







顺序表
2018统考
给定一个含 n ( n > = 1 ) n(n>=1) n(n>=1)个整数的数组,请设计一个在时间上尽可能高效的算法:找出数组中未出现的最小正整数。例如,数组 − 5 , 3 , 2 , 3 {-5,3,2,3} −5,3,2,3中未出现的最小整数是1;数组 1 , 2 , 3 {1,2,3} 1,2,3中未出现的最小正整数是4.要求:
- 设计思想
- 代码注释
- 时间空间复杂度
int MinMissedInt(int n,int a[]){
int i;
int b[n]; //用来记录i是否存在于数组
for(i = 0; i < n;i ++){
b[i] = 0;
}
for(i = 0;i < n;i ++){
if(a[i] >= 0)
b[a[i]] = 1;
}
for(i = 0;i < n;i ++){
if(!b[i])return i + 1;
}
return -1;
}
2020统考
定义一个三元组 ( a , b , c ) (a,b,c) (a,b,c)(a、b、c均为整数)的距离 D = ∣ a − b ∣ + ∣ b − c ∣ + ∣ c − a ∣ D = |a-b| + |b - c| + |c - a| D=∣a−b∣+∣b−c∣+∣c−a∣。给定三个非空整数集合 S 1 S_1 S1、 S 2 S_2 S2和 S 3 S_3 S3,按升序分别存储在3个数组中。请设计一个尽可能高效的算法,计算并输出所有的三元组 ( a , b , c ) (a,b,c) (a,b,c)( a ∈ S 1 a \in S_1 a∈S1, b ∈ S 2 b \in S_2 b∈S2, a ∈ S 3 a \in S_3 a∈S3)中的最小距离。
- 设计思想
- 代码注释
- 时间空间复杂度
- 设计思想
由表达式可以看出,
D
=
2
∗
m
a
x
(
∣
a
−
b
∣
,
∣
b
−
c
∣
,
∣
c
−
a
∣
)
D = 2 * max(|a-b|,|b-c|,|c-a|)
D=2∗max(∣a−b∣,∣b−c∣,∣c−a∣)
用图像表示可以看出,
a
a
a、
b
b
b和
c
c
c三点中左右两侧端点决定了
D
D
D的大小,因此我们的思路可以改成固定最大值点,试图通过修改最正最小值点来找到最小和
D
D
D。终止条件我们选择为:
- D m i n Dmin Dmin为0,此时已经获得最小 D D D。
- 三元组中的一个元素遍历结束后又一次作为最小值时,因为此时已无法通过调整最小值点元素来减小
D
D
D,所以此后得到的任意
D
D
D都大于
D
m
i
n
Dmin
Dmin。
算法基本设计思想:
- 使用 D m i n Dmin Dmin记录所有已经处理的三元组的最小距离,初值为一个足够大的整数(例如 0 x 7 f f f f f f f 0x7fffffff 0x7fffffff)。
- 集合
S
1
S_1
S1、
S
2
S_2
S2和
S
3
S_3
S3分别保存在数组
A
A
A、
B
B
B和
C
C
C中。数组的下标变量
i
=
j
=
k
=
0
i = j = k =0
i=j=k=0,当
i
<
∣
S
1
∣
i < |S_1|
i<∣S1∣、
j
<
∣
S
2
∣
j < |S_2|
j<∣S2∣且
k
<
∣
S
3
∣
k < |S_3|
k<∣S3∣时
