







目录
1.传统翻译模型的不足
目前为止,学习到的翻译模型分别是基于RNN结构的Seq2Seq模型以及基于CNN结构的Seq2Seq模型,但是这两种模型都存在一定的弊端。如基于RNN模型的Seq2Seq模型,如下:
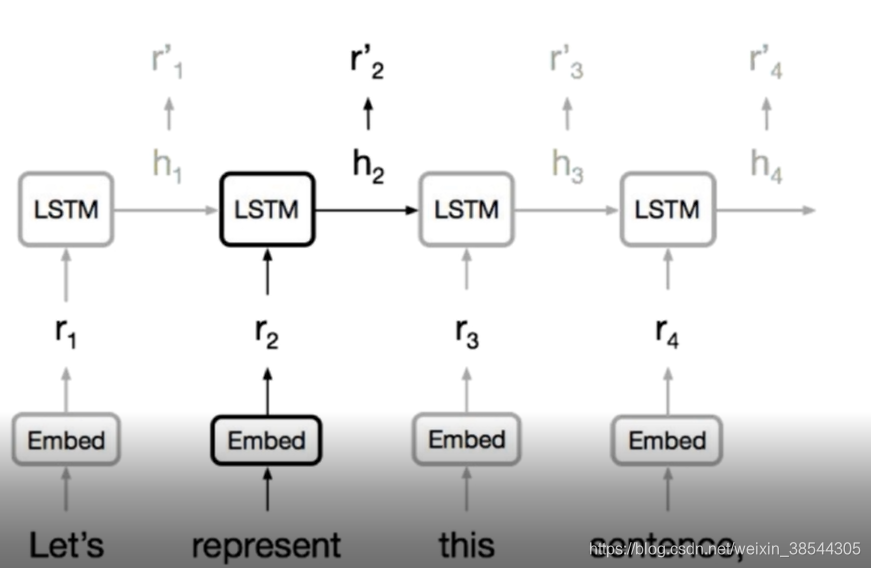
其一大弊端就是压缩过度,即编码器其将一整个句子压缩为单个上下文向量,造成了信息损失。其次RNN串行的处理方式,在训练上耗时及长。CNN通过将每个单词级嵌入别的压缩为一个上下文向量,这里说每个单词也是上下文向量是因为经过多层以后,每个单词其实是间接的可以看到全文的,CNN降低了这种信息压缩,多个卷积核目标使得CNN在特征提取的时候侧重不同的语义信息。同时CNN在编码的时候,通过并行处理的方式进行处理,加快的训练的速度。CNN大致结构如下:
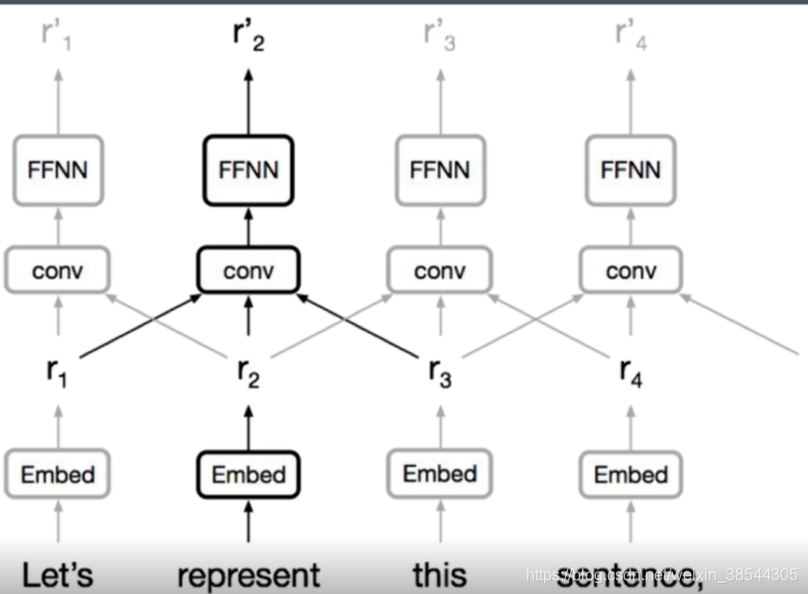
但是CNN也并非完美的,其在感受视野是有限的,即一个卷积操作的感受视野仅仅为卷积核大小,仅仅提取的是卷积核内的词特征。故我们希望编码能想CNN那样并行,多通道的处理特征数据,同时在感受视野上又不仅仅局限于卷积核。大名鼎鼎的《attention is all your need》这篇文章提出了解决办法:Transformer结构,其多头注意力机制是更是重中之中。Transformer提出以后其一直在翻译界的最佳模型,种种改进也是基于这个transformer结构,更有传言自注意力机制可以取代CNN,到目前为止,Transformer依旧是翻译领域的最佳模型,以下将详细介绍各模型,并实现。其模型整体如下:
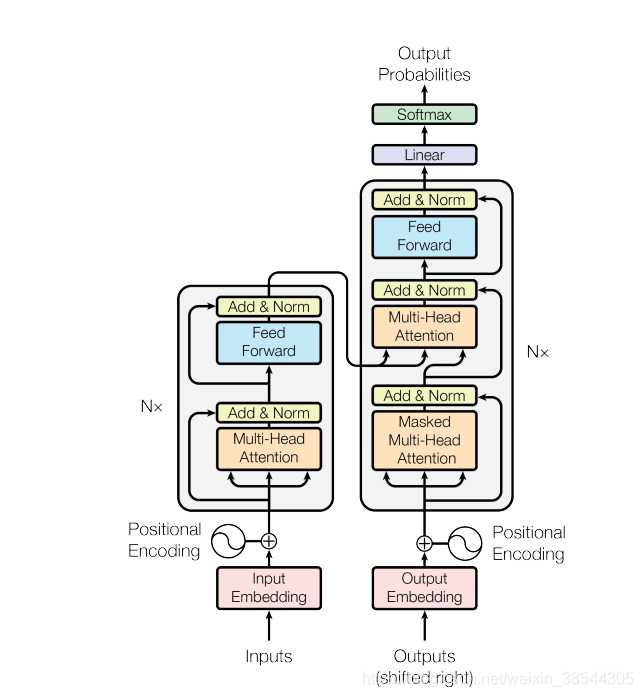
以下将结合代码逐步去仔细讲解模型的每一步。
2.模型实现
工具:Jupyter
2.1数据准备
数据依旧采用Multi30k中的德->英的数据,其数据准备的操作与之前无异:
import spacy
import torch
from torchtext.data import Field,BucketIterator
from torchtext.datasets import Multi30kde_seq=spacy.load("de_core_news_sm")
en_seq=spacy.load("en_core_web_sm")def de_tokenize(text):
return [word.text for word in de_seq.tokenizer(text)]
def en_tokenize(text):
return [word.text for word in en_seq.tokenizer(text)]
SRC=Field(tokenize=de_tokenize,
lower=True,
init_token="<sos>",
eos_token="<eos>",
batch_first=True)
TRG=Field(tokenize=en_tokenize,
lower=True,
init_token="<sos>",
eos_token="<eos>",
batch_first=True)train_data,val_data,test_data=Multi30k.splits(exts=(".de",".en"),
