









 本文通过Kaggle上的泰坦尼克号生存预测项目,介绍了如何进行数据预处理、特征工程、模型训练及评估的基本步骤。从数据加载、清洗到使用线性回归模型进行预测,并采用交叉验证的方法提升模型准确性。
本文通过Kaggle上的泰坦尼克号生存预测项目,介绍了如何进行数据预处理、特征工程、模型训练及评估的基本步骤。从数据加载、清洗到使用线性回归模型进行预测,并采用交叉验证的方法提升模型准确性。
本篇文章尝试走一个基本的kaggle流程(数据查看、简单清洗、套用模型、训练模型、输出测试数据)
打开kaggle官方的kernel首先是一个测试代码
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
from subprocess import check_output
print(check_output(["ls", "../input"]).decode("utf8"))
# Any results you write to the current directory are saved as output.这段代码打印了一些数据相关的必要信息
了解数据
接下来是导入绘图包和使用pandas数据框架
from matplotlib import pyplot as plt
import pandas as pd接下来就是使用pandas模块来读取训练数据
titanic = pd.read_csv('../input/train.csv')读取上一级目录下的input文件夹中的train.csv文案进入内存(以pandas数据框架储存)
值得注意的是,由于使用了pandas框架,数据在内存中不仅仅是数据,还有复杂的数据结构,这样的优势是可以比较方便的操作,劣势是这样的框架在面对大量数据读入的时候会消耗较大的内存
数据进来之后要尝试让pandas告诉我们一点关于数据的故事,使用一下代码查看数据的前五行内容
titanic.head(5)#Overview of the data
# print titanic.head(3)

于是可以看到前五行的数据,分别是乘客ID、生存与否、仓位等级、名字、性别、年龄。。。。
其实这些数据海鸥更多的信息,这些信息让pandas来告诉我们
print(titanic.describe())#Some information of Characters
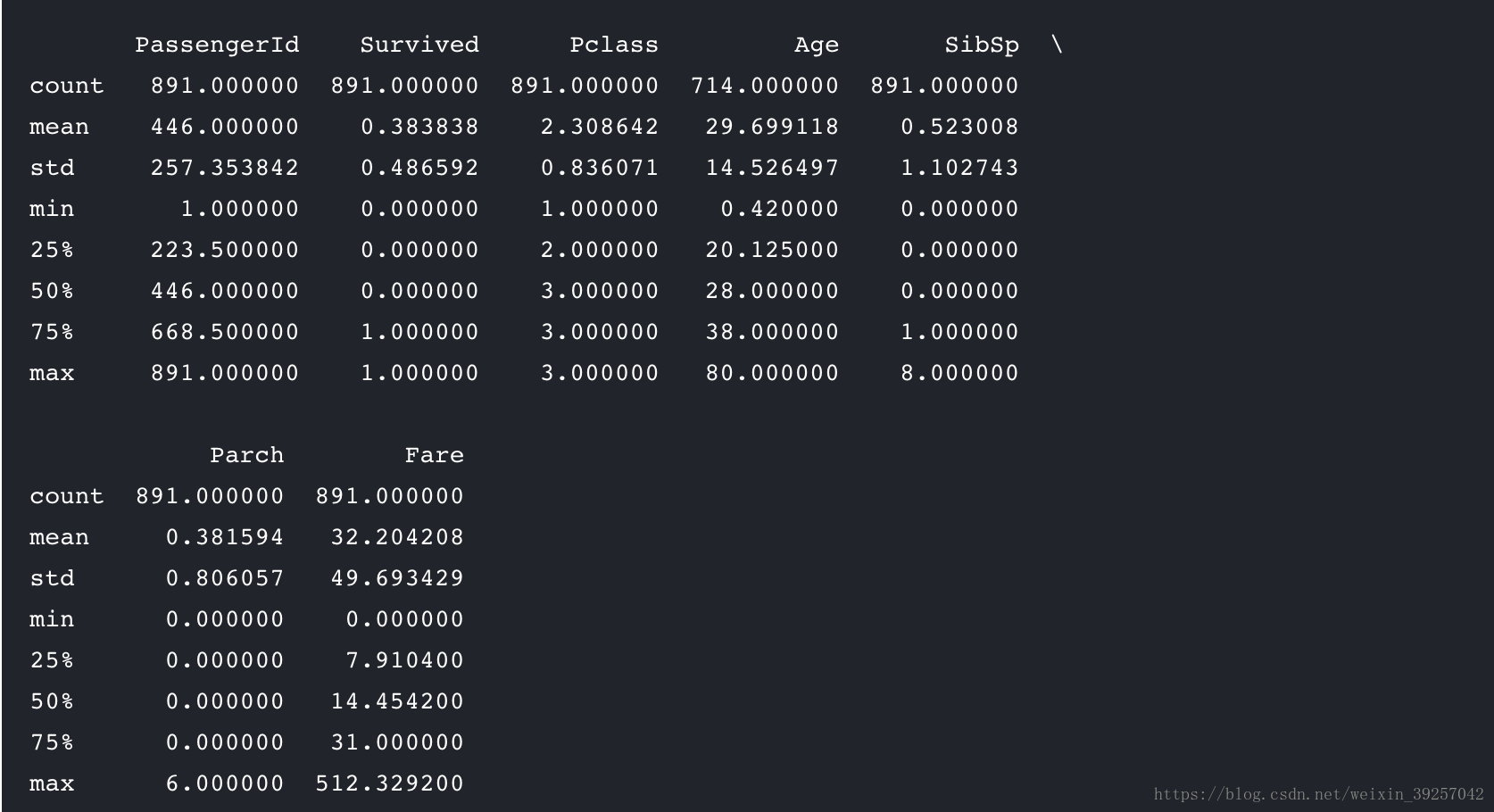
在这里我们可以发现Age选项是有缺失值的
尝试使用平均值来填充缺失值
titanic["Age"] = titanic["Age"].fillna(titanic['Age'].median())
