




采用PYTHON进行泰坦尼克号生存者预测
参考资料:
问题说明
采用PYTHON进行泰坦尼克号生存者预测。了解特征预处理,算法等流程
代码及说明
准备工作
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
pd.set_option('display.max_columns', None) # Show all columns
pd.set_option('display.width', 1000)
# Ignore all DeprecationWarnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
from scipy.stats import chi2_contingency
train_df=pd.read_csv('D:\下载文件\\Titanic data\\Titanic data\\train.csv')
test_df=pd.read_csv("D:\下载文件\\Titanic data\\Titanic data\\test.csv")
数据预处理
对数据有一个基本的认识
print('Train Dataset Shape',train_df.shape)
print('------------------------------------')
print('Test Dataset Shape',test_df.shape)
结果:
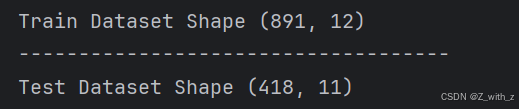
可见Train.csv文件有891行数据,共12列,Test.csv文件有418行数据,共11列.
将两个表数据合并,并再添一列表示数据来自哪个表
train_df['dataset_type']='train'
test_df['dataset_type']='test'
df=pd.concat([train_df,test_df])
df.head()
print('Combine Dataset Shape',df.shape)
df['dataset_type'].value_counts()
输出

检查重复数据
df.duplicated().sum()
测试为0
再检查缺失数据
df.info()
plt.figure(figsize=(10,5))
records=df.isnull().mean()*100
plt.xlabel('Features')
plt.ylabel('Percentage Of Missing Values')
plt.title('Missing Value Plot')
ax = records.plot(kind='bar')
for i, value in enumerate(records):
plt.text(i, value + 0.5, f'{
value:.2f}%', ha='center', va='bottom')
plt.show()
结果:
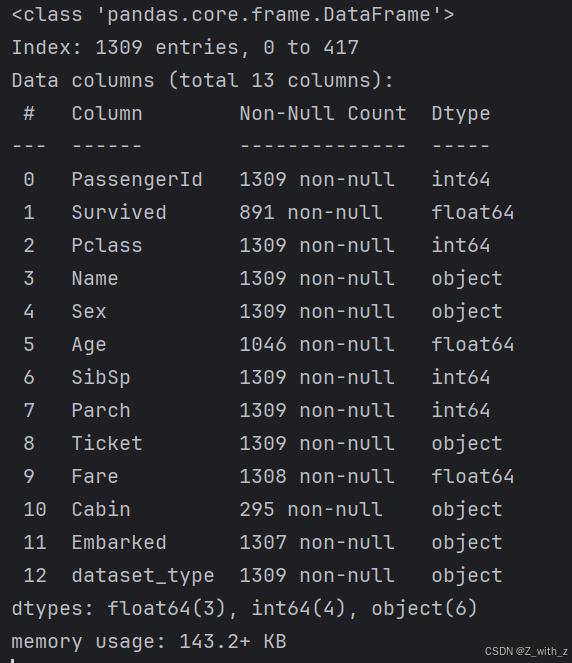
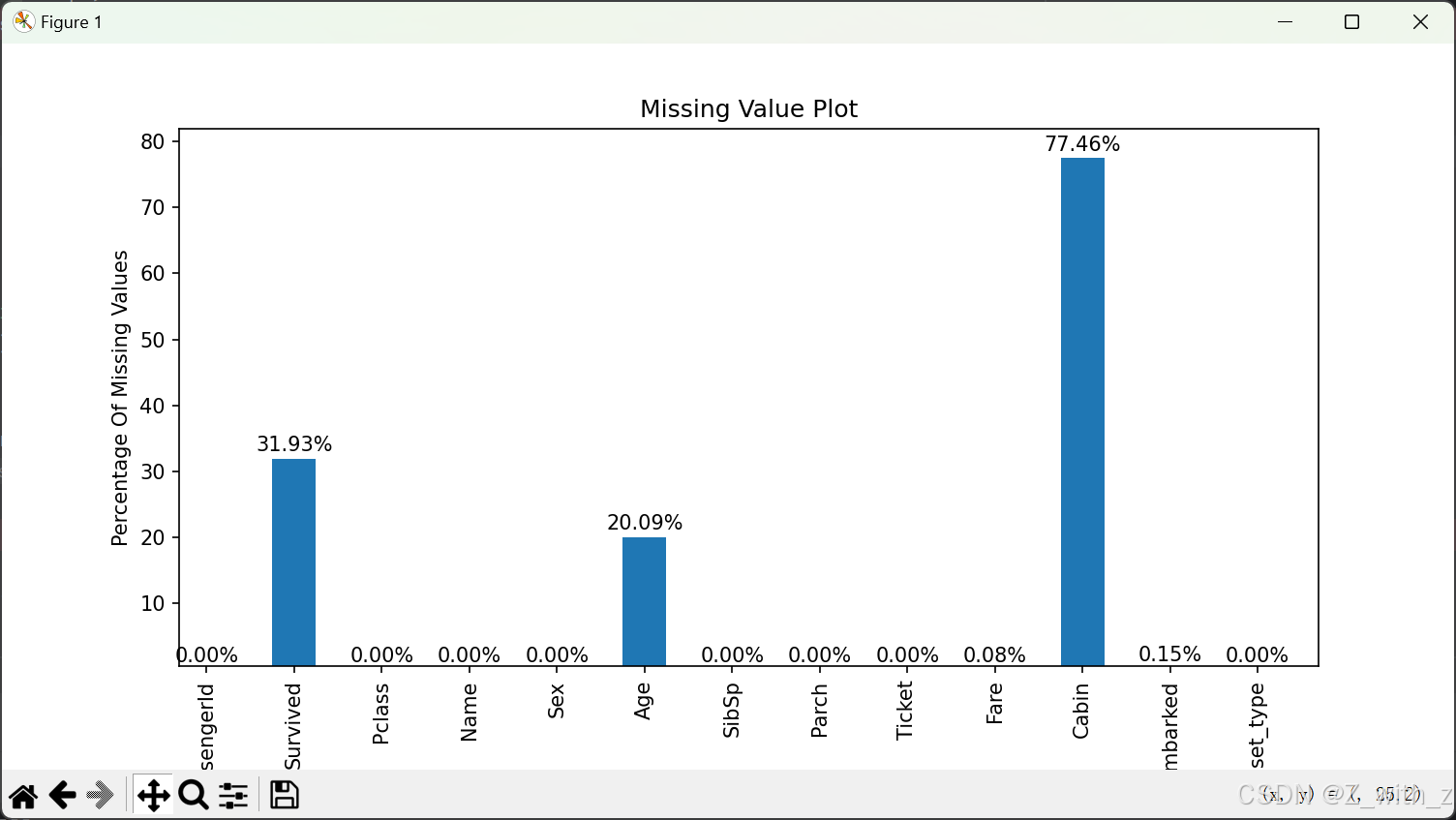
根据空值分析,我们观察到 Cabin 特征大约有 77% 的缺失值。由于缺失数据的比例很高,通过插补技术解决这个问题是不切实际的,另外,舱在哪个位置对于是否获救的影响也比较小。因此,我们建议从数据集中删除 Cabin 列,以保证数据质量。
同时,票证特征具有最大的特征值,其对生存预测的概率或影响最小,因此我们从数据集中删除票证列
df.drop(['Cabin', 'Ticket'], axis=1, inplace=True)
df.head()
df.info()
df.describe(include='all')
结果
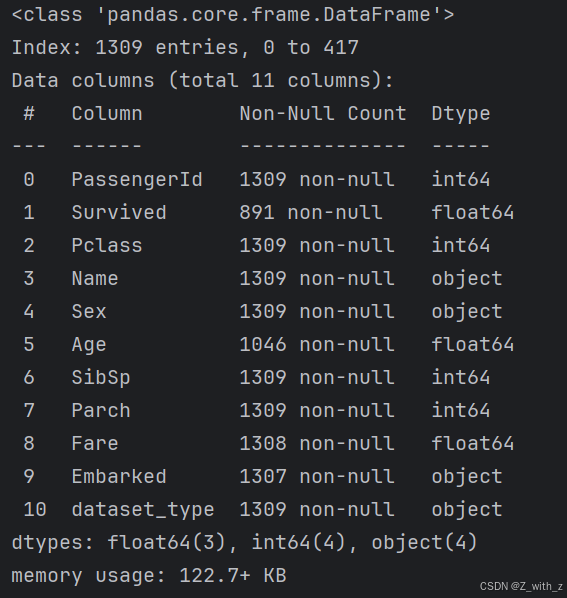
删除后由原来的13列变成了11列
剩下的还有Age,Fare,Embarked列有缺失,我们通过对数据的分析进行缺失值的预测
