






 本文介绍了multi-sample dropout技术,它是dropout技术的变形。该技术创建多个dropout样本并平均损失,能减少训练迭代次数、加快训练速度,还可降低错误率和损失。它只重复dropout后的操作,不显著增加计算成本,推理时可修剪网络消除冗余。
本文介绍了multi-sample dropout技术,它是dropout技术的变形。该技术创建多个dropout样本并平均损失,能减少训练迭代次数、加快训练速度,还可降低错误率和损失。它只重复dropout后的操作,不显著增加计算成本,推理时可修剪网络消除冗余。
本文阐述的也是一种 dropout 技术的变形——multi-sample dropout。传统 dropout 在每轮训练时会从输入中随机选择一组样本(称之为 dropout 样本),而 multi-sample dropout 会创建多个 dropout 样本,然后平均所有样本的损失,从而得到最终的损失。这种方法只要在 dropout 层后复制部分训练网络,并在这些复制的全连接层之间共享权重就可以了,无需新运算符。
通过综合 M 个 dropout 样本的损失来更新网络参数,使得最终损失比任何一个 dropout 样本的损失都低。这样做的效果类似于对一个 minibatch 中的每个输入重复训练 M 次。因此,它大大减少了训练迭代次数。
实验结果表明,在基于 ImageNet、CIFAR-10、CIFAR-100 和 SVHN 数据集的图像分类任务中,使用 multi-sample dropout 可以大大减少训练迭代次数,从而大幅加快训练速度。因为大部分运算发生在 dropout 层之前的卷积层中,Multi-sample dropout 并不会重复这些计算,所以对每次迭代的计算成本影响不大。实验表明,multi-sample dropout 还可以降低训练集和验证集的错误率和损失。
Multi-Sample Dropout
图 1 是一个简单的 multi-sample dropout 实例,这个实例使用了 2 个 dropout 样本。该实例中只使用了现有的深度学习框架和常见的操作符。如图所示,每个 dropout 样本都复制了原网络中 dropout 层和 dropout 后的几层,图中实例复制了「dropout」、「fully connected」和「softmax + loss func」层。在 dropout 层中,每个 dropout 样本使用不同的掩码来使其神经元子集不同,但复制的全连接层之间会共享参数(即连接权重),然后利用相同的损失函数,如交叉熵,计算每个 dropout 样本的损失,并对所有 dropout 样本的损失值进行平均,就可以得到最终的损失值。该方法以最后的损失值作为优化训练的目标函数,以最后一个全连接层输出中的最大值的类标签作为预测标签。当 dropout 应用于网络尾段时,由于重复操作而增加的训练时间并不多。值得注意的是,multi-sample dropout 中 dropout 样本的数量可以是任意的,而图 1 中展示了有两个 dropout 样本的实例。
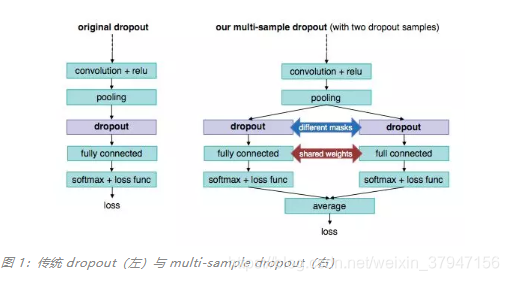
神经元在推理过程中是不会被忽略的。只计算一个 dropout 样本的损失是因为 dropout 样本在推理时是一样的,这样做可以对网络进行修剪以消除冗余计算。要注意的是,在推理时使用所有的 dropout 样本并不会严重影响预测性能,只是稍微增加了推理时间的计算成本。
为什么 Multi-Sample Dropout 可以加速训练
直观来说,带有 M 个 dropout 样本的 multi-sample dropout 的效果类似于通过复制 minibatch 中每个样本 M 次来将这个 minibatch 扩大 M 倍。例如,如果一个 minibatch 由两个数据样本(A, B)组成,使用有 2 个 dropout 样本的 multi-sample dropout 就如同使用传统 dropout 加一个由(A, A, B, B)组成的 minibatch 一样。其中 dropout 对 minibatch 中的每个样本应用不同的掩码。通过复制样本来增大 minibatch 使得计算时间增加了近 M 倍,这也使得这种方式并没有多少实际意义。相比之下,multi-sample dropout 只重复了 dropout 后的操作,所以在不显著增加计算成本的情况下也可以获得相似的收益。由于激活函数的非线性,传统方法(增大版 minibatch 与传统 dropout 的组合)和 multi-sample dropout 可能不会给出完全相同的结果。然而,如实验结果所示,迭代次数的减少还是显示出了 multi-sample dropout 的加速效果。
为什么 multi-sample dropout 很高效
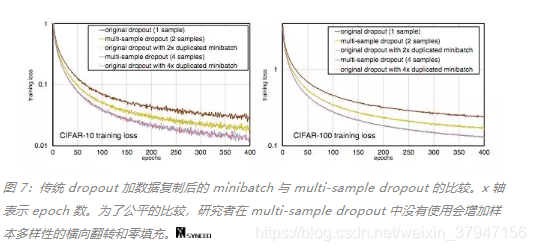
如前所述,dropout 样本数为 M 的 multi-sample dropout 性能类似于通过复制 minibatch 中的每个样本 M 次来将 minibatch 的大小扩大 M 倍。这也是 multi-sample dropout 可以加速训练的主要原因。图 7 可以说明这一点。
论文链接:https://arxiv.org/pdf/1905.09788.pdf

















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









