整个叫匿名函数对象
cout << "MyAdd()(100,100) = " << MyAdd()(100, 100) << endl;
}
int main() {
test01();
test02();
system("pause");
return 0;
}
6.继承
继承是面向对象三大特性之一
1)继承概念
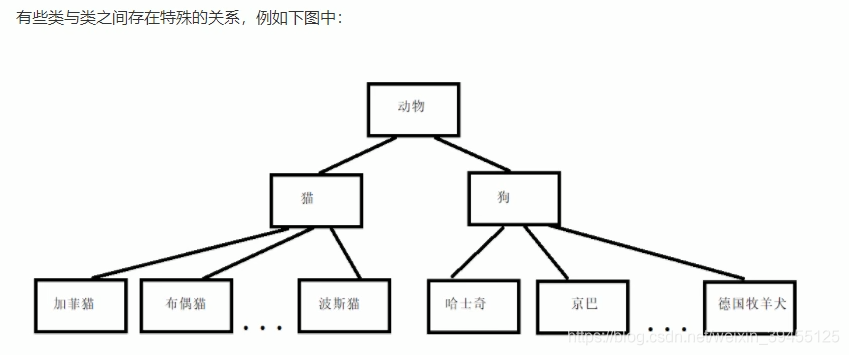
继承的好处:可以减少重复的代码
语法介绍: class A : public B;
A 类称为子类 或 派生类;
B 类称为父类 或 基类;
public为继承方式;
派生类中的成员,包含两大部分:
一类是从基类继承过来的,一类是自己增加的成员。
从基类继承过过来的表现其共性,而新增的成员体现了其个性。
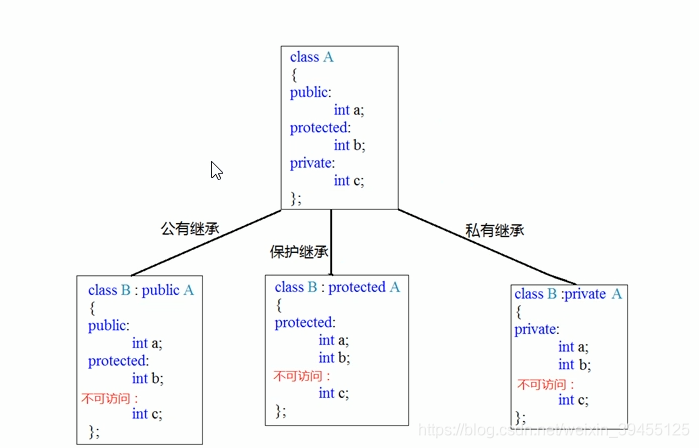
2)继承方式
继承的语法:class 子类 : 继承方式 父类
继承方式一共有三种:公共继承、保护继承、私有继承
父类:class A,有公共权限,保护权限,私有权限。
子类:class B,有三种继承方式,即公共继承,保护继承,私有继承
如果采用公共继承方式,会将父类A中的公共权限和保护权限原样继承下来,父类的私有权限不能用。
如果采用保护继承方式,会将父类A中的公共权限和保护权限继承都继承为保护权限,父类的私有权限不能用。那么子类B就没有了公共权限。
如果采用私有继承方式,会将父类A中的公共权限和保护权限继承都继承为私有权限,父类的私有权限不仍然能用。那么子类B就没有了公共权限和保护权限。
3)继承中的对象模型
从父类继承过来的成员,哪些属于子类对象?即子类对象中,哪些属性属于从父类继承来的,哪些属性是子类自己的。


查看方式:

注: 父类中所有非静态成员属性都会被子类继承下去,即父类中私有成员也是被子类继承下去了,只是由编译器给隐藏后,访问不到。
因此,子类从父类中继承的非静态成员属性,是占子类内存的。
4) 继承中构造和析构顺序
子类继承父类后,当创建子类对象,也会调用父类的构造函数。那么父类和子类的构造和析构顺序是谁先谁后?
注:继承中 先调用父类构造函数,再调用子类构造函数,析构顺序与构造相反
5)继承同名非静态成员处理方式
问题:当子类与父类出现同名的成员,包括成员属性和成员函数。如何通过子类对象,访问到子类或父类中同名的成员呢?
总结:
子类对象可以直接访问到子类中同名成员
子类对象加父类的作用域可以访问到父类同名成员
当子类与父类拥有同名的成员函数,子类会隐藏父类中所有同名成员函数
(当父类中成员函数有重载时,都会被子类对象的同名成员函数隐藏),加作用域可以访问到父类中同名函数。
6)继承同名静态成员处理方式
问题:继承中同名的静态成员在子类对象上如何进行访问?