fields=(SRC,TRG))SRC.build_vocab(train_data,min_freq=2)
TRG.build_vocab(train_data,min_freq=2)batch=128
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_iter,val_iter,test_iter=BucketIterator.splits(
(train_data,val_data,test_data),
batch_size=batch,
device=device
)测试:
for example in train_iter:
src=example.src
trg=example.trg
break
print(src.shape,trg.shape)结果:
torch.Size([128, 27]) torch.Size([128, 25])2.2编码器
编码器的结构如下:
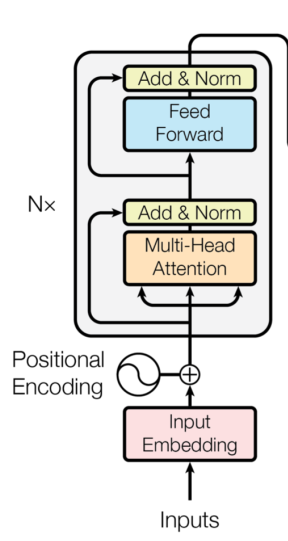
源句inputs经过位置编码嵌入(为什么需要位置嵌入CNN章篇已说),到N(6)层Transformer模型中去。略去了在实现中反复的线性维度变化,Transformer将嵌入层与transformer隐层的维度设为相同。经Transformer处理后的源句输入输出维度相同,此时每个词级别的得到一个上下文向量。因此我们encoder的大致框架如下。
class Encoder(nn.Module):
def __init__(self,hid_size,src_vocab_size,n_layers,device,dropout=0.2):
#hid_size:隐层维度与嵌入层维度
#src_vocab_size:德语词库大小
#n_layers:transformer的层结构
self.token_emb=nn.Embedding(src_vocab_size,hid_size,padding_idx=1)
self.pos_emb=Position_wise(hid_size)#当前还未实现,这里先定义
self.layers=nn.ModuleList([
Transformer()
for _ in range(n_layers)
])
self.dropout=nn.Dropout(dropout)
#主归一化功能
self.scale=torch.sqrt(torch.FloatTensor([hid_size])).to(device)
def forward(self,src):
#对输入的源句嵌入
#src[batch src_len]
src=self.token_emb(src)
#src[batch src_len hid_size]
#对词嵌入嵌入编码信息
pos=self.pos_emb(src)
#pos[batch src_len hid_size]
intput_transformer=self.dropout(src*self.scale+pos)
#intput_transformer[batch src_len hid_size]
for transform in self.layers:
intput_transformer=transform(intput_transformer)