a) 计算 D D D
b) 比较 D D D和 D m i n Dmin Dmin
c) 将 A [ i ] A[i] A[i]、 B [ j ] B[j] B[j]和 C [ k ] C[k] C[k]中的最小值的下标+1; - 输出Dmin,结束。
- 算法实现
#define INT_MAX 0x7fffffff
int abs(int a){ //计算绝对值
if(a < 0)return -a;
return a;
}
bool ifmin(int a,int b,int c){ //判断是否是三个数中的最小值
if(a <= b && a <= c)return ture;
return false;
}
int findMinofTriple(int a[],int n,int b[],int m,int c[],int p){
//Dmin用于记录三元组的最小距离,初始赋值为INT_MAX
int i,j,k,Dmin,D;
i = j = k = 0;
Dmin = INT_MAX;
while(i < n && j < m && k < p && Dmin > 0){
D = abs(A[i] - B[j]) + abs(B[j] -C[k]) + abs(C[k] - A[i]);
if(D < Dmin)Dmin = D;
if(ifmin(A[i],B[j],C[k]))i++;
else if(ifmin(B[j],A[i],C[k]))j++;
else k++;
}
return Dmin;
}
链表
2009统考
已知一个带头结点的单链表,节点结构为|data|link|
假设该链表只给出了头指针list。在不改变链表的前提下,查找链表中倒数第k个位置上的节点。若查找成功,算法输出该结点的data域的值,并返回1;否则,只返回0。
- 设计思想
- 详细实现步骤
- 程序语言描述算法
解答:
- 算法的基础设计思想如下:
问题的关键是设计一个尽可能高效的算法,通过链表的一次遍历,找到倒数第k个节点的位置。算法的基本设计思想是:定义两个指针变量p和q,初始时均指向头结点的下一个指针(链表的第一个节点),p指针沿链表移动k次(指向链表的第k + 1个节点,此时q指向第1个节点),此时开始两个指针同时移动,直到p指针指空(虚拟的第n + 1个节点),q指针指向第n - k + 1个节点,即为倒数第k个节点。以上过程对链表仅进行一遍扫描。 - 算法的详细实现步骤如下:
- count = 0,p和q指向链表表头节点的下一个节点。
- 若p为空,转向5。
- 若count等于k,则q指向下一个节点;否则count = count + 1。
- p指向下一个节点,转2。
- 若count等于k,则查找成功,输出该节点的data域的值,返回1;否则,说明k值超过可线性表的长度,查找失败,返回0。
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode *link;
}LNode,*LinkList;
int Searchk(LinkList list,int k){
LNode *p,*q;
int count;
*p = list -> link;
*q = list -> link;
while(p){//p非空时进入循环
if(count < k){
p = p -> link;
count ++;
}else{