首先是Age和Fare
plt.figure(figsize=(10,5))
plt.subplot(2,2,1)
df['Age'].plot(kind='box')
plt.subplot(2,2,2)
df['Age'].plot(kind='hist')
plt.subplot(2,2,3)
df['Fare'].plot(kind='box')
plt.subplot(2,2,4)
df['Fare'].plot(kind='kde')
plt.tight_layout()
plt.show()
结果如下
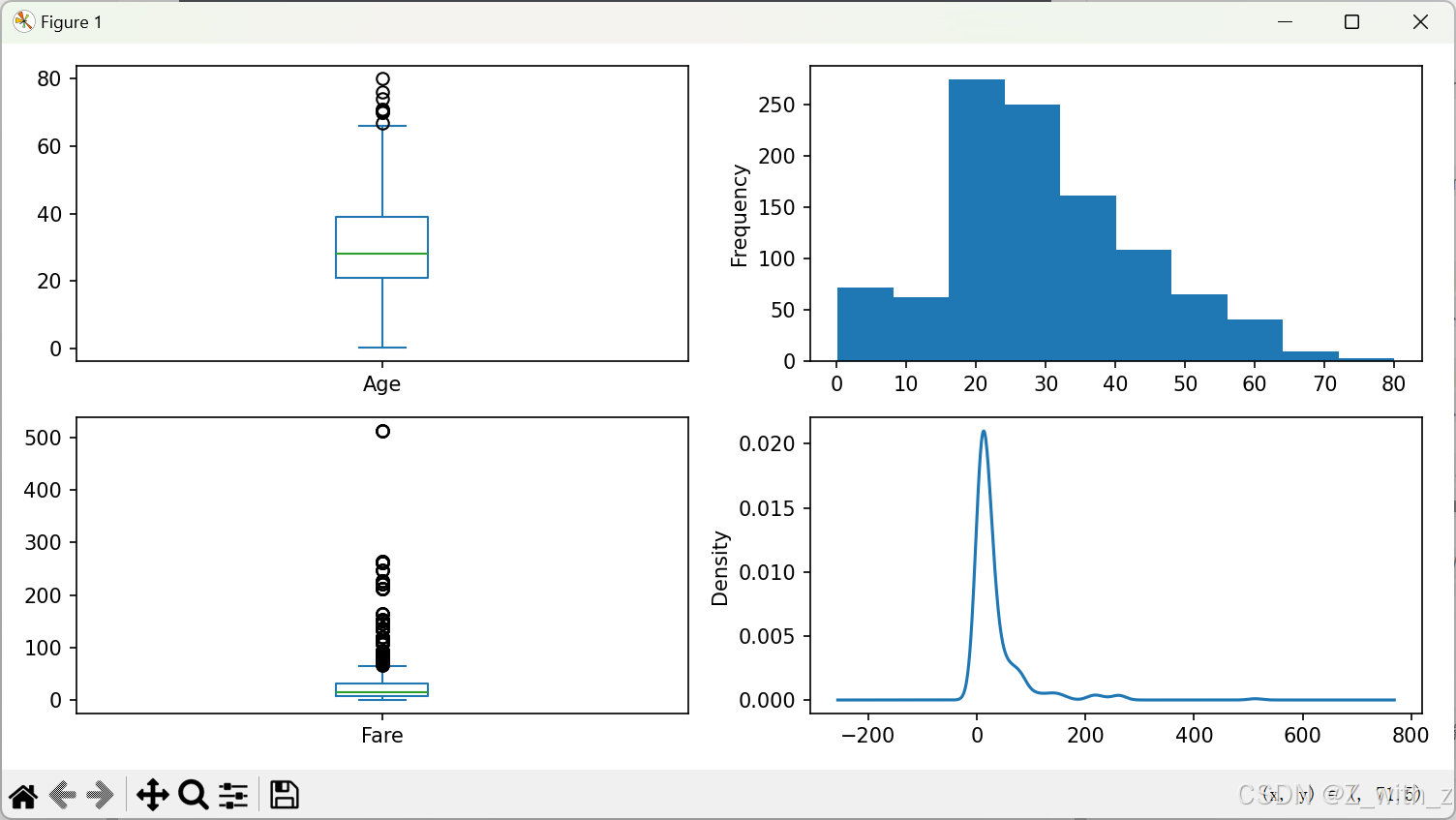
箱线图(box):
再结合直方图和密度图发现Fare有明显的右偏,于是为了克服偏斜效应,我们将它们转换为分箱数据。
df[['Age','Fare']].skew()
df['Embarked'].value_counts()
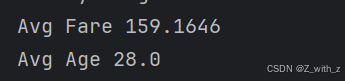
print('Avg Fare',df[df['Fare']>100]['Fare'].median())
print('Avg Age',df['Age'].median())
结果

发现Embarked(登船位置)最多的是S
然后进行缺失值或空值填补
df['Age']=df['Age'].fillna(df['Age'].median())
df['Fare']=df['Fare'].fillna(df[df['Fare']>100]['Fare'].median())
df['Embarked']=df['Embarked'].fillna('S')
fare_bins = [0, 7.89 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8278
8278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