#intput_transformer[batch src_len hid_size]
return intput_transformer可以看到上述代码中其实只是一个粗加工,很多细节都没填写完整,比如各种其他结构,以及初始参数,我们将在后续模块讲解中逐步完善。
2.3位置编码
位置编码主要是在词嵌入的基础上添加词序的位置信息,transformer中位置编码的计算公式如下:
PE代表的是一个与词嵌入相同维度的向量,其中向量中的每个元素对应的位置分别为奇偶。pos代表的是词在句中的位置,取值范围为[0,seq_len),则代表元素在向量的维度序号,其取值范围为:[0,hid_size/2)(比如词嵌入维度为512,那么0,1向量的i为0;1,2为1...510,512为255)。
为嵌入层的维度。
这里位置编码不展开细说(细说又是一篇博客),想要进一步细看,可以参考:Transformer中的Positional Encoding - mathor
其大致图像如下所示:
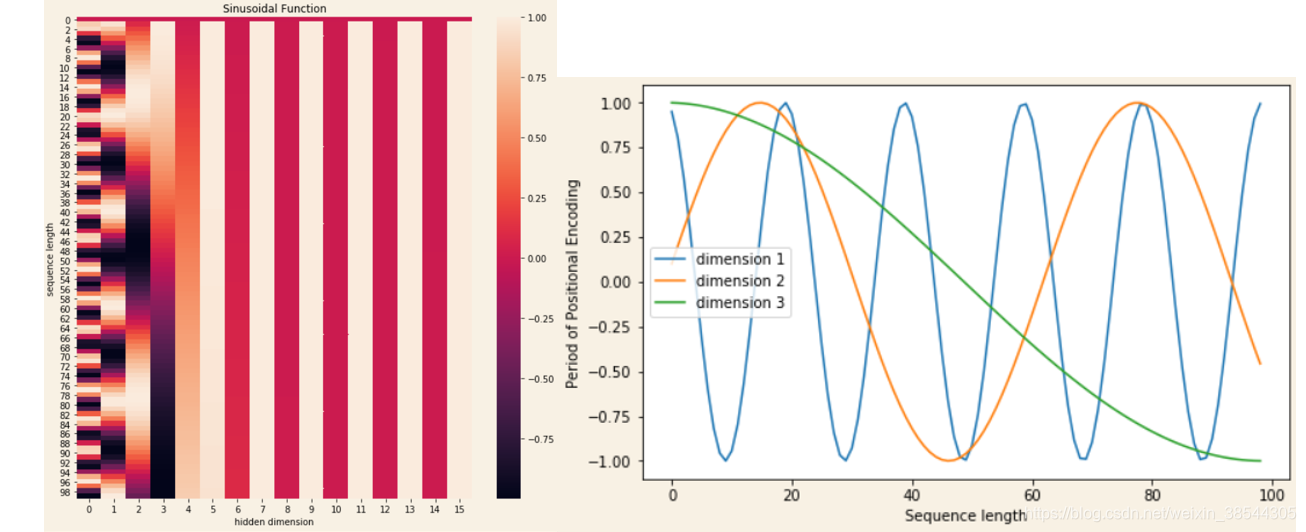
若看不明白图像,推荐看一下那篇参考,位置编码需要满足:
(1)它应该为每个字输出唯一的编码
(2)不同长度的句子之间,任何两个字之间的差值应该保持一致
(3)它的值应该是有界的
在位置编码上为了方便实现,对上式进行等价转换
我们在实现的时候将正弦函数余弦函数里面两个分开计算(也是因为pos和i为变量),最后按位相乘计算
class Position_wise(nn.Module):
def __init__(self,device):
super(Position_wise,self).__init__()
self.device=device
def forward(self,src):
#src[batch src_len hid_size]
batch=src.shape[0]
src_len=src.shape[1]
d_model=src.shape[2]
pos_embedd=torch.zeros_like(src).to(device)
#pos_embedd[batch src_len d_model]
pos=torch.arange(0,src_len).unsqueeze(0).unsqueeze(-1).to(self.device)
#pos[1 src_len 1]
pos=pos.repeat(batch,1,int(d_model/2))
#pos[batch src_len d_model/2]
"""
在计算位置嵌入的时候,每个词所在嵌入维度计算上,pos是是一样的
若嵌入层维度为8其实就是写成
[
[0,0,0,0],
[1,1,1,1],
[2,2,2,2],
[3,3,3,3],
...]
[
[0,0,0,0],
[1,1,1,1],
[2,2,2,2],
[3,3,3,3],
...的形式
]
...
为了方便计算操作
"""
div=torch.exp(torch.arange(0,d_model/2)*(-math.log(10000.0)/d_model)).to(device)
"""
在计算位置嵌入的时候,每个嵌入维度计算中的i,在奇偶上是一样的
我们的计算应该是希望写成
[
[0,0,1,1],
[0,0,1,1],
[0,0,1,0],
...
