







鸢尾花识别:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#声明一个鸢尾花的类对象
iris = load_iris()
# 获取样本数据
iris_data = iris.data
# 获取样本标记值
iris_target = iris.target
print(iris_data)
print(iris.target)
# 获取鸢尾花的特征值,目标值
# 将数据分割成训练集和测试集 test_size=0.25表示将25%的数据用作测试集
# 分别把样本数据和它的标记数据分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.25)
# 送入算法
knn = KNeighborsClassifier(n_neighbors=5) # 创建一个KNN算法实例,n_neighbors默认为5,后续通过网格搜索获取最优参数
knn.fit(x_train, y_train) # 将测试集送入算法
y_predict = knn.predict(x_test) # 获取预测结果
# 预测结果展示
labels = ["山鸢尾","虹膜锦葵","变色鸢尾"]
for i in range(len(y_predict)):
print("第%d次测试:预测值:%s 真实值:%s"%((i+1),labels[y_predict[i]],labels[y_test[i]]))
print("准确率:",knn.score(x_test, y_test))
关于K值的选择测试:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
font = {"family": "SimHei", "size": "20"}
plt.rc("font", **font)
iris = load_iris()
x = iris.data
y = iris.target
k_range = range(1, 31)
k_error = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
#cv参数决定数据集划分比例,这里是按照5:1划分训练集和测试集
scores = cross_val_score(knn, x, y, cv=6)
print(scores)
k_error.append(1 - scores.mean())
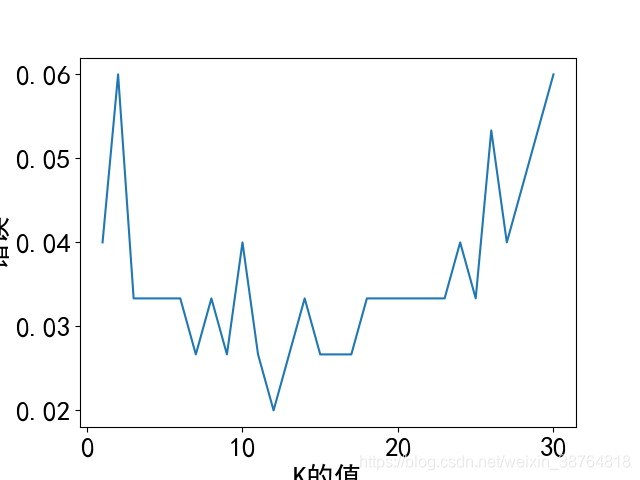
#画图,x轴为k值,y值为误差值
plt.plot(k_range, k_error)
plt.xlabel("K的值")
plt.ylabel("错误")
plt.show()

















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









