






点击下方卡片,关注“小白玩转Python”公众号
论文信息
题目:AdaNAS: Adaptively Postprocessing With Self-Supervised Neural Architecture Search for Ensemble Rainfall Forecasts
AdaNAS:用于集合降雨预报的自适应后处理与自监督神经架构搜索
作者:Yingpeng Wen, Weijiang Yu, Fudan Zheng, Dan Huang, Nong Xiao
论文创新点
自监督神经架构搜索(AdaNAS):提出了一种新颖的自监督神经架构搜索方法AdaNAS,用于降雨预报的后处理。这种方法减少了手动设计网络架构的需求,节省了大量时间和劳动力,同时能够自动搜索出适合特定降雨预报任务的网络结构。
降雨感知搜索空间:设计了一个针对降雨的感知搜索空间,包括空间感知块(SAB)和通道感知块(CAB),这些块特别针对高降雨区域的预测进行了优化。这使得模型能够更准确地预测高降雨区域,尤其是在沿海等降雨量大的地区。
降雨级别正则化函数:提出了一个新的基于降雨级别的正则化函数,该函数通过引入Heidke技能评分(HSS)作为分类标准,提高了降雨强度分类的准确性。这一正则化策略有助于模型更好地区分不同的降雨级别,提高了整体的预测性能。
摘要
以往的数值天气预报(NWP)降雨预报后处理研究主要关注基于统计的方面,而基于学习的方法很少被研究。尽管提出了一些手工设计的模型来提高准确性,但这些定制网络需要反复尝试和验证,耗费大量的时间和劳动力。因此,本研究提出了一种无需显著手动努力的自监督神经架构搜索(NAS)方法,称为AdaNAS,用于降雨预报后处理并预测降雨,具有高准确性。