]
[
[0,0,1,1],
[0,0,1,1],
[0,0,1,1],
...
]
...
但是这样是有些冗余的,奇偶完全可以通过切片步长分开(也是基于这个原因pos的d_model写成d_model/2),因此我们写成:
[
[0,1],
[0,1],
[0,1],
...
]
[
[0,1],
[0,1],
[0,1],
...
]
...
"""
#div[d_model/2]
pos_embedd[:,:,0::2]=torch.sin(pos*div)
pos_embedd[:,:,1::2]=torch.cos(pos*div)
return pos_embedd测试:
a=torch.randn(1,4,4).to(device)
aa=torch.randn(1,4,4).to(device)#假设其为词嵌入
test=Position_wise(device)
pos=test(a)
pos结果:
tensor([[[ 0.0000, 1.0000, 0.0000, 1.0000],
[ 0.8415, 0.5403, 0.0998, 0.9950],
[ 0.9093, -0.4161, 0.1987, 0.9801],
[ 0.1411, -0.9900, 0.2955, 0.9553]]], device='cuda:0')此时我们可以对Encoder模型进行细加工位置编码模块:
class Encoder(nn.Module):
def __init__(self,hid_size,src_vocab_size,n_layers,device,dropout=0.2):
#hid_size:隐层维度与嵌入层维度
#src_vocab_size:德语词库大小
#n_layers:transformer的层结构
self.token_emb=nn.Embedding(src_vocab_size,hid_size,padding_idx=1)
self.pos_emb=Position_wise(device)
self.layers=nn.ModuleList([
Transformer()
for _ in range(n_layers)
])
self.dropout=nn.Dropout(dropout)
#主归一化功能
self.scale=torch.sqrt(torch.FloatTensor([hid_size])).to(device)
def forward(self,src):
#对输入的源句嵌入
#src[batch src_len]
src=self.token_emb(src)
#src[batch src_len hid_size]
#对词嵌入嵌入编码信息
pos=self.pos_emb(src)
#pos[batch src_len hid_size]
intput_transformer=self.dropout(src*self.scale+pos)
#intput_transformer[batch src_len hid_size]
for transform in self.layers:
intput_transformer=transform(intput_transformer)
#intput_transformer[batch src_len hid_size]
return intput_transformer2.4Transformer模块
Transformer模块中主要包含两层,分别是多头自注意力机制层以及简单的前馈层,其模型结构如下:
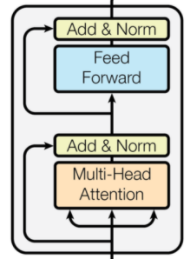
一个Transfomer经过4步操作,首先第一步是自注意力机制层,通过自注意力机制层去提取当前词与其他词的特征关系(这种特征关系可能是词序关系,也有可能是语义上的关系);第二步则是残差连接与层正则化;第三步是简单的2层前馈神经网络;第四步是对前馈层的输出进行残差连接与正则化。其中我们将多头自注意力机制层与前馈层单独拿出来写成。
class Transform(nn.Module):
def __init__(self,hid_size,device,dropout=0.2):
super(Transform,self).__init__()
self.self_attention=MultiHeadAttention()
self.self_attention_layer_norm=nn.LayerNorm(hid_size)
self.feedforward=FeedfordNN(hid_size,pf_dim)
self.feedforward_layer_norm=nn.LayerNorm(hid_size)
self.dropout=nn.Dropout(dropout)
def forward(self,src,src_masked):
#src为带位置编码的词嵌入
#src[batch src_len hid_size]
#经过多头自自注意力
_src,attention=self.self_attention(src,src_masked)
#进行残差连接并层归一化
#src[batch src_len hid_size]
src=self.self_attention_layer_norm(src+self.dropout(_src))
#src[batch src_len hid_size]
#经过前馈神经网络层
_src=self.feedforward(src)
#进行残差连接并进行层归一化
src=self.feedforward_layer_norm(src+self.dropout(_src))
return src2.5Multi-Head Attention
Transformer模型结构其实不难,以下重点讲解多头注意力机制。其实Transformer主要的创新也就在MultiHeadAttention。在注意力机制中,我们提到attn的计算要有三个变量,QKV。即查询向量、键向量与值向量。自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。此外,自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题,这解决了CNN视野有限的问题。而多头则是借鉴了CNN多个卷积核模板,表示关注不同的特征点。
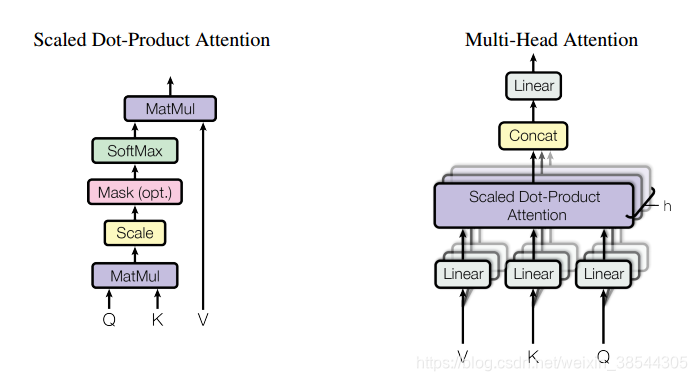
自注意力机制的计算过程:
1.根据嵌入向量经QKV三个矩阵得到q,k,v三个向量;
2.为每个向量计算一个score: ;
3.为了梯度的稳定,Transformer使用了score归一化,即除以 ;
4.对score施以softmax激活函数;
5.softmax点乘Value值v,得到加权的每个输入向量的评分v;
6.相加之后得到最终的输出结果z :
7.多个注意力投的结果进行拼接并通过线性层映射到输入维度
具体的模型过程如下:
class MultiHeadAttention(nn.Module):
def __init__(self,hid_size,n_heads,device,dropout=0.1):
super(MultiHeadAttention,self).__init__()
#三个线性层模板
self.Q=nn.Linear(hid_size,hid_size)
self.K=nn.Linear(hid_size,hid_size)
self.V=nn.Linear(hid_size,hid_size)
#多头拼接层
self.fc=nn.Linear(hid_size,hid_size)
#各种参数记录
self.hid_size=hid_size
self.n_heads=n_heads
self.heads_dim=hid_size//n_heads
self.scale=torch.sqrt(torch.FloatTensor([self.heads_dim])).to(device)
self.dropout=nn.Dropout(dropout)
self.device=device
def forward(self,q,k,v,masked=None):
#q[batch seq_len hid_size]
#k[batch seq_len hid_size]
#v[batch seq_len hid_size]
#首先经历三个线性变化得到q,v,k向量
q=self.Q(q)
k=self.K(k)
v=self.V(v)
#q[batch seq_len hid_size]
#k[batch seq_len hid_size]
#v[batch seq_len hid_size]
batch=q.shape[0]
#由于是多头自注意力,我们将维度hid_size分成n_heads份
#每一个多头我们希望其关注不同侧重点
q=q.reshape(batch,-1,self.n_heads,self.heads_dim)
#q[batch seq_len n_heads heads_dim]
q=q.permute(0,2,1,3)
#q[batch n_heads seq_len heads_dim]
k=k.reshape(batch,-1,self.n_heads,self.heads_dim).permute(0,2,1,3)
v=v.reshape(batch,-1,self.n_heads,self.heads_dim).permute(0,2,1,3)
#计算注意力权重
#q[batch n_heads seq_len1 heads_dim]
#k[batch n_heads seq_len heads_dim]
#v[batch n_heads seq_len heads_dim]
energy=torch.matmul(q,k.permute(0,1,3,2))/self.scale
#energy[batch n_head seq_len1 seq_len]
#将energy通进行mask忽视pad
if masked is not None:
energy=energy.masked_fill(masked==0,-1e10)
attention=torch.softmax(energy,dim=-1)
#attention[batch n_head seq_len1 seq_len]
#对权重与值向量加权求和得到上下文向量
context=torch.matmul(self.dropout(attention),v)
#context[batch n_head seq_len1 heads_dim]
#拼接各个头并进行维度变化输出
context=context.permute(0,2,1,3).reshape(batch,-1,self.hid_size)
#context[batch seq_len hid_size]
output=self.fc(context)
return output,attention测试:
hid_size=256
n_heads=8mha=MultiHeadAttention(hid_size,n_heads,device).to(device)
masked=(src!=1)
masked=masked.unsqueeze(1).unsqueeze(1).to(device)
testData=torch.randn(batch,src.shape[1],hid_size).to(device)#假src带有位置信息
output,attention=mha(testData,testData,testData,masked)
print(output.shape,attention.shape)结果:
torch.Size([128, 30, 256]) torch.Size([128, 8, 30, 30])2.6前馈神经网络层
此层相对简单,即为两层的前连接映射,第一层为一个非线性映射,激活函数为Relu。第二层则是将高纬转变为嵌入维度。
class FeedfordNN(nn.Module):
def __init__(self,hid_size,pf_dim,dropout=0.1):
super(FeedfordNN,self).__init__()
#hid_size表示嵌入层 隐藏的维度,
#pf_dim表示升维的维度
self.fc1=nn.Linear(hid_size,pf_dim)
self.fc2=nn.Linear(pf_dim,hid_size)
self.dropout=nn.Dropout(dropout)
def forward(self,src):
src=self.dropout(torch.relu(self.fc1(src)))
src=self.fc2(src)
return src将这两个模块写好一些,我们对Transomer模块进行精加工补齐:
class Transform(nn.Module):
def __init__(self,hid_size,n_heads,pf_dim,device,dropout=0.1):
super(Transform,self).__init__()
self.self_attention=MultiHeadAttention(hid_size,n_heads,device)
self.self_attention_layer_norm=nn.LayerNorm(hid_size)
self.feedforward=FeedfordNN(hid_size,pf_dim)
self.feedforward_layer_norm=nn.LayerNorm(hid_size)
self.dropout=nn.Dropout(dropout)
def forward(self,src,src_masked):
#src为带位置编码的词嵌入
#src[batch src_len hid_size]