填充之后再输出一次信息
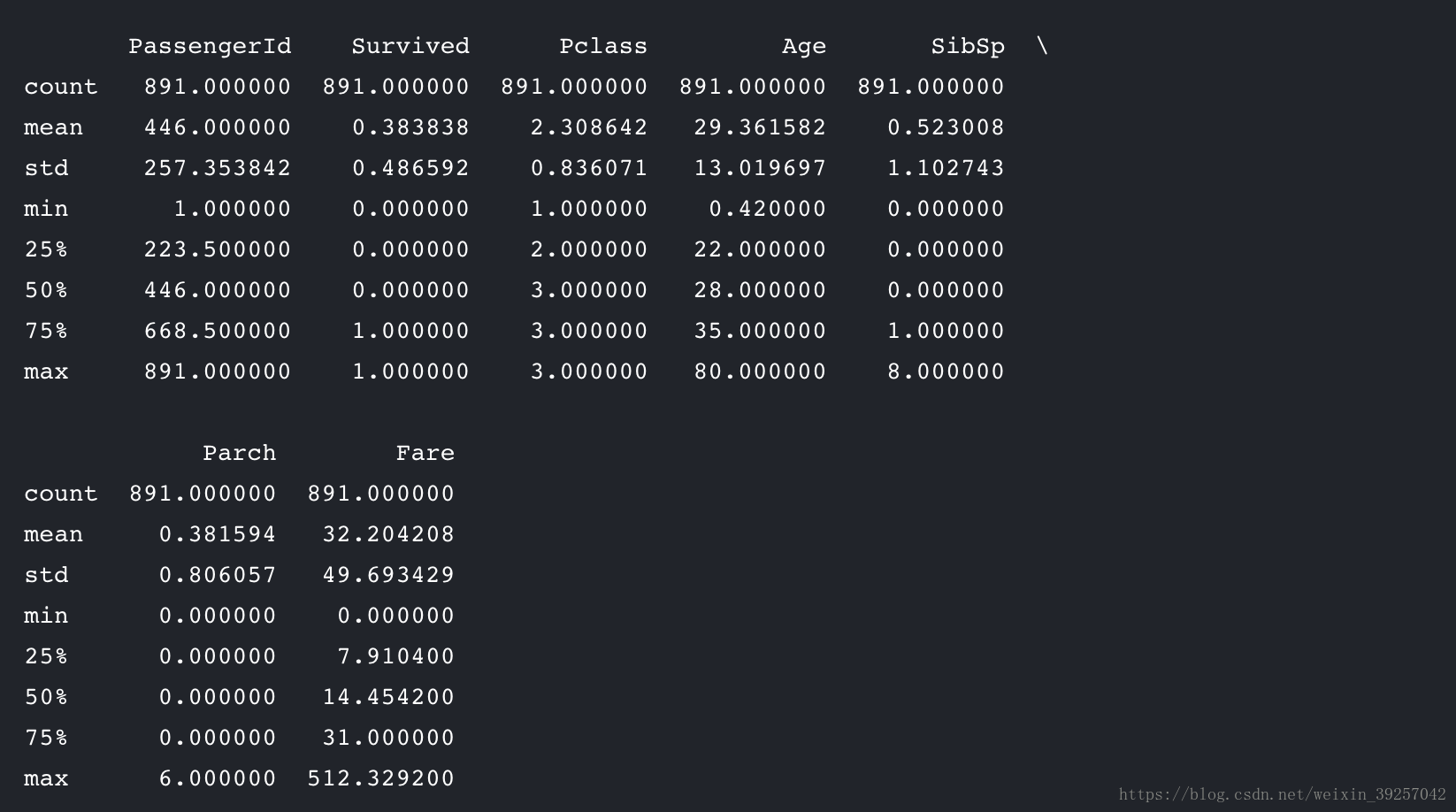
于是可以发现Age变多了
对于性别Sex我们先做一下category处理,用数字代替字符串的性别
titanic.loc[titanic["Sex"]=="male","Sex"]=0
titanic.loc[titanic["Sex"]=="female","Sex"]=1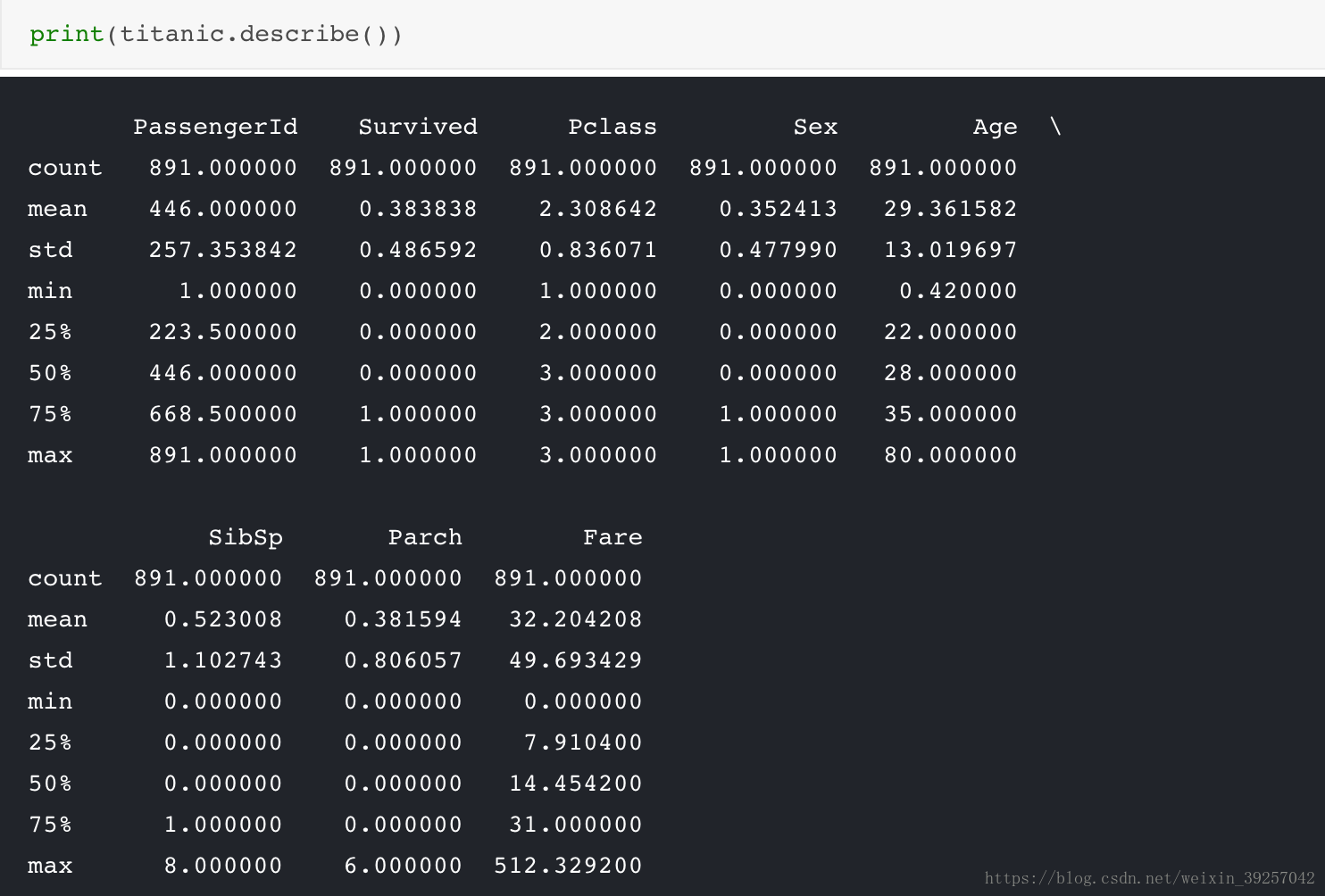
然后会发现这两个属性居然有数值了,其实这个数值大小是categorical的,是没有意义的,类比身份证的ID
训练模型
接下来为了训练模型import有关的包
from sklearn.linear_model import LinearRegression
from sklearn.cross_validation import KFold先假设:
"Pclass","Sex"与结果有关系predictors=["Pclass","Sex"]#,"Embarked"]kf=KFold(titanic.shape[0],n_folds=3,random_state=1)predictions=[]for train , test in kf:
