







SVM简介:
支持向量机(SVM,也称为支持向量网络),是机器学习中获得关注最多的算法没有之一。它源于统计学习理论, 是我们除了集成算法之外,接触的第一个强学习器。
从算法的功能来看:SVM囊括了分类和聚类功能:

从分类效力来讲:SVM在无论线性还是非线性分类中,都是明星般的存在,如此全能,宛如机器学习界的刘德华。
从学术的角度来看:SVM是最接近深度学习的机器学习算法。
这几个缩写的含义及关系,以免混淆:
- SVM=Support Vector Machine 是支持向量
- SVC=Support Vector Classification 就是支持向量机用于分类
- SVR=Support Vector Regression 就是支持向量机用于回归分析
SVM模型的几种:
- svm.LinearSVC Linear Support Vector Classification.
- svm.LinearSVR Linear Support Vector Regression.
- svm.NuSVC Nu-Support Vector Classification.
- svm.NuSVR Nu Support Vector Regression.
- svm.OneClassSVM Unsupervised Outlier Detection.
- svm.SVC C-Support Vector Classification.
- svm.SVR Epsilon-Support Vector Regression.
支持向量机分类器是如何工作的:
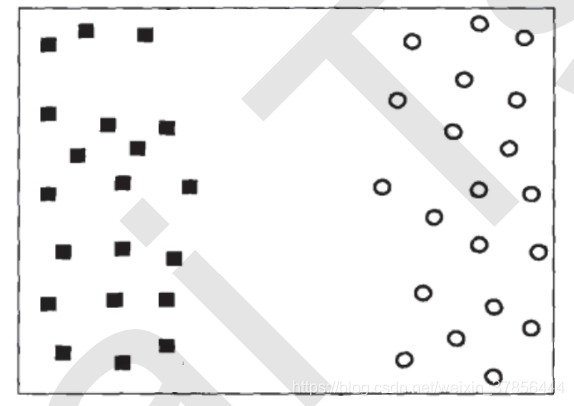