#经过多头自自注意力
_src,_=self.self_attention(src,src,src,src_masked)
#进行残差连接并层归一化
#src[batch src_len hid_size]
src=self.self_attention_layer_norm(src+self.dropout(_src))
#src[batch src_len hid_size]
#经过前馈神经网络层
_src=self.feedforward(src)
#进行残差连接并进行层归一化
src=self.feedforward_layer_norm(src+self.dropout(_src))
return src测试Transformer模块:
pf_dim=512
trans=Transform(hid_size,n_heads,pf_dim,device).to(device)
output=trans(testData,masked)
print(output.shape)结果为:
torch.Size([128, 30, 256])最后接着完善Encoder模块:
class Encoder(nn.Module):
def __init__(self,hid_size,src_vocab_size,n_layers,n_heads,pf_dim,device,dropout=0.1):
super(Encoder,self).__init__()
#hid_size:隐层维度与嵌入层维度
#src_vocab_size:德语词库大小
#n_layers:transformer的层结构
#n_heads:注意力头的数量
#pf_dim:前馈层上升的维度
self.token_emb=nn.Embedding(src_vocab_size,hid_size,padding_idx=1)
self.pos_emb=Position_wise(device)
self.layers=nn.ModuleList([
Transform(hid_size,n_heads,pf_dim,device)
for _ in range(n_layers)
])
self.dropout=nn.Dropout(dropout)
#主归一化功能
self.scale=torch.sqrt(torch.FloatTensor([hid_size])).to(device)
def forward(self,src):
#获取掩码编码
src_masked=(src!=1)
#src[batch src_len]
src_masked=src_masked.unsqueeze(1).unsqueeze(1)
#src[batch 1 1 src_len]
#对输入的源句嵌入
#src[batch src_len]
src=self.token_emb(src)
#src[batch src_len hid_size]
#对词嵌入嵌入编码信息
pos=self.pos_emb(src)
#pos[batch src_len hid_size]
intput_transformer=self.dropout(src*self.scale+pos)
#intput_transformer[batch src_len hid_size]
for transform in self.layers:
intput_transformer=transform(intput_transformer,src_masked)
#intput_transformer[batch src_len hid_size]
return intput_transformer,src_masked测试:
n_layers=3#原论文是6层
src_vocab_size=len(SRC.vocab)
trg_vocab_size=len(TRG.vocab)enModel=Encoder(hid_size,src_vocab_size,n_layers,n_heads,pf_dim,device).to(device)
output,_=enModel(src)
print(output.shape)结果:
torch.Size([128, 30, 256])2.7解码器
解码器的大致模型结构如下:
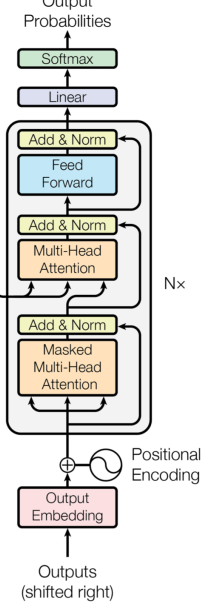
其输入也是的英语也是通过位置嵌入编码,后代入多层的Transformer解码器模块,最后的输出经过一个线性分类层进行判断预测,模型整体框架大致与Endoder相同,实现如下:
class Decoder(nn.Module):
def __init__(self,hid_size,trg_vocab_size,n_layers,n_heads,pf_dim,device,dropout=0.2):
super(Encoder,self).__init__()
#hid_size:隐层维度与嵌入层维度
#src_vocab_size:德语词库大小
#n_layers:transformer的层结构
self.token_emb=nn.Embedding(trg_vocab_size,hid_size,padding_idx=1)
self.pos_emb=Position_wise(device)
self.layers=nn.ModuleList([
Transform2(hid_size,n_heads,pf_dim,device)#Encoder与Decoder这里Transofmer有一些区别,这里也是抽象实现
for _ in range(n_layers)
])
#分类
self.fc=nn.Linear(hid_size,trg_vocab_size)
self.dropout=nn.Dropout(dropout)
#主归一化功能
self.scale=torch.sqrt(torch.FloatTensor([hid_size])).to(device)
def forward(self,enc_outputs,trg):
#对输入的目标句嵌入
#trg[batch trg_len]
trg=self.token_emb(trg)
#trg[batch src_len hid_size]
#对词嵌入嵌入编码信息
pos=self.pos_emb(trg)
#pos[batch src_len hid_size]
intput_transformer=self.dropout(trg*self.scale+pos)
#intput_transformer[batch src_len hid_size]
for transform in self.layers:
intput_transformer=transform(intput_transformer,src_masked)
#intput_transformer[batch src_len hid_size]
output=self.fc(intput_transformer)