train_predictors=(titanic[predictors].iloc[train,:])
train_target =titanic["Survived"].iloc[train]
alg.fit(train_predictors,train_target)
test_predictions = alg.predict(titanic[predictors].iloc[test,:])
predictions.append(test_predictions)predictions = np.concatenate(predictions, axis=0)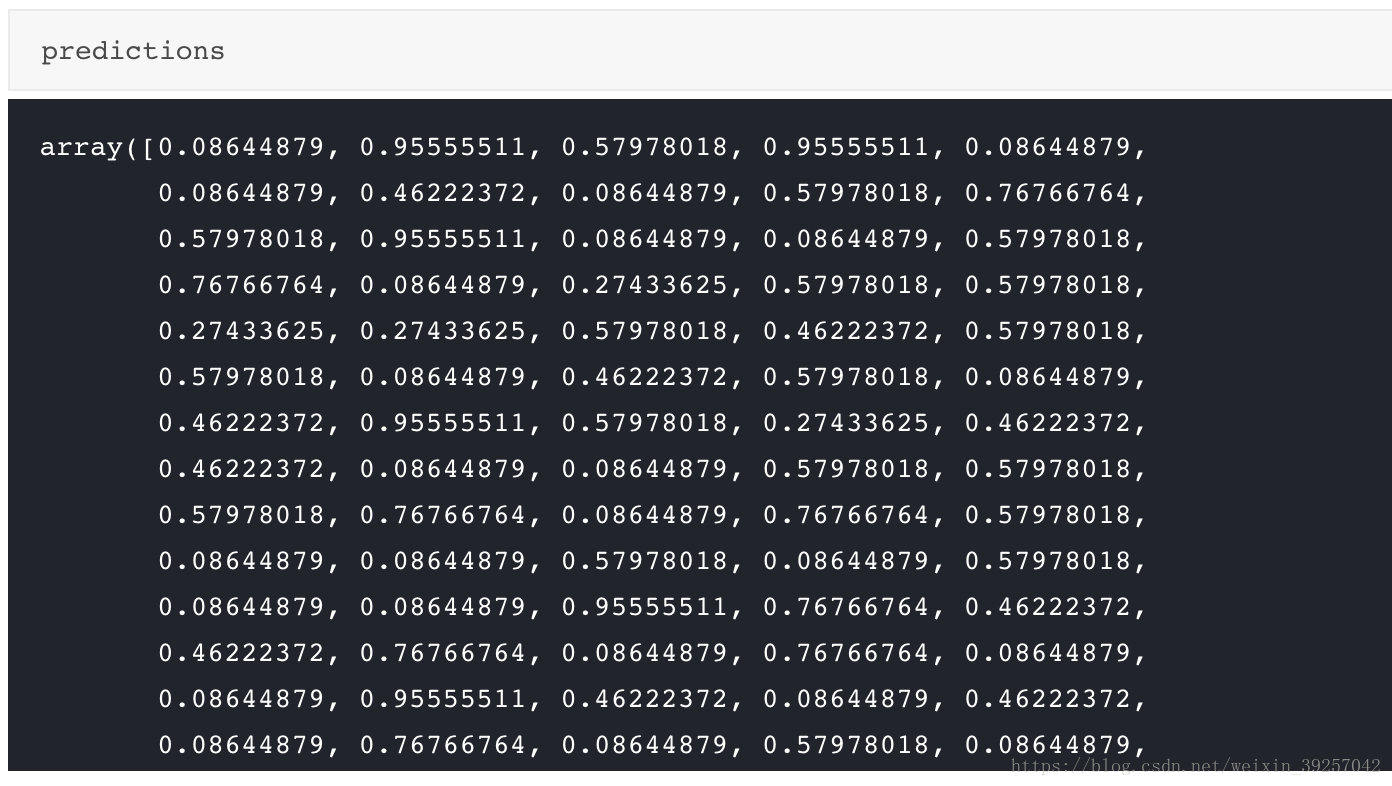
predictions[predictions > 0.5]=1
predictions[predictions <= 0.5]=0
要首先将predictions弄到pandas里面
siblings = pd.DataFrame(predictions)siblings.to_csv('../onput/dadada.csv')
















 9
9

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









