






点击下方卡片,关注“小白玩转Python”公众号
为了一项研究,我需要减少YOLOv8的推理时间。在这项研究中,我使用了自己的电脑而不是Google Colab。我的电脑有一个Intel i5(第12代)处理器,我的GPU是NVIDIA GeForce RTX 3050。这些信息很重要,因为我在一些方法中使用了CPU,在其他方法中使用了GPU。
原始模型使用情况
为了测试,我们使用了Ultralytics提供的YOLOv8n.pt模型,并使用bus.jpg图像进行评估。我们将分析获得的时间值和结果。要了解模型的性能,还要知道它运行在哪个设备上——无论是使用CUDA GPU还是CPU。
# cuda
import cv2
import matplotlib.pyplot as plt
from ultralytics import YOLO
import torch
yolov8model = YOLO("yolov8n.pt")
img = cv2.imread("bus.jpg")
results = yolov8model.predict(source=img, device='cuda')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0].tolist()
confidence = box.conf[0].item()
class_id = int(box.cls[0].item())
cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2)
cv2.putText(img, f'ID: {class_id} Conf: {confidence:.2f}',
(int(x1), int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
used_device = next(yolov8model.model.parameters()).device
print("Model is running on:", used_device)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis('off')
plt.show()

# cpu
import cv2
import matplotlib.pyplot as plt
from ultralytics import YOLO
import torch
yolov8model = YOLO("yolov8n.pt")
img = cv2.imread("bus.jpg")
results = yolov8model.predict(source=img, device='cpu')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0].tolist()
confidence = box.conf[0].item()
class_id = int(box.cls[0].item())
cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2)
cv2.putText(img, f'ID: {class_id} Conf: {confidence:.2f}',
(int(x1), int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis('off')
plt.show()
used_device = next(yolov8model.model.parameters()).device
print("Model is running on:", used_device)

现在,我们有一个起点。具体来说,对于bus.jpg图像,模型在CPU上的推理时间是199.7毫秒,在GPU上是47.2毫秒。

剪枝
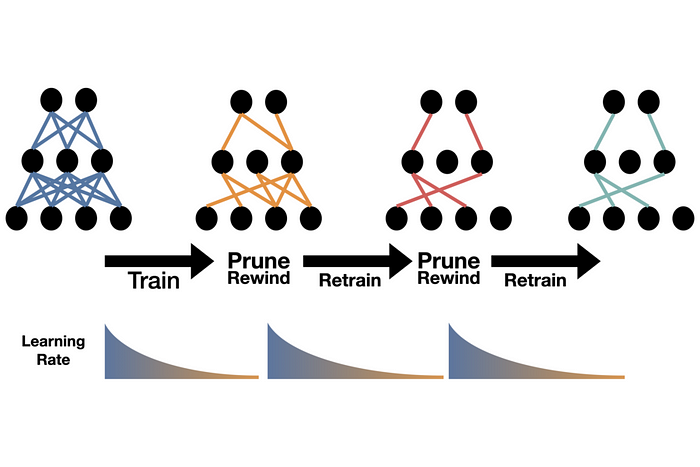
我们使用的第一个方法是剪枝模型。剪枝改变了模型并创建了一个更高效的版本。有些方法修改了模型本身,而其他方法改变了输入或直接影响推理。在剪枝中,模型中较不重要或影响最小的连接被移除。这导致了一个更小、更快的模型,但它可能会对准确性产生负面影响。
import torch
import torch.nn.utils.prune as prune
from ultralytics import YOLO
def prune_model(model,amount=0.3):
for module in model.modules():
if isinstance(module,torch.nn.Conv2d):
prune.l1_unstructured(module,name="weight",amount=amount)
prune.remove(module,"weight")
return model
model = YOLO("yolov8n.pt")
#results= model.val(data="coco.yaml")
#print(f"mAP50-95: {results.box.map}")
torch_model = model.model
print(torch_model)
print("Prunning model...")
pruned_torch_model = prune_model(torch_model,amount=0.1)
print("Model pruned.")
model.model =pruned_torch_model
print("Saving pruned model...")
model.save("yolov8n_trained_pruned.pt")
print("Pruned model saved.")通常,一种方法被用来比较数据集;然而,在这个例子中,使用了大约18 GB的数据集的通用yolov8n.pt模型。在这个例子中,没有使用coco.yaml文件。
我将分享使用的GPU的结果,我们将更新比较图,因为应用不同的参数时时间可能会改变。通常,我无法弄清楚时间为何会改变,但这可能是由于内存或其他因素。
# cuda pruned
import cv2
import matplotlib.pyplot as plt
from ultralytics import YOLO
import torch
yolov8model = YOLO("yolov8n_trained_pruned.pt")
img = cv2.imread("bus.jpg")
results = yolov8model.predict(source=img, device='cuda')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0].tolist()
confidence = box.conf[0].item()
class_id = int(box.cls[0].item())
cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2)
cv2.putText(img, f'ID: {class_id} Conf: {confidence:.2f}',
(int(x1), int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
used_device = next(yolov8model.model.parameters()).device
print("Model is running on:", used_device)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis('off')
plt.show()
正如你看到的,结果有点令人困惑;ID和blob不准确。