静态成员和非静态成员出现同名,处理方式一致
访问子类同名成员 直接访问即可
访问父类同名成员 需要加作用域
源码分析:
class Base {
public:
static void func()
{
cout << "Base - static void func()" << endl;
}
static void func(int a)
{
cout << "Base - static void func(int a)" << endl;
}
static int m_A; //父类静态成员属性:类内声明
};
int Base::m_A = 100; //类外初始化
class Son : public Base {
public:
static void func()
{
cout << "Son - static void func()" << endl;
}
static int m_A; //子类静态成员属性:类内声明
};
int Son::m_A = 200; //类外初始化
//静态成员有两种访问方式:通过对象访问、通过类名访问
//同名静态成员属性
void test01()
{
//1.通过对象访问
cout << "通过对象访问: " << endl;
Son s;
cout << "Son 下 m_A = " << s.m_A << endl;
cout << "Base 下 m_A = " << s.Base::m_A << endl;
//2.通过类名访问
cout << "通过类名访问: " << endl;
cout << "Son 下 m_A = " << Son::m_A << endl;
cout << "Base 下 m_A = " << Son::Base::m_A << endl;
//第一个::代表通过类名访问静态成员属性;第二个::代表访问父类作用域下的 成员属性
}
//同名成员函数
void test02()
{
//1.通过对象访问
cout << "通过对象访问: " << endl;
Son s;
s.func();
s.Base::func();
//2.通过类名访问
cout << "通过类名访问: " << endl;
Son::func();
Son::Base::func();
//出现同名,子类会隐藏掉父类中所有同名成员函数,需要加作作用域访问
Son::Base::func(100);
}
int main() {
//test01();
test02();
system("pause");
return 0;
}
7)多继承
含义:C++允许一个类继承多个类,即子类可以继承多个父类。
语法:class 子类 :继承方式 父类1 , 继承方式 父类2…
问题:多继承可能会引发父类中有同名成员出现,需要加作用域区分
注意:C++实际开发中不建议用多继承
8)菱形继承
菱形继承概念:两个派生类继承同一个基类,又有某个类同时继承者两个派生类,这种继承被称为菱形继承,或者钻石继承。
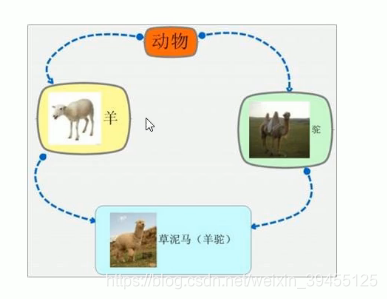
菱形继承问题:
羊继承了动物的数据,驼同样继承了动物的数据,当草泥马使用数据时,就会产生二义性。
草泥马继承自动物的数据继承了两份,其实我们应该清楚,这份数据我们只需要一份就可以,子类继承两份相同的数据,导致资源浪费以及毫无意义。
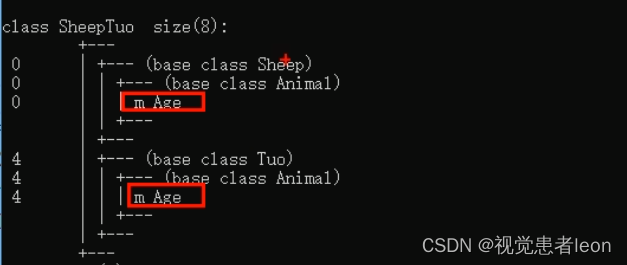
从上面可见,菱形继承确实使得草泥马类继承了两份数据,产生了资源浪费。
解决:
使用加父类作用域解决访问二义性问题,但这样存在两份数据,会消耗多余的资源
利用虚继承可以解决菱形继承问题,即解决访问二义性问题,也避免了资源消耗。


菱形继承的底层解释:
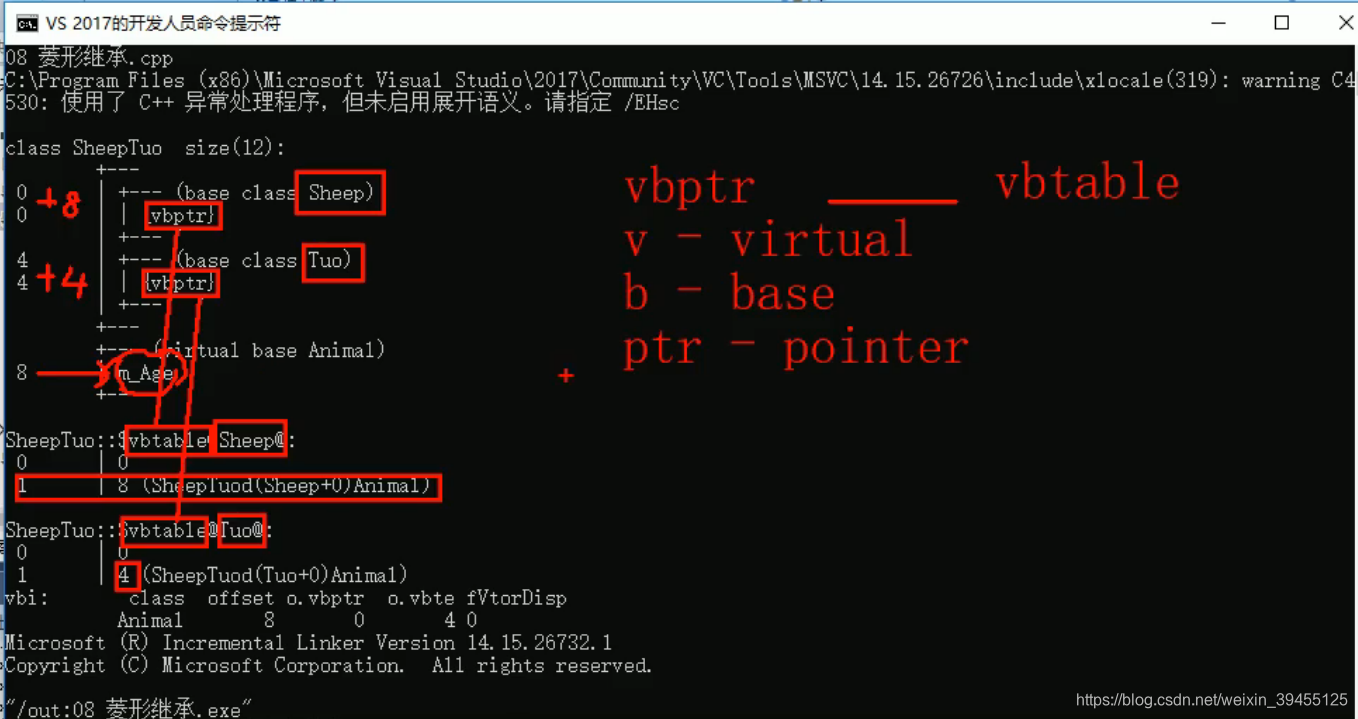
通过虚继承,生成虚基类指针,指向m_Age。
两个子类采用虚继承基类,各自生成的虚基类指针,都指向一个m_Age,那么两个子类就共享了一份m_Age。
因此,草泥马在继承这两个子类时,就只继承一份数据了。
7.多态
多态是C++面向对象三大特性之一
1 )多态的基本概念
多态的概念:
多态就是某种事物具有多种形态,比如函数重载中,一个函数具有不同的功能;运算符重载时,一个加号运算符具有不同的含义。即根据不同条件,某种事物有不同的表示形态。