p = p -> link;
q = q -> link;
}
}
if(count == k){//查找成功,打印倒数第k位数据,返回1
printf("%d",q -> data);
return 1;
}
return -1;//链表长度比k小,查找失败,返回-1
}
2012统考
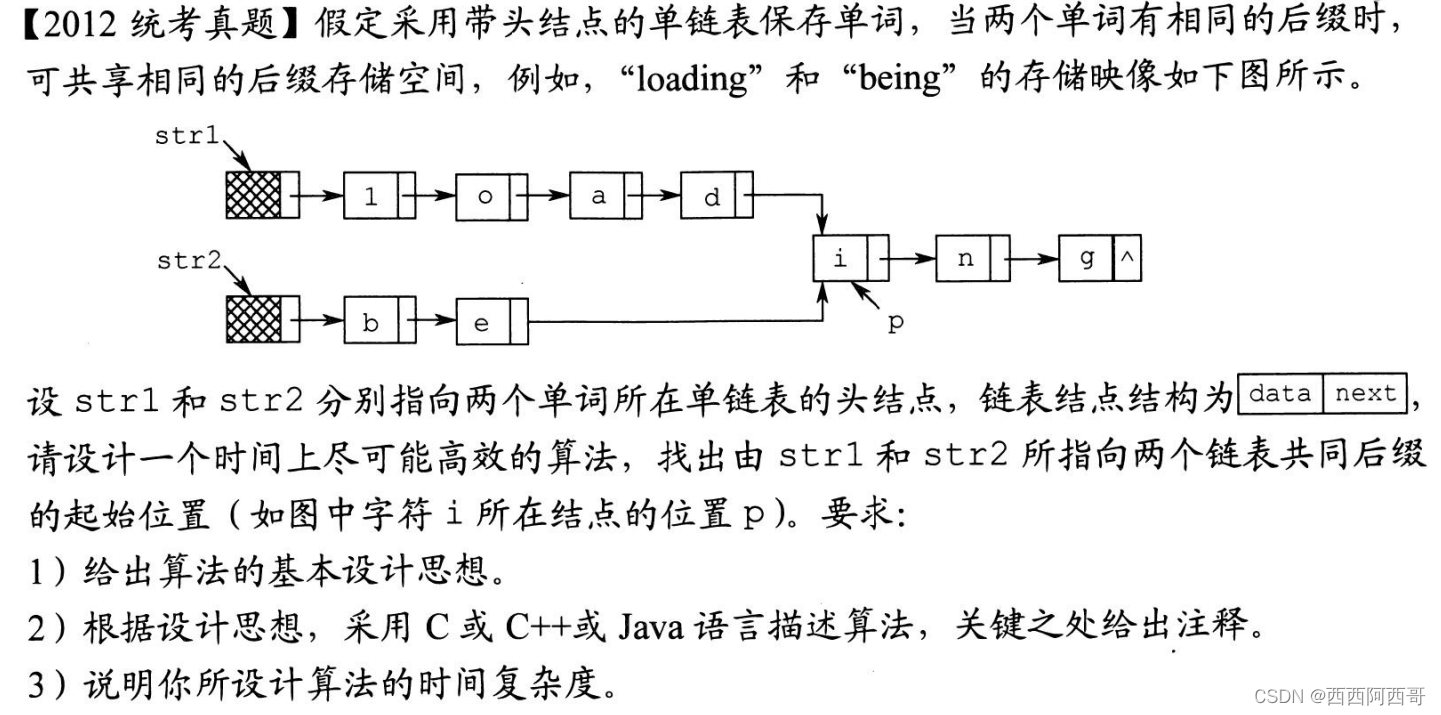
注意 相同后缀长度是相同的,所以假设我们从链表尾向前遍历,找到最后一个指向相同指针的节点即可,所以可以考虑模仿上一题中找倒数第k个节点的策略,先移动一个指针后两个节点同时移动。
解答:本题的结构体是单链表,采用双指针法。用指针p和q分别扫描str1和str2,当p、q指向同一个地址时,即找到共同后缀的起始位置。
- 算法的基础设计思想如下:
- 分别求出str1和str2两个链表的长度m和n;
- 将两个链表以表尾对齐,p、q分别指向str1和str2的头节点,若 m > = n m >= n m>=n,则指针p先走,使指针p指向链表第 m − n + 1 m-n+1 m−n+1个节点;若 m < = n m <= n m<=n,则指针q先走,使指针q指向链表第 n − m + 1 n-m+1 n−m+1个节点;即使指针p和q所指节点到表尾得长度相等。
- 反复将指针p和q同时向后移动,当p和q指向同一位置时停止,即为共同后缀的位置,算法结束。
- 算法代码如下:
typedef struct Node{
char data;
struct Node *next;
}SNode;
int StrLen(SNode *head){
int len = 0;
while(head -> next != NULL){
len ++;
head = head -> next;
}
return len;
}
SNode *FindComSufAddress(SNode *str1,SNode *str2){
int m,n;
int *p,*q;
m = StrLen(str1);
n = StrLen(str2);
for(p = str1;m > n;m--) //如果str1长,移动p使两字符串尾端对齐
p = p -> next;
for(q = str2;n > m;n--) //如果str2长,移动q使两字符串尾端对齐
q = q -> next;
while(p->next != NULL && p->next != q -> next){
//终止条件为p -> next、q -> next指向相同节点或空节点
p = p -> next;
q = q -> next;
}
return p -> next; //返回共同的后缀头结点(或空节点)
}
- 算法的时间复杂度为O(m + n),其中m和n是两链表的长度。
2015统考

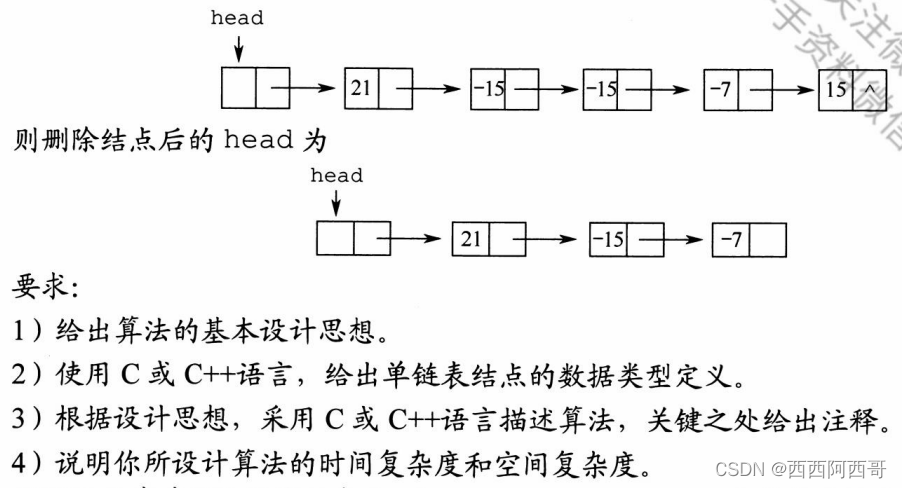
- 算法的基本设计思想:算法要求时间复杂度尽可能高效,且数据都取自一个有限集合,所以考虑建立这个有限集合并做标记添加附加信息的方法来用空间换取时间。即建立集合Entire[n],数组中元素的下标对应其代表的元素,数组存储0或1,0代表在给定的链表中该元素没有出现,1代表在给定的链表中该元素出现过。我们我们遍历给定的链表,在第一次遇到一个元素的绝对值a时,将其对应的Entire[a]标记为1,在后续遇到这个绝对值时,由于已标记,删除链表中元素,直到链表遍历完成。