然而,当我们比较推理时间时,剪枝模型在CPU和GPU上都比原始模型表现略好。剪枝模型的问题是它会影响结果,但它减少了模型的推理时间。
改变批量大小
在确定模型训练或预测的批量大小时,我们模型中同时处理的帧数至关重要。我创建了一个循环来识别最优批量大小,因为增加批量大小有时可能会产生负面影响。然而,我注意到每次尝试时最优批量大小都会改变。我尝试平均结果,但这种方法是不充分的。为了说明我的发现,我将分享一张我的初步试验的表格,用红点突出显示最优批量大小。
import cv2
import matplotlib.pyplot as plt
from ultralytics import YOLO
import torch
import time
yolov8model = YOLO("yolov8n.pt")
img = cv2.imread("bus.jpg")
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
inference_times = []
for batch_size in range(1, 41):
start_time = time.time()
results = yolov8model.predict(source=img_rgb, device='cuda', batch=batch_size)
end_time = time.time()
inference_time = end_time - start_time
inference_times.append((batch_size, inference_time))
print(f"Batch Size: {batch_size}, Inference Time: {inference_time:.4f} seconds")
plt.figure(figsize=(10, 5))
batch_sizes = [bt[0] for bt in inference_times]
times = [bt[1] for bt in inference_times]
min_time_index = times.index(min(times))
min_batch_size = batch_sizes[min_time_index]
min_inference_time = times[min_time_index]
plt.plot(batch_sizes, times, marker='o')
plt.plot(min_batch_size, min_inference_time, 'ro', markersize=8)
plt.title('Inference Time vs. Batch Size')
plt.xlabel('Batch Size')
plt.ylabel('Inference Time (seconds)')
plt.xticks(batch_sizes)
plt.grid()
plt.show()
best_results = yolov8model.predict(source=img_rgb, device='cuda', batch=min_batch_size)
for result in best_results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0].cpu().numpy()