多态分为两类:
1.静态多态: 函数重载 和 运算符重载属于静态多态,复用函数名
2.动态多态: 派生类和虚函数,实现运行时多态
静态多态和动态多态区别:
1.静态多态的函数地址早绑定 - 编译阶段确定函数地址
2.动态多态的函数地址晚绑定 - 运行阶段确定函数地址
源码解析动态多态的含义:
class Animal
{
public:
//Speak函数就是虚函数
//函数前面加上virtual关键字,变成虚函数,那么编译器在编译的时候就不能确定函数调用了,即晚绑定。
//如果函数前不加上virtual关键字,编译器在编译的时候就绑定函数地址,即早绑定。
virtual void speak()
{
cout << "动物在说话" << endl;
}
};
class Cat :public Animal
{
public:
void speak()
{
cout << "小猫在说话" << endl;
}
};
class Dog :public Animal
{
public:
void speak()
{
cout << "小狗在说话" << endl;
}
};
//我们希望传入什么对象,那么就调用什么对象的函数
//如果函数地址在编译阶段就能确定,那么静态联编
//如果函数地址在运行阶段才能确定,就是动态联编
void DoSpeak(Animal & animal) //Animal & animal = cat;
// C++中允许父类子类的数据类型转换(这里父类数据类型为Animal,子类数据类型为Cat),不需要强制转换,所以相当于Cat & animal = cat
{
animal.speak();
}
//
//多态满足条件:
//1、有继承关系
//2、子类重写父类中的虚函数,不然没有可调用的子类函数
//多态使用:
//父类指针或引用指向子类对象
void test01()
{
Cat cat;
DoSpeak(cat); //实参是子类对象,DoSpeak()函数形参是父类引用,此条语句的含义是,“父类的引用”指向“子类的对象”
Dog dog;
DoSpeak(dog);
}
int main() {
test01();
system("pause");
return 0;
}
总结:
1.多态满足条件:
有继承关系
子类重写父类中的虚函数
2.多态使用条件
父类指针或引用,指向子类对象
函数重写:函数返回值类型 函数名 参数列表 完全一致称为重写
2)多态的底层解析
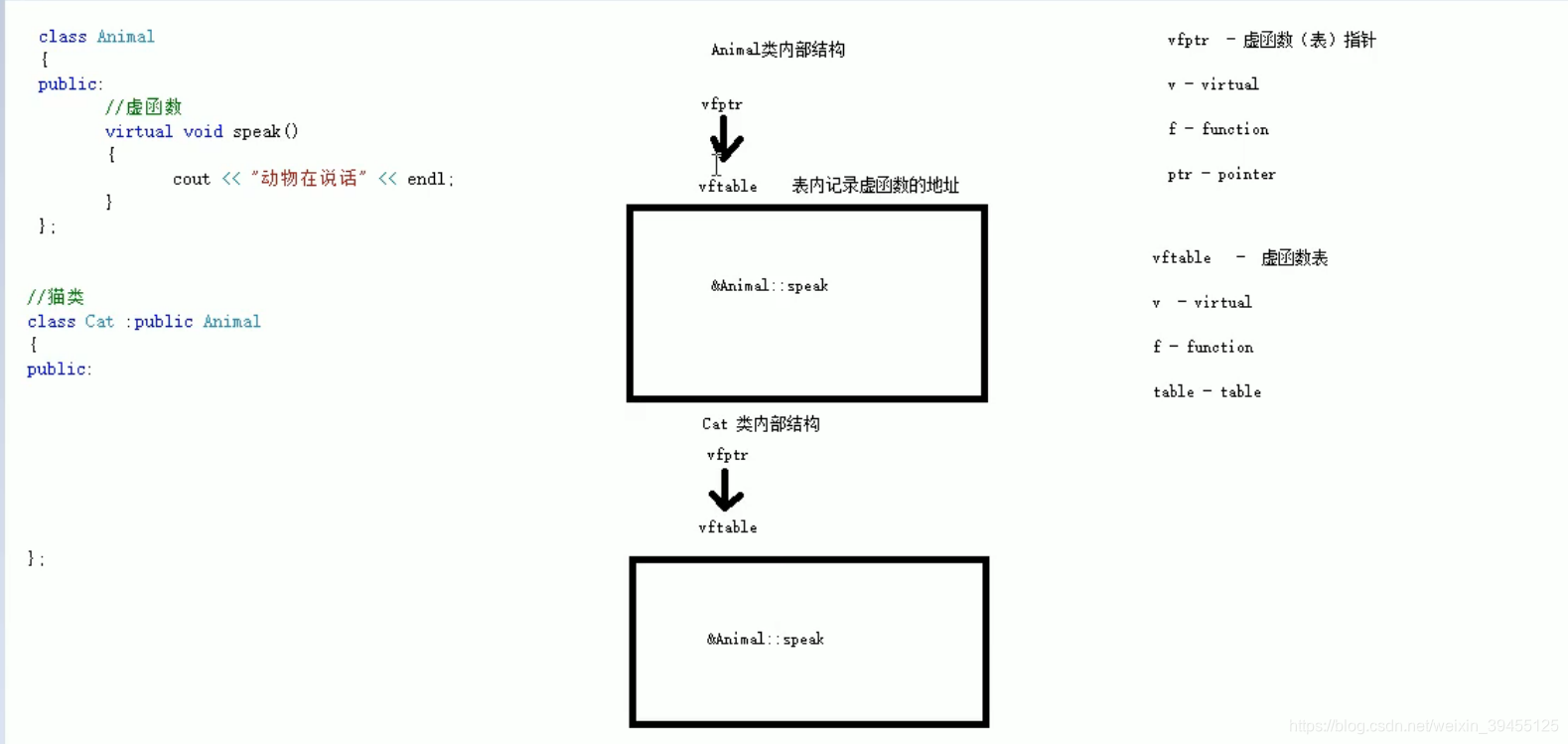
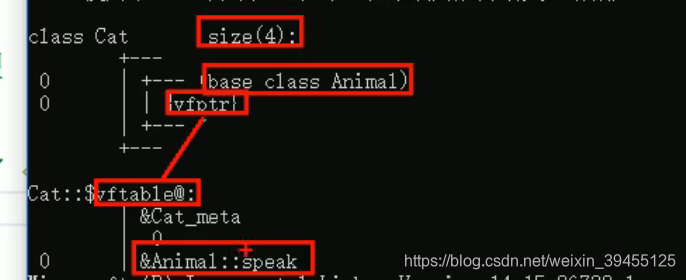
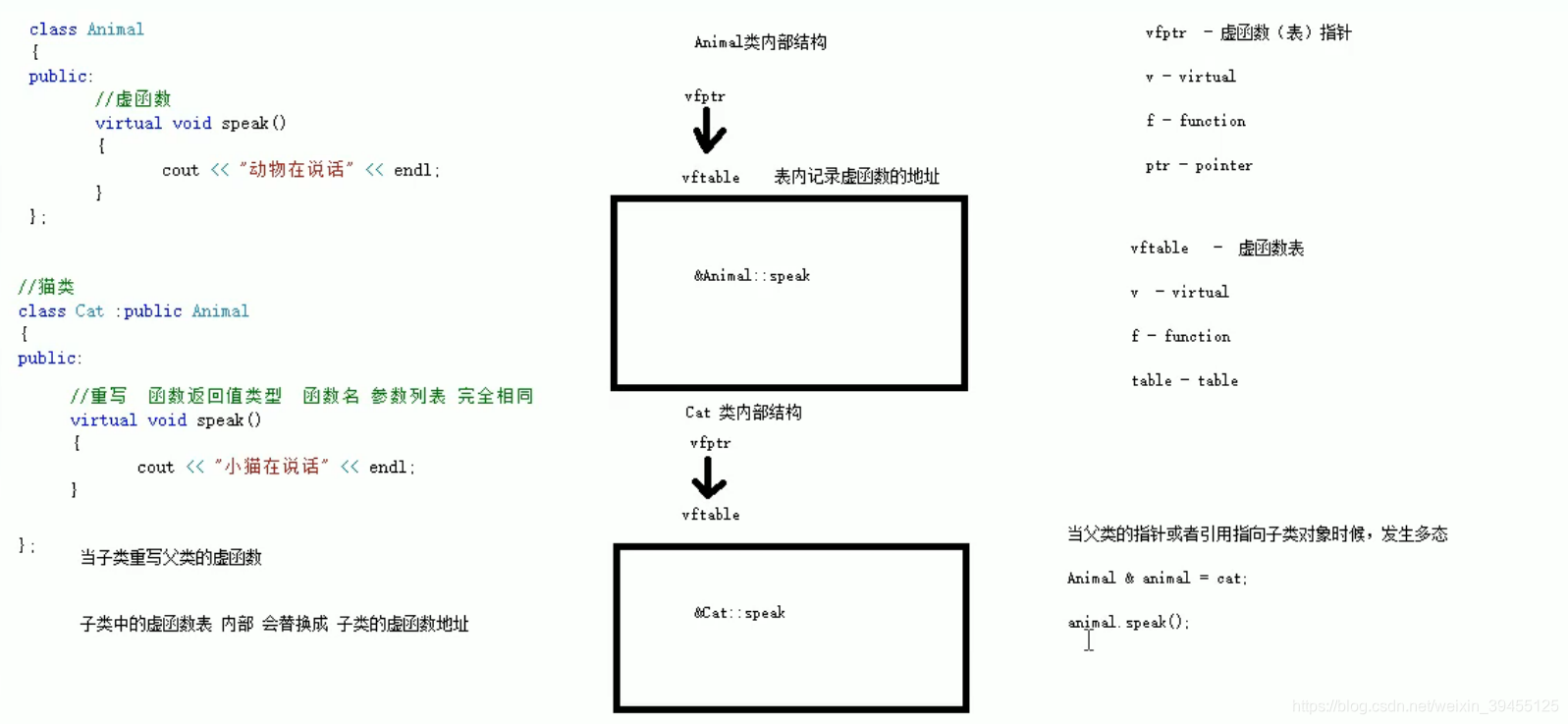
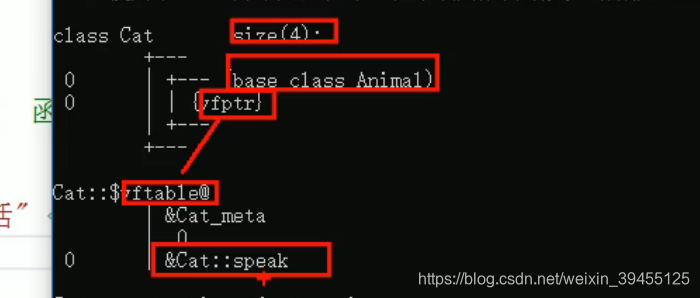
当父类中的函数,写成虚函数时,类的内部会生成一个虚函数表指针,该指针指向一个虚函数表,虚函数的内部记录了虚函数的入口地址。
当子类重写父类的虚函数时,子类中的虚函数表记录的函数地址,就变成了子类的虚函数地址。从而发生多态时,调用的是子类的虚函数。如果子类不重写父类的虚函数,子类中的虚函数表记录的仍然是父类的虚函数地址,从而不发生多态时,调用的也是父类的虚函数。
未发生多态时:
发生多态时:当父类指针或引用,指向子类对象,就会发生多态
多态案例一--------计算器类
案例描述:
分别利用普通写法和多态技术,设计实现两个操作数进行运算的计算器类
多态的优点:代码组织结构清晰、可读性强、利于前期和后期的扩展以及维护
源码对比:
//普通实现
class Calculator {
public:
int getResult(string oper) //成员函数:形参为传入的操作符号
{
if (oper == "+") {
return m_Num1 + m_Num2;
}
else if (oper == "-") {
return m_Num1 - m_Num2;
}
else if (oper == "*") {
return m_Num1 * m_Num2;
}
//如果要提供新的运算,需要修改源码
}
public:
int m_Num1;
int m_Num2;
};
void test01()