此外,我们设计了一个针对降雨的搜索空间,以显著改进高降雨区域的预报。此外,我们提出了一个降雨级别的正则化函数,以消除训练期间噪声数据的影响。在大规模降水基准TIGGE下的无、轻、中、重和暴五种情况下进行了验证实验。最后,所提出的AdaNAS模型的平均绝对误差(MAE)和平均均方根误差(RMSE)分别为0.98和2.04 mm/天。此外,所提出的AdaNAS模型与其他NAS方法和以前的研究进行了比较。比较结果揭示了所提出的AdaNAS模型在降水量预测和强度分类方面的满意性能和优越性。具体来说,所提出的AdaNAS模型在MAE和RMSE方面比以前表现最好的手工方法分别提高了80.5%和80.3%。
III. 方法描述
在本节中,我们描述了研究中使用的降水后处理问题和后处理方法。首先,在第III-A节中描述了降水后处理问题。第III-B节介绍了我们提出的自适应NAS方法,包括自监督搜索、搜索空间和正则化函数。
B. 自适应NAS
我们提出了一种先进的AdaNAS方法,自动设计合适的网络架构,避免了大量的人工努力,并取得了优异的性能。总的来说,我们的方法分为两个步骤,包括搜索架构和训练搜索到的模型。为了更好地使AdaNAS适应降雨预测,我们提出了自监督搜索策略、针对降雨的搜索空间和降雨级别的正则化函数。
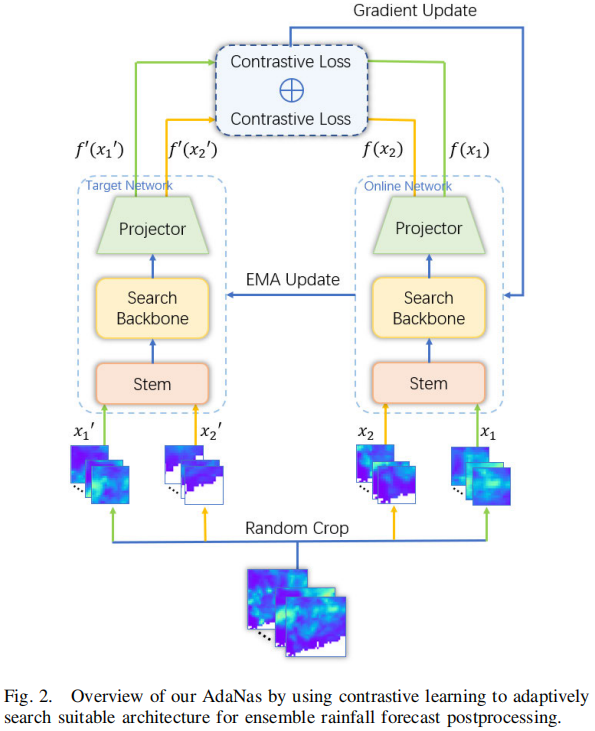