conf = box.conf[0].cpu().numpy()
cls = int(box.cls[0].cpu().numpy())
cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 255), 2)
cv2.putText(img, f'Class: {cls}, Conf: {conf:.2f}', (int(x1), int(y1) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
plt.figure(figsize=(10, 10))
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.title(f'Results with Batch Size {min_batch_size}')
plt.axis('off')
plt.show()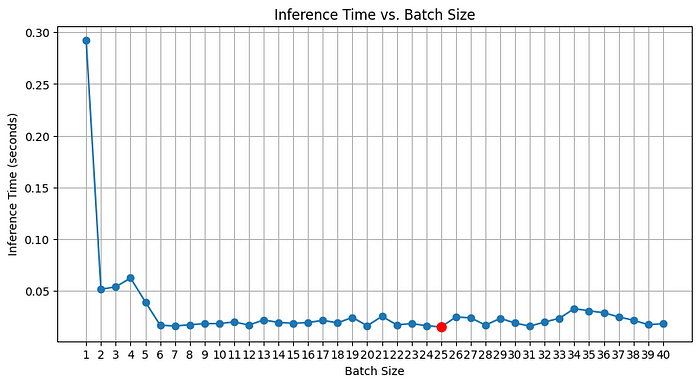
硬件加速方法
为了提高YOLOv8模型的性能,另一个选择是使用硬件加速。为此目的有几种工具可用,比如TensorRT和OpenVINO。
TensorRT
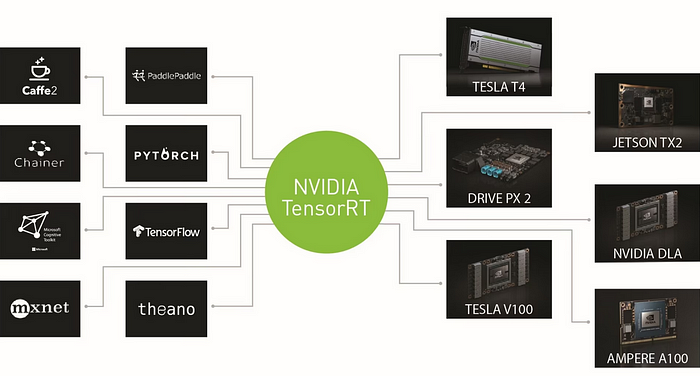
TensorRT是一种使用NVIDIA硬件优化推理效率的方法。在这部分中,我使用了带有T4 GPU的Google Colab来比较标准模型和TensorRT优化模型的性能。让我们从如何将我们的模型转换为TensorRT格式开始。首先,我们需要将模型文件上传到Colab,然后编写以下代码:
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.export(format="engine")然后,我们使用bus.jpg测试模型,TensorRT优化模型的推理时间为6.6毫秒。相比之下,标准模型的推理时间为6.9毫秒。从结果来看,由于更先进的T4硬件,TensorRT模型的性能略优于标准模型。
import cv2
import matplotlib.pyplot as plt
from ultralytics import YOLO
import torch
yolov8model = YOLO('yolov8n.engine')
img = cv2.imread("bus.jpg")
results = yolov8model.predict(source=img, device='cuda')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0].tolist()
confidence = box.conf[0].item()
class_id = int(box.cls[0].item())
cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2)
cv2.putText(img, f'ID: {class_id} Conf: {confidence:.2f}',
(int(x1), int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
used_device = yolov8model.device