{
//普通实现测试
Calculator c;
c.m_Num1 = 10;
c.m_Num2 = 10;
cout << c.m_Num1 << " + " << c.m_Num2 << " = " << c.getResult("+") << endl;
cout << c.m_Num1 << " - " << c.m_Num2 << " = " << c.getResult("-") << endl;
cout << c.m_Num1 << " * " << c.m_Num2 << " = " << c.getResult("*") << endl;
}
//在真实开发中,提倡开闭原则。
//开闭原则:对扩展进行开放,对修改进行关闭。
//即对一个已完成的项目,我们在对其进行功能扩展时。我们提倡不进行源码的修改,而直接增加新的模块代码。这时,使用多态设计程序是一个很好选择。
//多态实现
//抽象计算器类
class AbstractCalculator
{
public :
virtual int getResult() //多态满足条件:有继承关系;子类重写父类中的虚函数
{
return 0;
}
int m_Num1;
int m_Num2;
};
//加法计算器
class AddCalculator :public AbstractCalculator
{
public:
int getResult()
{
return m_Num1 + m_Num2;
}
};
//减法计算器
class SubCalculator :public AbstractCalculator
{
public:
int getResult()
{
return m_Num1 - m_Num2;
}
};
//乘法计算器
class MulCalculator :public AbstractCalculator
{
public:
int getResult()
{
return m_Num1 * m_Num2;
}
};
void test02()
{
//创建加法计算器
AbstractCalculator *abc = new AddCalculator; //多态使用条件:父类指针或引用,指向子类对象
abc->m_Num1 = 10;
abc->m_Num2 = 10;
cout << abc->m_Num1 << " + " << abc->m_Num2 << " = " << abc->getResult() << endl;
delete abc; //用完了记得销毁(堆区数据需要程序员手动释放)
//创建减法计算器
abc = new SubCalculator; //上一句delete abc,功能是只释放堆区数据,指针指向的值被销毁,但指针变量并没有销毁,因而可以再对指针指向的值进行再赋值
abc->m_Num1 = 10;
abc->m_Num2 = 10;
cout << abc->m_Num1 << " - " << abc->m_Num2 << " = " << abc->getResult() << endl;
delete abc;
//创建乘法计算器
abc = new MulCalculator;
abc->m_Num1 = 10;
abc->m_Num2 = 10;
cout << abc->m_Num1 << " * " << abc->m_Num2 << " = " << abc->getResult() << endl;
delete abc;
}
//主函数
int main() {
//test01();
test02();
system("pause");
return 0;
}
3)纯虚函数和抽象类
在多态中,通常父类中虚函数的实现是毫无意义的,主要都是调用子类虚函数的内容,因此可以将虚函数改为纯虚函数。
当类中有了纯虚函数,这个类也称为抽象类。
纯虚函数语法:virtual 返回值类型 函数名 (参数列表)= 0 ;
抽象类特点:
抽象类是无法实例化对象的;
子类必须重写抽象类中的纯虚函数,否则也属于抽象类,无法进行实例化。
(子类重写虚函数的目的,就是使用多态。使用多态,就是让代码更清晰,更具扩展性)
源码解析:
class Base
{
public:
//纯虚函数
//类中只要有一个纯虚函数就称为抽象类