自监督搜索:我们采用了一种基于块的自监督比较学习方法来搜索网络架构,而不是使用一次性NAS中的共享权重。为了减少计算工作量,大多数NAS方法采用了一次性NAS方法中的权重共享评级方案。然而,用共享权重估计的架构排名不一定是真实的架构排名,因为共享权重和子网络的最优权重之间必须存在巨大的差距。一些研究[27]、[28]、[29]指出,共享权重的评估方法准确性低。此外,一些理论和实证研究[30]、[31]、[32]证明,减少共享权重可以有效提高评估架构排名的准确性。块方法通过分割网络的深度,保持原始搜索空间,并解决共享权重的困境,是减少共享权重的理想选择。超网络的每个块在连接到整体搜索之前分别进行训练。因此,我们的每个块都有单独的结构,而不是用相同的结构堆叠,这使我们的网络架构更加灵活。神经网络架构搜索算法的概述显示在算法1中。它使用自监督对比学习方法分别更新架构权重θ和模型权重W,并最终输出最优架构a*,其中u是平衡θ和W更新频率的因子,T表示搜索过程的轮数,N表示构建块的数量,A是架构的集合。
自监督比较学习使用辅助任务从非监督数据中挖掘信息,以提高下游任务的质量,即降雨预测。具体来说,我们复制了一个与在线网络具有相同架构的目标网络。如图2所示,目标网络的初始化参数与在线网络的参数相同。在搜索过程中,根据在线网络的参数进行指数移动平均(EMA)[33]更新。每当输入数据时,它将被随机裁剪成四个种子x1, x2, x'1和x'2,每个网络输入两个。整个架构的主干包含多个块,x1和x2在通过主干时选择不同的路径来搜索最优架构。在线网络根据输出数据的对比损失执行梯度更新[34]。搜索过程的伪代码显示在算法2中。
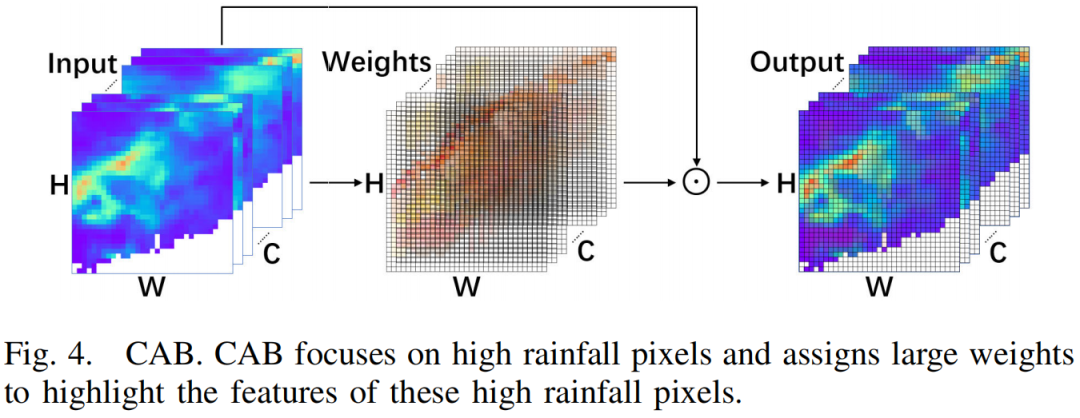
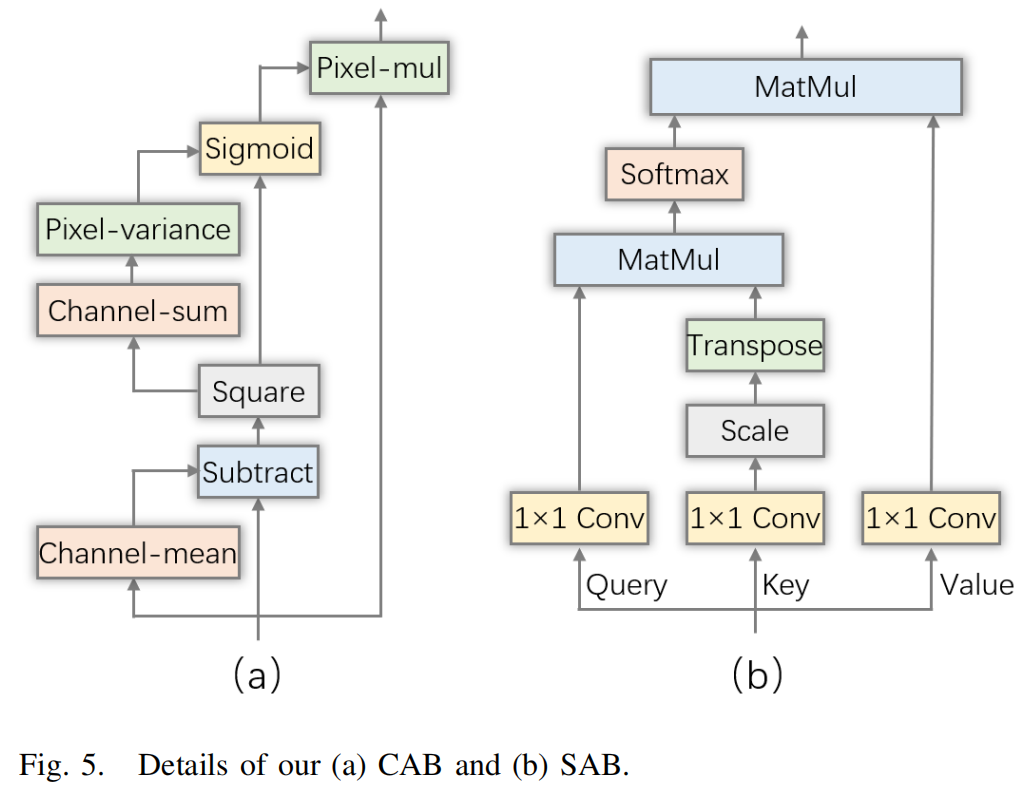