- 单链表节点的数据结构定义:
typedef struct Node{
int data;
LNode *link;
}Node,*PNode;
- 算法实现:
int AbsValue(int data){
if(data > 0)return data;
return -data;
}
int DelRep(LNode *head,int n){
PNode p = head,r;
int *q,m;
q = (int*)malloc(sizeof(int)*(n+1));//给标记数组分配空间
for(int i = 0; i < n + 1;i ++) //初始化标记数组
+(q + i) = 0;
while(p -> link != NULL){
m = AbsValue(p -> link -> data);
if(*(q + m) == 0){ //当p->link->data的绝对值标记数组中未被标记
*(q + m) = 1; //标记数组
p = p -> link; //移动到被标记的位置
}
else{ //删除后一个节点,link已更新,所以不许移动指针
r = p -> link;
p -> link = r -> link;
free(r);
}
}
free(q);
}
- 时间复杂度 O ( m ) O(m) O(m),空间复杂度 O ( n ) O(n) O(n)
2019统考

- 算法思想:将线性表分为顺序和逆序两部分,顺序部分为
a
1
a_1
a1~
a
p
a_p
ap,其中
p
=
n
/
2
p = n/2
p=n/2;逆序部分为
a
q
a_q
aq~
a
n
a_n
an,其中
q
=
p
+
1
q = p + 1
q=p+1。由此可将算法分为三部分:
- 找到线性表的中间结点p
- 将p之后的结点逆序
- 将p之前的结点和p之后逆序后的结点交错链接到新表中
- 算法:
NODE *FindMiddle(NODE *head,int &len){
return mid;
}
NODE *RevList(NODE *head,int len){
return head;
}
void ChangeList(NODE *head){
int len = 0;
NODE *middle = FindMiddle(head,&len);
middle = RevList(middle,len);
NODE *p,*q,*r,*s;
*p = head -> next;
*q = middle -> next;
while(q != NULL){
//将p指向q,q指向p的下一个结点,然后p、q分别指向自身的下一个节点。
r = p -> next;
p -> next = q;
s = q -> next;
q -> next = p = r;
q = s;
}
if(p -> next != NULL)
//由于顺序的部分长度大于等于逆序的部分,检查边界
p -> next = NULL;
return;
}
- 由于FindMiddle、RevList和接入新表都只遍历链表一边,时间复杂度为 O ( n ) O(n) O(n)。

















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









