







 本文详细分析了YOLOv4的Bag of specials,包括增加感受野的技术如SPPNet、ASPP和RFB,以及注意力机制的SE、SAM和Modified SAM。这些方法通过改变网络结构和增加推理成本,提高了目标检测的精度。
本文详细分析了YOLOv4的Bag of specials,包括增加感受野的技术如SPPNet、ASPP和RFB,以及注意力机制的SE、SAM和Modified SAM。这些方法通过改变网络结构和增加推理成本,提高了目标检测的精度。
一文总结YOLOv4所列的Bag of specials
YOLOv4
继上次写了一文总结YOLOv4所列的Bag of freebies之后,接下来我们分析一下YOLOv4所列出来的Bag of specials方法。
Bag of specials
Bag of specials,顾名思义,就是“一堆特价包”的意思,在作者看来,就是一些通过增加推理成本,改变网络结构,来提高目标检测精度的方法。
增加感受野
目标检测网络的精度和网络的感受野大小密切相关,感受野过小可能无法识别大尺度物体,从而导致目标检测网络精度下降。
SPPNet
论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文地址:https://arxiv.org/pdf/1406.4729.pdf
SPPNet称为空间金字塔池化网络,其思路其实很简单,就是为了让网络能够适应不同尺度的图像输入,避免对图片进行裁剪或者缩放,导致位置信息丢失。
由于卷积层在面对不同尺度的输入图像时,会生成大小不一样的特征图,会对网络的训练带来较大的麻烦,因而SPPNet就通过将卷积层最后一层的池化层替换为金字塔池化层,固定输入的特征向量的大小。
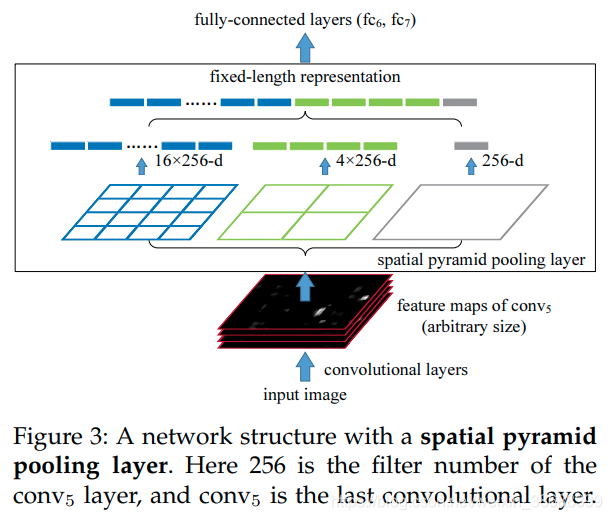
如图所示,金字塔池化层就是固定了池化层的大小和数量,在面对不同尺度的特征图时,也能通过金字塔池化层来固定输出特征向量的大小(图中使用了3个不同大小的池化层,分别是4×4,2×2和1×1,这样每张特征图提取的特征向量长度就是4×4+2×2+1×1=21)
SPPNet论文中详细的训练,整个过程是: 首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。(这一步和R-CNN一样)
特征提取阶段。这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到特征图,然后在特征图中找到各个候选框的区域,再对各个候选框采用空间金字塔池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后再进入CNN,所有的候选框都要经过CNN提取特征,而SPP-Net只需要一次对整张图片进行特征提取,速度会大大提升。
最后一步,采用SVM算法进行特征向量分类识别。
ASPP
论文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs
论文地址:http://export.arxiv.org/pdf/1606.00915
在介绍ASPP之间,需要先介绍dilated convolution(空洞卷积),顾名思义,空洞卷积就是通过在卷积核中填充空洞,来增大感受野。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5498
5498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