搜索空间:搜索空间是NAS的重要组成部分,它决定了NAS的搜索范围。受现有工作[35]、[36]、[37]的启发,我们设计的搜索空间包括合适的CNN和变换操作,包括RB、SAB和CAB。RB是Resnet[35]的主要结构,用于提取特征。SAB和CAB是变换操作,专注于突出特征显著的像素。为了确保对较少发生的情况(如重降雨)进行更准确的预测,我们引入了基于变换的块CAB和SAB。如图3所示,轻量级和无降雨的比例超过80%,导致预测重降雨变得困难。CAB和SAB用于捕获集合预报数据中的重降雨像素,并为它们分配更大的权重,以突出这些特征。这使得模型能够如图4所示,更准确地预测重降雨区域。图8中的降雨分布可视化也表明,我们的方法在沿海重降雨区域取得了显著的成果。作为一种更强大的基于变换的块,CAB通过其对周围空间的抑制作用来确定一个神经元的重要性,表达式如下:
其中z表示输入数据;表示z的期望;表示内部求和;;w和h分别表示输入数据的宽度和高度;λ = 10^-4是一个超参数。sigmoid(((z - )^2/4 × ((sum((z - )^2)/n) + λ)) + 0.5)相当于CAB基于像素点之间的差异给予像素的权重,差异显著的像素被赋予更高的权重。我们的SAB和CAB的更详细流程图如图5所示。
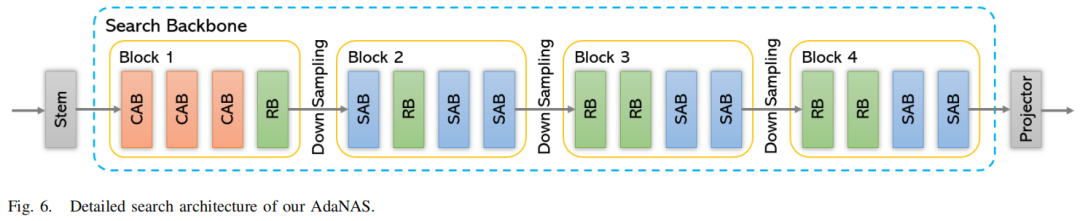
重训练过程:我们使用自监督搜索方法在设计的搜索空间中搜索合适的神经网络模型。搜索到的神经架构如图6所示。该模型主要包括一个干层、一个搜索主干和一个投影器。干层包括一个卷积层、一个批量归一化层、一个激活层和一个最大池化层。投影器包括一个池化层和一个全连接层。该模型在数据集上进行全监督训练,输入为集合预报数据,标签为观测值。与正常的全监督训练不同,我们设计了一个新颖的正则化方程来提高准确性。