print("Model is running on:", used_device)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis('off')
plt.show()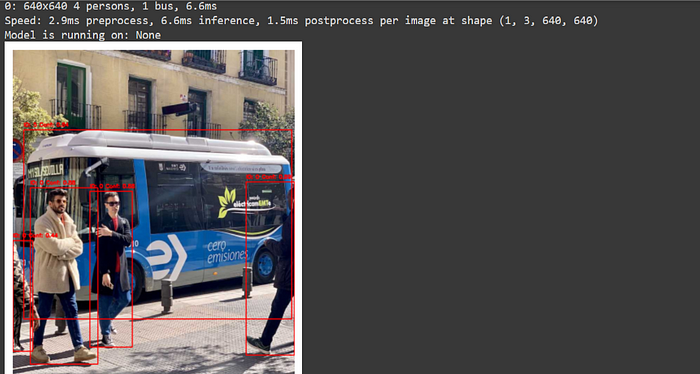
OpenVINO
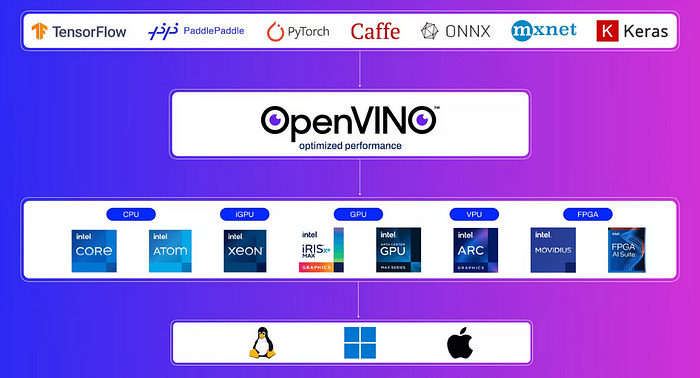
OpenVINO是一个主要为优化模型性能而设计的套件,特别是在Intel硬件上。它可以显著提高CPU性能,通常在常规使用中可提高多达3倍。让我们从将我们的模型转换为OpenVINO格式开始。
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
model = YOLO("yolov8n.pt")
# Export the model
model.export(format="openvino") # creates 'yolov8n_openvino_model/'
# Load the exported OpenVINO model
ov_model = YOLO("yolov8n_openvino_model/")
import cv2
import matplotlib.pyplot as plt
from ultralytics import YOLO
yolov8model = YOLO('yolov8n_openvino_model/', task="detect")
img = cv2.imread("bus.jpg")
results = yolov8model.predict(source=img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0].tolist()
confidence = box.conf[0].item()
class_id = int(box.cls[0].item())
cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2)
cv2.putText(img, f'ID: {class_id} Conf: {confidence:.2f}',
(int(x1), int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis('off')
plt.show()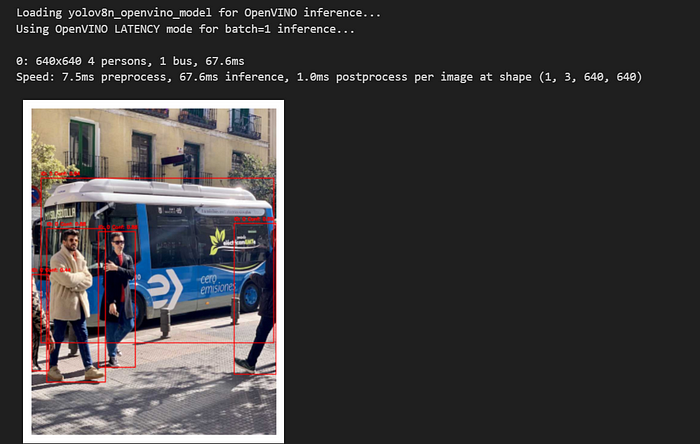
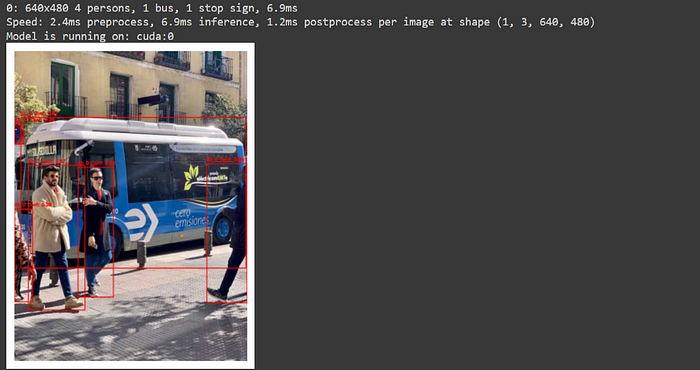
正如你看到的,在CPU性能上OpenVINO模型的推理时间略有下降。以下是我尝试的不同方法的比较结果。

总之,如果你有一块高级GPU,使用TensorRT是最佳选择。然而,如果你在配备Intel CPU的计算机上工作,OpenVINO是首选。不同的方法会导致不同的推理时间,因此每种方法都进行了多次测试以观察差异。

· END ·
🌟 想要变身计算机视觉小能手?快来「小白玩转Python」公众号!
回复“Python视觉实战项目”,解锁31个超有趣的视觉项目大礼包!🎁

本文仅供学习交流使用,如有侵权请联系作者删除

















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