//抽象类无法实例化对象
//子类必须重写父类中的纯虚函数,否则也属于抽象类
virtual void func() = 0; //纯虚函数
};
class Son :public Base
{
public:
virtual void func()
{
cout << "func调用" << endl;
};
};
void test01()
{
Base * base = NULL;
Base b;// 错误,抽象类栈区无法实例化对象
//base = new Base; // 错误,抽象类堆区也无法实例化对象
son s;子类必须重写父类中的纯虚函数,否则子类也无法实例化。
//子类重写虚函数的目的,就是使用多态。使用多态,就是让代码更清晰,更具扩展性
base = new Son; //等价于Base *base = new Son;多态使用:父类指针,指向子类对象
base->func();
delete base;//记得销毁
}
int main() {
test01();
system("pause");
return 0;
}
多态案例二 -----制作饮品
案例描述:
制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料
利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶
源码解析:
//抽象制作饮品
class AbstractDrinking {
public:
//烧水
virtual void Boil() = 0;
//冲泡
virtual void Brew() = 0;
//倒入杯中
virtual void PourInCup() = 0;
//加入辅料
virtual void PutSomething() = 0;
//规定流程
void MakeDrink() {
Boil();
Brew();
PourInCup();
PutSomething();
}
};
//制作咖啡
class Coffee : public AbstractDrinking {
public:
//烧水
virtual void Boil() {
cout << "煮农夫山泉!" << endl;
}
//冲泡
virtual void Brew() {
cout << "冲泡咖啡!" << endl;
}
//倒入杯中
virtual void PourInCup() {
cout << "将咖啡倒入杯中!" << endl;
}
//加入辅料
virtual void PutSomething() {
cout << "加入牛奶!" << endl;
}
};
//制作茶水
class Tea : public AbstractDrinking {
public:
//烧水
virtual void Boil() {
cout << "煮自来水!" << endl;
}
//冲泡
virtual void Brew() {
cout << "冲泡茶叶!" << endl;
}
//倒入杯中
virtual void PourInCup() {
cout << "将茶水倒入杯中!" << endl;
}
//加入辅料
virtual void PutSomething() {
cout << "加入枸杞!" << endl;
}
};
//业务函数
void DoWork(AbstractDrinking* drink) { // AbstractDrinking* drink = new Coffee;意思是父类指针指向子类对象
drink->MakeDrink();//由于子类继承了父类,因此这里本质是调用父类中的函数。而由于是多态,MakeDrink函数里面的函数是对应子类对象里的虚函数内容
delete drink;//堆区数据,手动释放
}
void test01() {
DoWork(new Coffee);
cout << "--------------" << endl;
DoWork(new Tea);
}
int main() {
test01();
system("pause");
return 0;
}
4)虚析构和纯虚析构
1.为什么要将父类中的析构函数,写成虚析构或者纯虚析构?