支持向量机所作的事情其实非常容易理解。先来看看下面这一组数据的分布,这是一组两种标签的数据,两种标签分别由圆和方块代表。支持向量机的分类方法,是在这组分布中找出一个超平面作为决策边界,使模型在数据上的分类误差尽量接近于小,尤其是在未知数据集上的分类误差(泛化误差)尽量小。
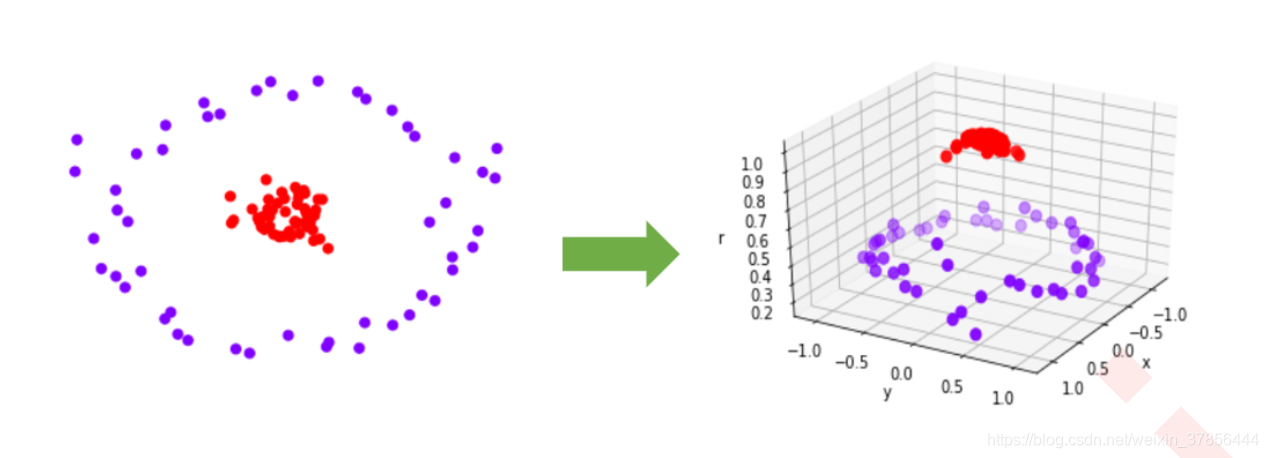
另一种情况:升维。
| 关键概念:超平面 |
| 在几何中,超平面是一个空间的子空间,它是维度比所在空间小一维的空间。 如果数据空间本身是三维的, 则其超平面是二维平面,而如果数据空间本身是二维的,则其超平面是一维的直线。 在二分类问题中,如果一个超平面能够将数据划分为两个集合,其中每个集合中包含单独的一个类别,我们就说这个超平面是数据的“决策边界”。 |
选用不同的核函数,就可以解决不同数据分布下的寻找超平面问题。在sklearn的SVC中,这个功能由参数“kernel”和一系列与核函数相关的参数来进行控制。我们就在乳腺癌数据集上,来探索一下各种核函数的功能和选择。
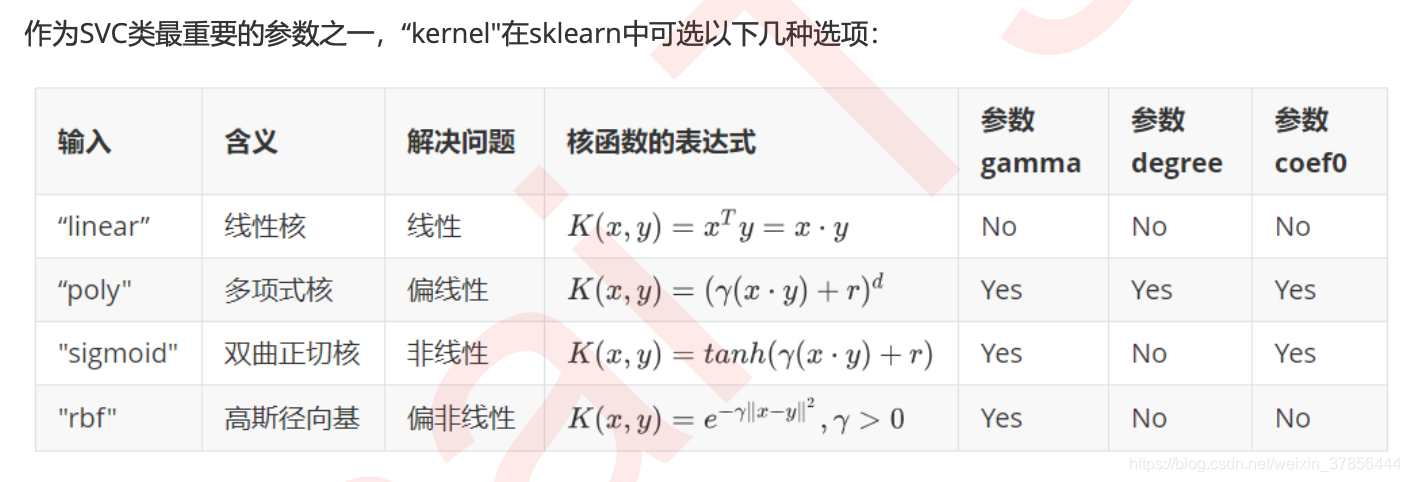
除了选项"linear"之外,其他核函数都可以处理非线性问题。
多项式核函数有次数d,当d为1的时候它就是在处理线性问题,当d为更高次项的时候它就是在处理非线性问题。
那究竟什么时候选择哪一个核函数呢?
答:
线性核函数和多项式核函数在非线性数据上表现会浮动,如果数据相对线性可分,则表现不错;如果是像环形数据那样彻底不可分的,则表现糟糕。在线性数据集上,线性核函数和多项式核函数即便有扰动项也可以表现不错,可见多项式核函数是虽然也可以处理非线性情况,但更偏向于线性的功能。
Sigmoid核函数就比较尴尬了,它在非线性数据上强于两个线性核函数&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