#output[batch trg_len trg_vocab_size]
return output2.8解码器的Trnasformer:
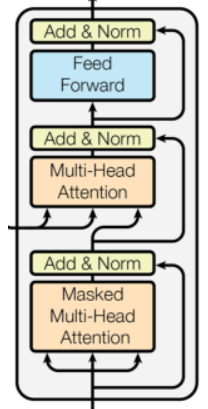
相较于编码器中的Transformer模块,其内部结果多了一层masked多头自注意力层,即里面有两层Muti_self-attention。其本质结构是一样的,不过在一些细节上仍有一些差异:
(1)Masked Mutil-Head Attention
在CNN的时候,我们就曾经提到过编码器的作弊问题,即并行最大的隐患是其正确答案也是感受视野中,而self-attention的视野是全局的,答案那一定是可以知道的。CNN卷积网络是将padding置于句首在使得感受视野规避答案,而在Masked Mutil-Head Attention层中,则是通过mask的操作来盖住答案。即算出能量以后,我希望注意力以后忽略答案部分,具体实现的时候采用保留下三角矩阵的方式:
即给energy上三角部分上负无穷,因此我们的mask可以写成:(假设batch=4 max_len=4)
当然我们还要忽略pad部分,因此mask又可以进一步写成:
在Masked Mutil-Head Attention中其实主要就是为了求解目标端每个词之间的联系,因此QKV的输入为相同的,即上一层的输出或者英语带有位置编码的嵌入。
(2)Mutil-Head Attention
这一层作用于我们之前理解的attention机制是差不多的,主要的作用在于希望Decoder生成词的时候,在编码器端游一个不同词的参考。因此其输入的KV均来自于Encoder层的输出,而Q来自于当前模块的Masked Mutil-Head Attention。
至于前馈神经网络则是于编码器无异,也是双层。
class Transformer2(nn.Module):
def __init__(self,hid_size,n_heads,pf_dim,device,dropout=0.1):
super(Transformer2,self).__init__()
self.device=device
self.masked_mutil_attention=MultiHeadAttention(hid_size,n_heads,device)
self.masked_mutil_attention_layer_norm=nn.LayerNorm(hid_size)
self.mutil_attention=MultiHeadAttention(hid_size,n_heads,device)
self.mutil_attention_layer_norm=nn.LayerNorm(hid_size)
self.feedNN=FeedfordNN(hid_size,pf_dim)
self.feedNN_layer_norm=nn.LayerNorm(hid_size)
self.dropout=nn.Dropout(dropout)
def forward(self,enc_outputs,trg,trg_pad_mask,enc_masked):
#enc_outputs encoder层的输出[batch src_len hide_size]
#trg 带有位置信息的目标句[batch trg_len hid_size]
#enc_masked 源句的掩码信息[batch 1 1 src_len]
#trg_pad_mask[batch 1 1 trg_len]
trg_len=trg.shape[1]
trg_mask_ans=torch.tril(torch.ones((trg_len,trg_len),device=self.device)).bool()
#trg_mask_ans [trg_len trg_len]
trg_mask=trg_pad_mask &trg_mask_ans
#trg_mask_ans[batch 1 trg_len trg_len]
_trg,_=self.masked_mutil_attention(trg,trg,trg,trg_mask)
trg=self.masked_mutil_attention_layer_norm(trg+self.dropout(_trg))
#trg[batch trg_len hid_dize]
_trg,attention=self.mutil_attention(trg,enc_outputs,enc_outputs,enc_masked)
trg=self.mutil_attention_layer_norm(trg+self.dropout(_trg))
#trg[batch trg_len hid_dize]
_trg=self.feedNN(trg)
trg=self.feedNN_layer_norm(trg+self.dropout(_trg))
return trg,attention测试:
trans2=Transformer2(hid_size,n_heads,pf_dim,device).to(device)
testData=torch.randn(batch,trg.shape[1],hid_size).to(device)#假trg带有位置信息
trg_pad_mask=(trg!=1).unsqueeze(1).unsqueeze(1)
output2,a=trans2(output,testData,trg_pad_mask,masked)
print(output2.shape)结果:
torch.Size([128, 27, 256])继续完善Decoder模块:
class Decoder(nn.Module):
def __init__(self,hid_size,trg_vocab_size,n_layers,n_heads,pf_dim,device,dropout=0.1):
super(Decoder,self).__init__()
#hid_size:隐层维度与嵌入层维度
#src_vocab_size:德语词库大小
#n_layers:transformer的层结构
self.token_emb=nn.Embedding(trg_vocab_size,hid_size,padding_idx=1)
self.pos_emb=Position_wise(device)
self.layers=nn.ModuleList([
Transformer2(hid_size,n_heads,pf_dim,device)#Encoder与Decoder这里Transofmer有一些区别,这里也是抽象实现
for _ in range(n_layers)
])
#分类
self.fc=nn.Linear(hid_size,trg_vocab_size)
self.dropout=nn.Dropout(dropout)
#主归一化功能