多态使用时,如果子类中有属性开辟到堆区,当需要手动释放内存时,那么父类指针在释放时无法调用到子类的析构代码。
(因为父类指针指向子类对象后,只有当子类重写了父类的虚函数,才能通过指针调用该函数。如果子类没有重写父类中的虚函数,那么指针就不能调用该函数。因此只有子类重写父类中的虚析构函数,在我们手动释放子类属性开辟的堆区内存时候,此时才能通过父类指针调用到子类的析构代码)
2.解决方式:将父类中的析构函数改为虚析构或者纯虚析构
3.虚析构和纯虚析构共性:
可以解决父类指针释放子类对象
都需要有具体的函数实现
4.虚析构和纯虚析构区别:
如果是纯虚析构,该类属于抽象类,无法实例化对象
5.虚析构语法:
virtual ~类名(){}
6.纯虚析构语法:
virtual ~类名() = 0;
类名::~类名(){}
源码解析:
class Animal {
public:
Animal()
{
cout << "Animal 构造函数调用!" << endl;
}
virtual void Speak() = 0;
//析构函数加上virtual关键字,变成虚析构函数
//virtual ~Animal()
//{
// cout << "Animal虚析构函数调用!" << endl;
//}
virtual ~Animal() = 0;
};
Animal::~Animal()
{
cout << "Animal 纯虚析构函数调用!" << endl;
}
//和包含普通纯虚函数的类一样,包含了纯虚析构函数的类也是一个抽象类。不能够被实例化。
class Cat : public Animal {
public:
Cat(string name)
{
cout << "Cat构造函数调用!" << endl;
m_Name = new string(name);
}
virtual void Speak()
{
cout << *m_Name << "小猫在说话!" << endl;
}
~Cat()
{
cout << "Cat析构函数调用!" << endl;
if (this->m_Name != NULL) {
delete m_Name;
m_Name = NULL;
}
}
public:
string *m_Name;
};
void test01()
{
Animal *animal = new Cat("Tom");
animal->Speak();
//通过父类指针去释放,会导致子类对象可能清理不干净,造成内存泄漏
//怎么解决?给基类增加一个虚析构函数
//虚析构函数就是用来解决通过父类指针释放子类对象
delete animal;
}
int main() {
test01();
system("pause");
return 0;
}
注意:为什么父类中析构函数写成纯虚析构函数时,要另外在类外实现。而父类中一般函数写成纯虚函数,不要在类外实现?
答:
因为当父类中也有堆区数据时,我们就必须调用父类中的纯虚析构函数。要使父类能调用到纯虚析构函数,那么前提是其纯虚析构函数必须有实现,就不能像之前的纯虚函数那样只有声明。我们之前之所以没有在类外实现纯虚函数,而只在类内声明,是因为我们没有用到父类中的纯虚函数,而只用子类中的对应纯虚函数。因此,当父类中没有堆区数据时,我们其实也可以不用写纯虚析构函数。

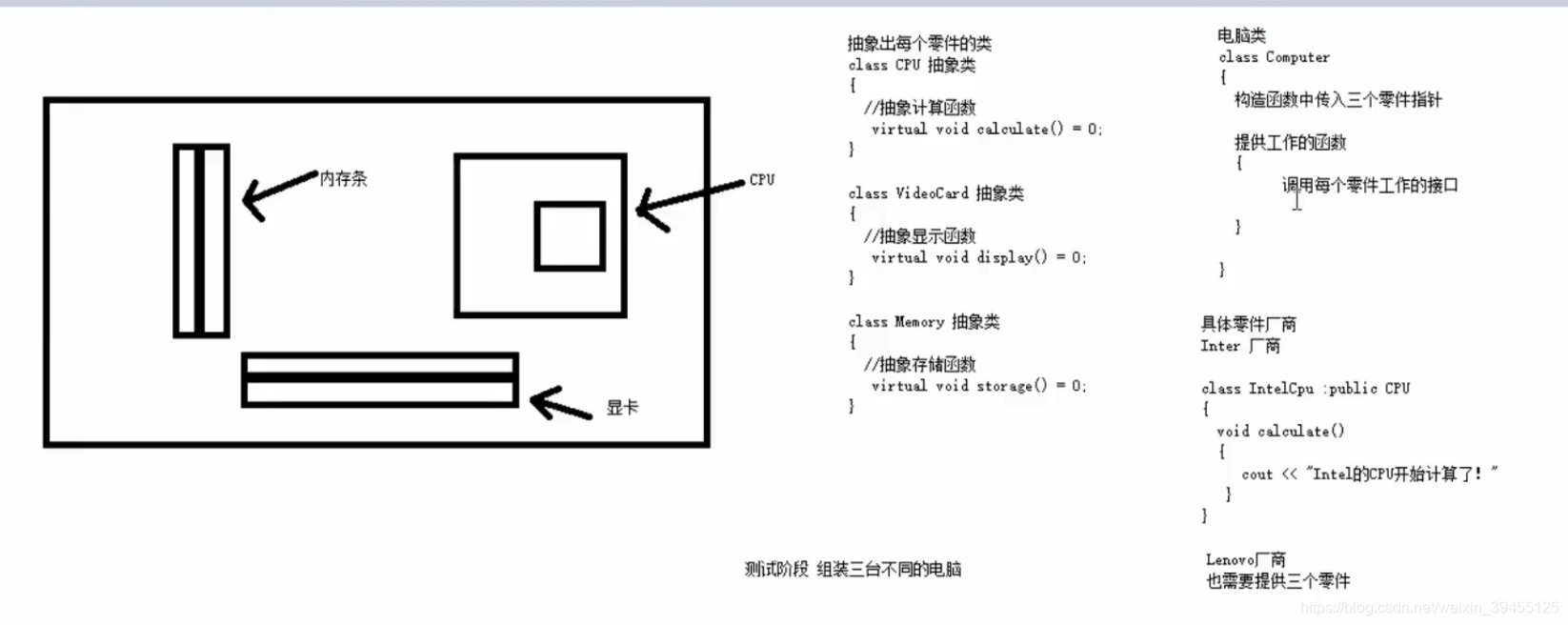
多态案例三------电脑组装
案例描述:
电脑主要组成部件为 CPU(用于计算),显卡(用于显示),内存条(用于存储)
将每个零件封装出抽象基类,并且提供不同的厂商生产不同的零件,例如Intel厂商和Lenovo厂商
创建电脑类提供让电脑工作的函数,并且调用每个零件工作的接口
测试时组装三台不同的电脑进行工作
示意图:
源码解析:
#include<iostream>
using namespace std;
//抽象CPU类
class CPU
{
public:
//抽象的计算函数
virtual void calculate() = 0;
};
//抽象显卡类
class VideoCard
{
public:
//抽象的显示函数
virtual void display() = 0;
};
//抽象内存条类
class Memory
{
public:
//抽象的存储函数
virtual void storage() = 0;
};
//电脑类
class Computer
{
public:
Computer(CPU * cpu, VideoCard * vc, Memory * mem)
{
m_cpu = cpu;
m_vc = vc;
m_mem = mem;
}
//提供工作的函数
void work()
