







 本文介绍了霍夫曼编码的原理,包括基于字符频率的可变长编码思想,以及如何通过扩展二叉树构建霍夫曼树。文章详细阐述了霍夫曼编码的构造步骤,并讨论了如何利用霍夫曼树进行文本压缩和解压缩。通过C++实现,包括压缩类和解压缩类的设计,以及对FileReader的修改,以提高压缩效率。
本文介绍了霍夫曼编码的原理,包括基于字符频率的可变长编码思想,以及如何通过扩展二叉树构建霍夫曼树。文章详细阐述了霍夫曼编码的构造步骤,并讨论了如何利用霍夫曼树进行文本压缩和解压缩。通过C++实现,包括压缩类和解压缩类的设计,以及对FileReader的修改,以提高压缩效率。
《数据结构、算法与应用 —— C++语言描述》学习笔记 — 优先级队列 — 应用 — 霍夫曼编码
一、原理及构造过程
1、原理
前面我们学习了基于 LZW 算法的文本压缩器,这种算法的依据是子串在文本中的重复出现。而霍夫曼编码是另外一种文本压缩算法,这种算法依据的是不同符号在一段文本中相对出现的频率。假设一个文本是由字符 a、u、x 和 z 组成的字符串,它的长度为1000,每个字符用1字节来储存,共需1000字节(即8000位)。如果每个字符用2位二进制来表示,那么用2000位空间可以表示1000个字符。此外,我们还需要一定的空间来存放编码表,它可以采用如下的存储格式:
符号个数及每个符号分别占8位,每个代码占 ⌈ log 2 ( 符 号 个 数 ) ⌉ \lceil \log_2{(符号个数)} \rceil ⌈log2(符号个数)⌉位。因此,编码表共需48位,压缩比为 8000 2048 = 3.9 \frac{8000}{2048}=3.9 20488000=3.9
利用上述编码方式,字符串 aaxuaxz 的编码为00000110000111。因为每个字符的代码占2位。所以,从左到右,每次从编码中提取2位数字通过编码表编译,便可获得原始字符串。
在字符串 aaxuaxz 中,a 出现3次。一个符号出现的次数称为频率。符号 a、u、x 和 z 在这个字符串中出现的频率分别是3、2、1、1.当不同字符出现的频率有很大差别时,我们可以通过可变长编码来缩短编码串的长度。如果使用编码。如果使用编码(0=a,10=x,110=u,111=z),则该符号串的编码为0010110010111,编码串长度是13位,比原来的14位要稍短一些。当不同字符的出现频率相差更大时,编码串的长度差别就会更明显。
那么如何解码呢?字符串 aaxuaxz 的编码为0010110010111。当从左至右解码时,我们需要知道第一个字符的代码是0、00,还是001.因为没有一个字符的代码以00开头,所以第一个字符的代码必是0。根据编码表,该字符是 a。下一个代码为0、01或010.同理,因为不存在以01打头的代码,因此代码必为0.继续使用这种方法,就可以解码。这种解码能够实现是因为没有任何一个代码是另一个代码的前缀。
2、扩展二叉树与霍夫曼编码
我们可以利用扩展二叉树来派生一个特殊的类,对具有上述前缀性质的代码,实现可变长编码。在一棵扩展二叉树中,从根到外部节点的路径可用来编码,方法是用0表示到左子树的路径,1表示到右子树的路径。
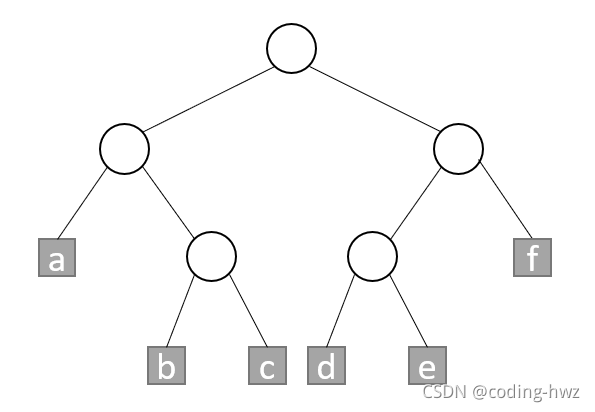
如图所示,从根到节点(a,b,c,d,e,f)的路径分别为(00,010,011,100,101,11)。因为每一个路径对应一个外部节点,而外部节点之间是相互独立的,因此没有一个路径代码是另一个的前缀。因此,这些代码可以分别用来对字符 a~f 进行编码。令 S 是由这些字符组成的字符串, F ( x ) F(x) F(x)是字符 x 出现的频率。若利用这些代码对 S 进行编码,则编码位串的长度: 2 ∗ F ( a ) + 3 ∗ F ( b ) + 3 ∗ F ( c ) + 3 ∗ F ( d ) + 3 ∗ F ( e ) + 2 ∗ F ( f ) 2*F(a)+3*F(b)+3*F(c)+3*F(d)+3*F(e)+2*F(f) 2∗F(a)+3∗F(b)+3∗F(c)+3∗F(d)+3∗F(e)+2∗F(f)
对于一棵具有 n 个外部节点的扩展二叉树,且外部节点标记为1,···,n,其对应的编码位串的长度为: W E P = ∑ 1 n L ( i ) ∗ F ( i ) WEP=\sum_1^nL(i)*F(i) WEP=1∑nL(i)∗F(i)
其中 L ( i ) L(i) L(i)表示从根到外部节点 i 的路径长度;WEP 是二叉树的加权外部路径长度。为了缩短编串的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









