







 本文深入探讨了机器学习的基本概念,包括监督学习、非监督学习、半监督学习和强化学习的不同类型,以及中心极限定理、正态分布、最大似然估计等统计学原理的应用。此外,还详细介绍了梯度下降、L1/L2正则化等关键算法,并讨论了模型优化、参数稀疏化的重要性。
本文深入探讨了机器学习的基本概念,包括监督学习、非监督学习、半监督学习和强化学习的不同类型,以及中心极限定理、正态分布、最大似然估计等统计学原理的应用。此外,还详细介绍了梯度下降、L1/L2正则化等关键算法,并讨论了模型优化、参数稀疏化的重要性。
一、了解什么是Machine learning
1、一种映射:
让机器有学习的能力,通过学习,找到可以拟合当前数据类型的最优映射,即
; 其中x为数据集中的元素,y为对应学习任务的输出结果,F为最优的ML模型
2、两个阶段:Training 和 Testing
1)Training
训练数据x + 模型集(一系列的映射) ——> 最优映射,模型 f
2)Testing
测试数据x + 最优映射,模型 f(Training 的结果) ——> 结果(例如:分类任务则结果为对应测试数据的类别)
3、三个步骤:
1)得到模型集(一系列映射 );
2)衡量映射的好坏 ,
;
3)找出最好的映射 ;
4、学习任务
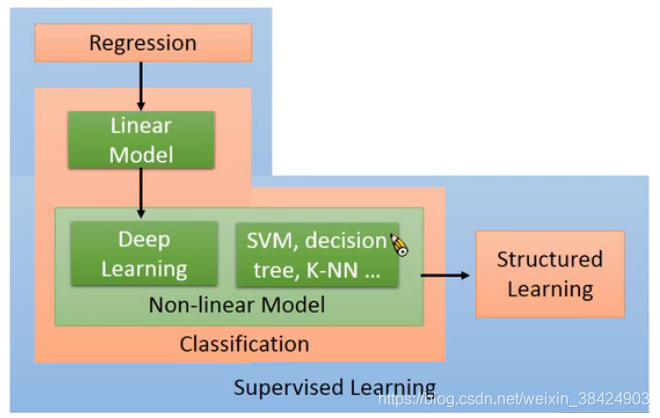
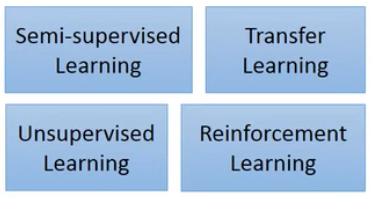
Semi-supervised Learning:部分未标记的数据对已标记数据的训练有一定帮助;未标记类别和已标记类别相同;
Transfer Learning:部分未标记的数据对已标记数据的训练有一定帮助;未标记类别和已标记类别不相同;
Unsupervised Learning:一堆完全未标记的数据或者编码;
Renforcement Learning:对机器学习的结果不再是一个类别,而是该结果的一个得分(该行为的评价),如阿尔法狗;
二、学习中心极限定理,学习正态分布,学习最大似然估计
中心极限定理:对于相互独立的随机变量,其中 i 代表第i个元素,定理表明,当i足够大时,概率分布近似于正态分布;
最大似然估计:对于给定的概率分布D,假定其连续概率分布和离散概率分布为 ,以及一个参数
;通过采样,我们可以从这个分布中随机抽取n个样本,并利用n个样本,我们可以计算出其概率
,而此概率
,我们可能不知道
的值,但这些数据是服从同一分布的。因此我们可以找到一个
是的此时的概率
最大,而使得概率(可能性)最大的
值即被称为
的最大似然估计。
推导回归Loss function

学习损失函数与凸函数之间的关系
模型优化即是在优化损失函数,而损失函数的优化问题可以转化为凸优化问题,即在给定约束条件下,对目标函数的优化过程,损失函数/目标函数都是凸函数。
了解全局最优和局部最优
线性回归一定是全局最优,非凸函数存在局部最优解。
三、学习导数,泰勒展开
泰勒公式是将一个在x=x0处具有n阶导数的函数f(x)利用关于(x-x0)的n次多项式来逼近函数的方法。
若函数f(x)在包含x0的某个闭区间[a,b]上具有n阶导数,且在开区间(a,b)上具有(n+1)阶导数,则对闭区间[a,b]上任意一点x,成立下式:
![]()
其中表示
的n阶导数,等号后的多项式称为函数
在x0处的泰勒展开式,剩余的
是泰勒公式的余项,是
的高阶无穷小。
推导梯度下降公式

写出梯度下降的代码
待补充
四、学习L2-Norm,L1-Norm,L0-Norm
L0范数是指向量中非0的元素的个数。
L1范数是指向量中各个元素绝对值之和。(LASSO)
L2范数是指向量各元素的平方和然后求平方根。(岭回归)
总结:
L1范数和L0范数可以实现稀疏,L1因具有比L0更好的优化求解特性而被广泛应用。
L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已
参数稀疏的好处:
1. 特征选择: 一个关键原因在于它能实现特征的自动选择。简单的说,参数小的特征不怎么起作用,被自动过滤。可以防止过拟合,受噪声干扰较小。
2. 可解释性:另一个青睐于稀疏的理由是,模型更容易解释。简单的说,我们知道是哪些特征使输入映射至该输出结果
推导正则化公式

学习为什么只对w/Θ做限制,不对b做限制
在线性模型中,为偏移项,只会影响拟合曲线(模型函数)上下移动,而对模型拟合的函数形状(阶次和振幅)无影响。相对来说,对函数复杂性产生直接影响的是
参数,因此在做正则时,只对
做限制。更直接的来说,只有
对特征有选择和解释性。
其他补充:
负责模型可能会过拟合
正则的目的:拟合比较平滑的映射,对噪声的干扰越小
Variance与bias:Variance大,体现为overfiting;bias大,体现为underfiting;
模型选择:Variance和bias都很小的模型;可以通过交叉验证的方式;

















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