{
//让零件工作起来,调用接口
m_cpu->calculate();
m_vc->display();
m_mem->storage();
}
//提供析构函数 释放3个电脑零件
~Computer()
{
//释放CPU零件
if (m_cpu != NULL)
{
delete m_cpu;
m_cpu = NULL;
}
//释放显卡零件
if (m_vc != NULL)
{
delete m_vc;
m_vc = NULL;
}
//释放内存条零件
if (m_mem != NULL)
{
delete m_mem;
m_mem = NULL;
}
}
private:
CPU * m_cpu; //CPU的零件指针 类作为另一个类的成员属性
VideoCard * m_vc; //显卡零件指针
Memory * m_mem; //内存条零件指针
};
//具体厂商
//Intel厂商
class IntelCPU :public CPU
{
public:
virtual void calculate()
{
cout << "Intel的CPU开始计算了!" << endl;
}
};
class IntelVideoCard :public VideoCard
{
public:
virtual void display()
{
cout << "Intel的显卡开始显示了!" << endl;
}
};
class IntelMemory :public Memory
{
public:
virtual void storage()
{
cout << "Intel的内存条开始存储了!" << endl;
}
};
//Lenovo厂商
class LenovoCPU :public CPU //CPU子类
{
public:
virtual void calculate()
{
cout << "Lenovo的CPU开始计算了!" << endl;
}
};
class LenovoVideoCard :public VideoCard //显卡子类
{
public:
virtual void display()
{
cout << "Lenovo的显卡开始显示了!" << endl;
}
};
class LenovoMemory :public Memory //内存子类
{
public:
virtual void storage()
{
cout << "Lenovo的内存条开始存储了!" << endl;
}
};
void test01()
{
//第一台电脑零件
CPU * intelCpu = new IntelCPU; //父类指针 指向 子类对象
VideoCard * intelCard = new IntelVideoCard;
Memory * intelMem = new IntelMemory;
cout << "第一台电脑开始工作:" << endl;
//创建第一台电脑
Computer * computer1 = new Computer(intelCpu, intelCard, intelMem);
computer1->work();
delete computer1;
cout << "-----------------------" << endl;
cout << "第二台电脑开始工作:" << endl;
//第二台电脑组装
Computer * computer2 = new Computer(new LenovoCPU, new LenovoVideoCard, new LenovoMemory);;
computer2->work();
delete computer2;
cout << "-----------------------" << endl;
cout << "第三台电脑开始工作:" << endl;
//第三台电脑组装
Computer * computer3 = new Computer(new LenovoCPU, new IntelVideoCard, new LenovoMemory);;
computer3->work();
delete computer3;
}
五、 文件操作
1.为什么会有文件操作?
程序运行时产生的数据都属于临时数据,程序一旦运行结束,数据都会被释放。因此可以通过文件,将数据持久化
C++中对文件操作需要包含头文件 < fstream >(文件流的管理类)
2.文件类型分为两种?
文本文件 ------文件以文本的ASCII码形式存储在计算机中(用记事本打开能开懂)
二进制文件 ------ 文件以文本的二进制形式存储在计算机中,用户一般不能直接读懂它们
3.操作文件的三大类?