正则化函数:像降雨预测这样的回归任务通常使用距离度量,如均方误差(mse)作为正则化函数。然而,mse是正常降雨预测的约束项,而不是精细的降雨级别分类。尽管现有的通过mse优化的方法可以预测一些示例,但由于缺乏有效的约束,它仍然限制了降雨级别预测的性能。因此,我们通过引入一个分类标准HSS来设计正则化函数,以提高降雨级别分类的准确性。HSS是一个分类标准,通过排除随机猜测正确的情况来衡量预测的准确性,如下所示:
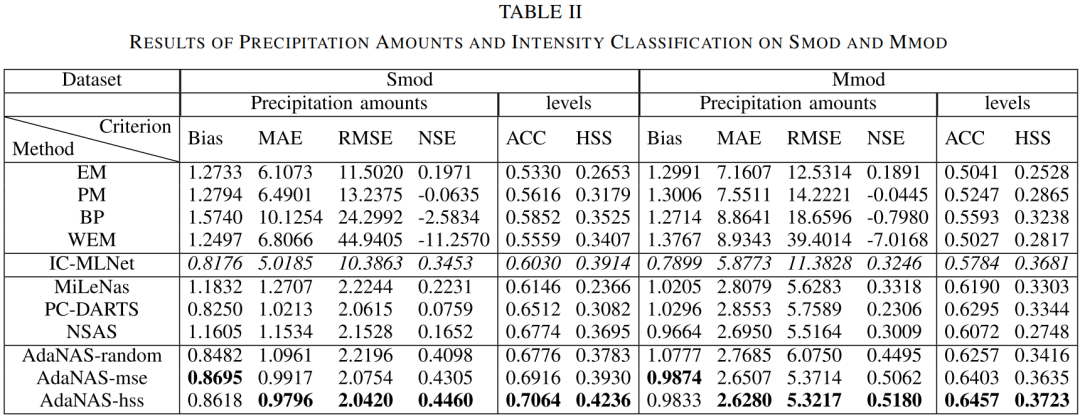
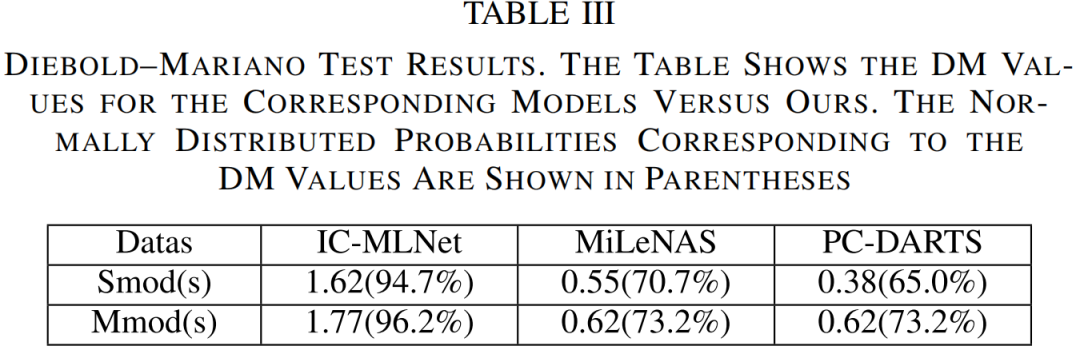
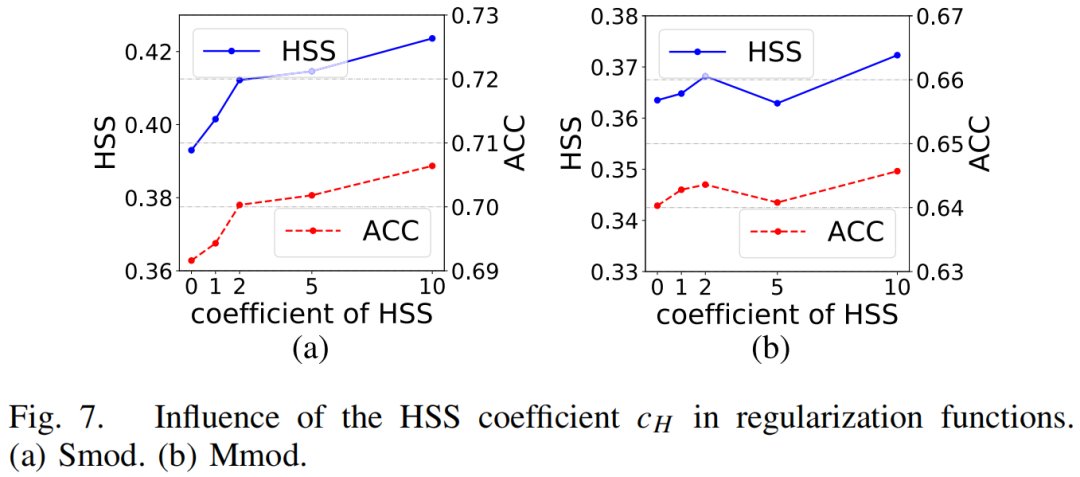
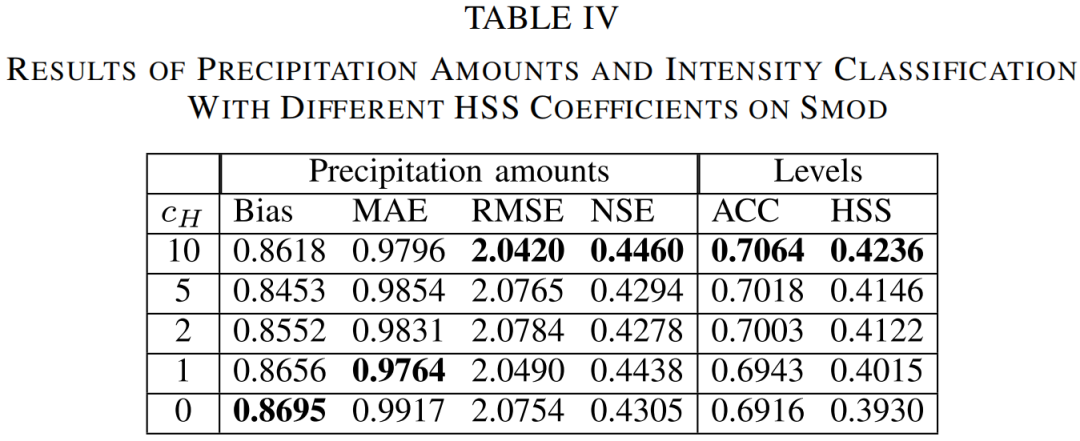
其中lossmse和lossHSS分别是降水量和强度分类的损失;cH是系数;ε是一个非常小的常数,这里我们取10^-10。第IV-C节显示,引入lossHSS的正则化函数的性能得到了显著提高,其性能受到cH系数的影响。
IV. 实验
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。
· END ·
🌟 想要变身计算机视觉小能手?快来「小白玩转Python」公众号!
回复“Python视觉实战项目”,解锁31个超有趣的视觉项目大礼包!🎁

本文仅供学习交流使用,如有侵权请联系作者删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