self.scale=torch.sqrt(torch.FloatTensor([hid_size])).to(device)
def forward(self,trg,enc_outputs,enc_mask):
#trg[batch trg_len]
#enc_outputs[batch src_len hid_size]
#mask[batch 1 1 src_len]
#目标的pad_mask
pad_mask=(trg!=1).unsqueeze(1).unsqueeze(1)
#[batch trg_len]
#对输入的目标句嵌入
#trg[batch trg_len]
trg=self.token_emb(trg)
#trg[batch trg_len hid_size]
#对词嵌入嵌入编码信息
pos=self.pos_emb(trg)
#pos[batch trg_len hid_size]
intput_transformer=self.dropout(trg*self.scale+pos)
#intput_transformer[batch trg_len hid_size]
for transform in self.layers:
intput_transformer,_=transform(enc_outputs,intput_transformer,pad_mask,enc_mask)
#intput_transformer[batch trg_len hid_size]
output=self.fc(intput_transformer)
#output[batch trg_len trg_vocab_size]
return output测试:
deModel=Decoder(hid_size,trg_vocab_size,n_layers,n_heads,pf_dim,device).to(device)
output3=deModel(trg,output,masked)
print(output3.shape)结果:
torch.Size([128, 27, 5893])2.9Seq2Seq模块
即对以上的测试的封装
class Seq2Seq(nn.Module):
def __init__(self,encoder,decoder):
super(Seq2Seq,self).__init__()
self.encoder=encoder
self.decoder=decoder
def forward(self,src,trg):
#src[batch src_len]
#trg[batch src_len]
enc_outputs,enc_mask=self.encoder(src)
outputs=self.decoder(trg,enc_outputs,enc_mask)
return outputs测试:
model=Seq2Seq(enModel,deModel).to(device)
outpus=model(src,trg)
print(outpus.shape)结果:
torch.Size([128, 27, 5893])2.10训练数据
import math,time
from torch.optim import Adamepochs=10
clip=1
criterion=nn.CrossEntropyLoss(ignore_index=1)
optim=Adam(model.parameters(),lr= 0.0005)def initialize_weights(m):
if hasattr(m, 'weight') and m.weight.dim() > 1:
nn.init.xavier_uniform_(m.weight.data)
model.apply(initialize_weights)def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for example in iterator:
src = example.src
trg = example.trg
optimizer.zero_grad()
output=model(src, trg[:,:-1])
#output = [batch trg_len - 1, trg_vacab_size]
#trg = [batch size, trg len]
output=output.reshape(-1, trg_vocab_size)
trg=trg[:,1:].reshape(-1)
#output = [batch*trg_len-1,trg_vacab_size]
#trg = [batch size * trg len - 1]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)def evaluate(model, iterator,criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for example in iterator:
src = example.src
trg = example.trg
output=model(src, trg[:,:-1])
#output = [batch trg_len - 1, trg_vacab_size]
#trg = [batch size, trg len]
output=output.reshape(-1, trg_vocab_size)
trg=trg[:,1:].reshape(-1)
#output = [batch*trg_len-1,trg_vacab_size]
#trg = [batch size * trg len - 1]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secsfor epoch in range(epochs):
start_time = time.time()
train_loss = train(model,train_iter,optim,criterion,clip)
valid_loss = evaluate(model,val_iter,criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')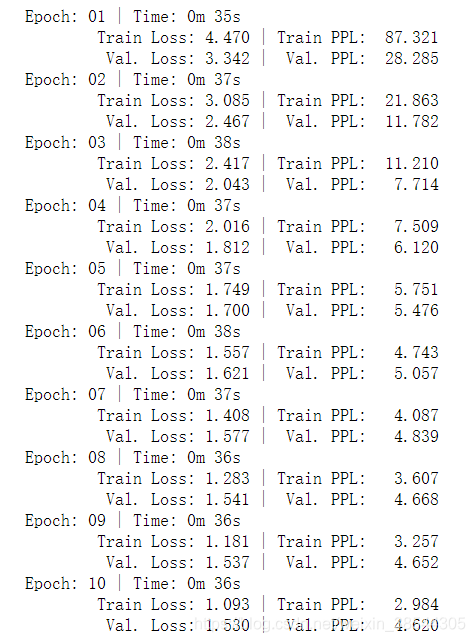
测试集上测试:
test_loss = evaluate(model,test_iter,criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')结果:
| Test Loss: 1.609 | Test PPL: 4.997 |
















 1859
1859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