三个文件流类,利用类创建对象,可以实现对文件的操作
ofstream:写操作
ifstream: 读操作
fstream : 读写操作
1.文本文件
1)写文件
写文件步骤如下:
1.包含头文件:#include (fstream是一个类)
2.创建流对象:ofstream ofs;(利用类,来创建一个对象。通过对象,就可以对文件进行操作)
3.打开文件:ofs.open(“文件路径”,打开方式);(利用对象的属性和方法,来对文件进行具体操作)
4.写数据:ofs << “写入的数据”;
5.关闭文件:ofs.close();

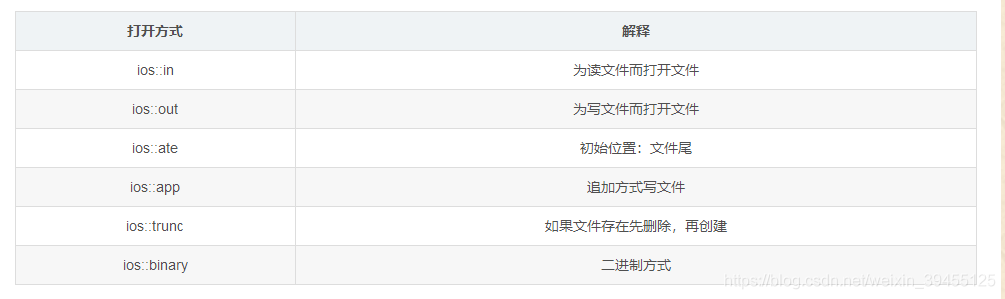
文件打开方式:
注意: 文件打开方式可以配合使用,利用 | 操作符
如:用二进制方式写文件 ios::binary | ios:: out
总结:
文件操作必须包含头文件 fstream
写文件可以利用 ofstream ,或者fstream类
打开文件时候需要指定操作文件的路径,以及打开方式
利用 << 可以向文件中写数据
操作完毕,要关闭文件
2)读文件
读文件与写文件步骤相似,但是读取方式相对于比较多
读文件步骤如下:
1.包含头文件:#include
2.创建流对象:ifstream ifs;
3.打开文件并判断文件是否打开成功:ifs.open(“文件路径”,打开方式);
4.读数据:四种方式读取
5.关闭文件:ifs.close();
源码解析:
1.包含头文件
#include <fstream>
#include <string>
void test01()
{
2.创建流对象
ifstream ifs;
3.打开文件并判断文件是否打开成功
ifs.open("test.txt", ios::in);
if (!ifs.is_open()) //类中函数is_open()的返回值是布尔类型,True表示文件打开成功,False表示文件打开失败
{
cout << "文件打开失败" << endl;
return;
}
4.读数据
//第一种方式
//char buf[1024] = { 0 }; //创建字符数组,用于存放文件中的数据
//while (ifs >> buf) //将对象ifs中的数据,放到buf中。当ifs对象打开的数据全部放完到buf后,返回假,退出while循环
// cin >> a:将外部输入的数据放到变量a中;ifs >> buf 则是将ifs 对象打开的文件,放到字符数组buf中。意义是一样的。
//{
// cout << buf << endl;
//}
//第二种
//char buf[1024] = { 0 };
//while (ifs.getline(buf,sizeof(buf))) //逐行获取:第一个参数为数据存放的容器,此处为指针;第二个参数为需要存放数据的大小
//{
// cout << buf << endl;
//}
//第三种
//string buf;
//while (getline(ifs, buf))
//{
// cout << buf << endl;
//}
char c;
while ((c = ifs.get()) != EOF) //EOF = end of file
{
cout << c;
}
5.关闭文件
ifs.close();
}
int main() {
test01();
system("pause");
return 0;
}
2. 二进制文件
以二进制的方式对文件进行读写操作
打开方式要指定为 ios::binary
1) 写文件
二进制方式写文件主要利用流对象调用成员函数write
函数原型 :ostream& write(const char * buffer,int len);
参数解释:字符指针buffer指向内存中一段存储空间。len是读写的字节数
源码解析:
#include <fstream>
#include <string>
class Person
{
public:
char m_Name[64];
int m_Age;
};
//二进制文件 写文件
void test01()
{
//1、包含头文件
//2、创建输出流对象
ofstream ofs("person.txt", ios::out | ios::binary);
//3、打开文件
//ofs.open("person.txt", ios::out | ios::binary);
Person p = {"张三" , 18};
//4、写文件
ofs.write((const char *)&p, sizeof(p)); //第一个参数:要写的数据在哪里,用指针;第二个参数:要写的数据大小
//5、关闭文件
ofs.close();
}
int main() {
test01();
system("pause");
return 0;
}
总结:文件输出流对象 可以通过write函数,以二进制方式写数据
2)读文件
二进制方式读文件主要利用流对象调用成员函数read
函数原型:istream& read(char *buffer,int len);
参数解释:字符指针buffer指向内存中一段存储空间。len是读写的字节数
源码解析:
#include <fstream>
#include <string>
class Person
{
public:
char m_Name[64];
int m_Age;
};
void test01()
{
ifstream ifs("person.txt", ios::in | ios::binary);
if (!ifs.is_open())
{
cout << "文件打开失败" << endl;
}
Person p;
ifs.read((char *)&p, sizeof(p)); //第一个参数:读取数据后要存放的容器;第二个参数:要读取数据的大小
cout << "姓名: " << p.m_Name << " 年龄: " << p.m_Age << endl;
}
int main() {
test01();
system("pause");
return 0;
}
总结:文件输入流对象 可以通过read函数,以二进制方式读数据

















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









