



作为一名算法工程师 and 灌水科研工作者,
我过去几年每年的论文阅读量都在100篇以上。
以至于,我的Zotero里面现在积累了2000篇以上的paper。因为一直做的医疗AI算法,所以医学AI类的文章占了将近一半的比例。
过去,我经常跟我的组员、跟机器学习交流群里的群友说,想要快速切入到一个不太熟悉的学术方向和技术领域时,最好的方法是找一篇该领域最新的综述来精读。这样你就会对这个领域的研究进展有一个概括性的roadmap。
然后再有针对性的做文献调研,即使一个非常细分的研究方向,多则大几十篇文献,少则十几篇文献,阅读和总结都非常费时费力(用我们写论文常用的话来形容就是time-consuming and labor-intensive)。一次文献调研工作通常会持续1-2周时间才能形成最终的PPT调研报告。
但今时不同往日了。
自从年初OpenAI发布了Deep Research(深度研究)功能之后,我在文献调研上花的时间可能只有之前的1/5。对于新的技术方向和学术课题,我只需要分别在ChatGPT和Gemini中描述好调研需求,半个小时之内,一篇内容详尽、数据最新的调研报告就会呈现在我的眼前。
这个东西,真的可以算是科研工作者和调研爱好者的神兵利器。
到了2025年7月,Deep Research功能已经是各家大模型产品的标配了,一定程度上也改变了传统搜索产品的逻辑。试想一下,你能忍受谷歌半个小时给你搜索结果?但现在,Deep Research在那里kuku一顿查,半小时给你调研报告,你还觉得这速度老快了。
截止到2025年7月,部分有Deep Research功能的厂商与模型如下。这个赛道目前来看可谓是千帆竞渡。
厂商 | 模型产品 | Deep Research功能发布时间 |
OpenAI | ChatGPT | 2025.2 |
Perplexity.ai | Perplexity | 2025.2 |
Gemini | 2024.12 | |
Anthropic | Claude | 2025.6 |
月之暗面 | Kimi | 2025.6 |
字节跳动 | 豆包 | 2025.6 |
百度 | 文心一言 | 2025.2 |
阿里 | 通义千问 | 2025.5 |
Deep Research是依托于Deep Search(深度搜索)功能的,本质上是一个迭代搜索和信息整合的Agent。Deep Search迭代地进行搜索、阅读和推理,三个步骤持续循环以提高信息收集的准确性和完整性。
而Deep Research则是在Deep Search基础上,用一个结构化的报告框架,比如目录、引言、主题1、主题2等来逐个应用Deep Search进行信息搜索和内容整合。所以,Deep Research的研究报告通常有更好的内容组织、连贯性和可读性。
各厂商虽然都没有公开详细的技术细节,但多少能窥见一些蛛丝马迹。比如OpenAI Deep Research是通过强化学习在网页浏览+工具使用任务上进行了训练,使其学会自主规划检索策略、解析复杂网页内容,并根据中间过程中的信息发现来动态调整搜索方向。在执行过程中,Deep Research可以调用ChatGPT内置的网络浏览器和Python工具。前者用于实时检索和阅读网页,后者用于数据处理和分析。
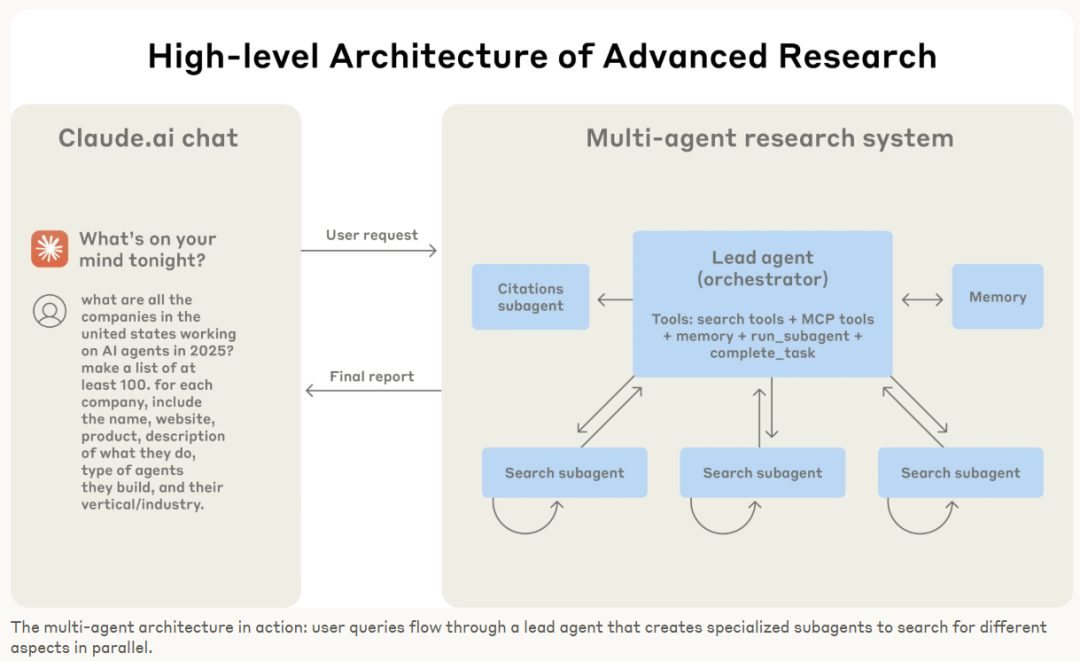
再比如Claude的Deep Research功能是基于Multi-Agent(多智能体)来实现的。Claude的多智能体研究系统采用主Agent+子Agent的分层架构,主Agent负责理解用户问题、规划解决方案和协调调度。每个子Agent则带有特定工具和目标,如负责网页搜索、负责资料引用等。
Deep Research的使用也非常简单。描述好你的调研需求,然后系统一般会有个任务的边界需要你确定,目的是使得调研方向、范围和内容更加聚焦。用户确认之后,Deep Research就开始干活了。

比如我作为一名爬行动物爱好者,让Gemini 2.5 Pro深度调研一下浙江省的毒蛇种类:
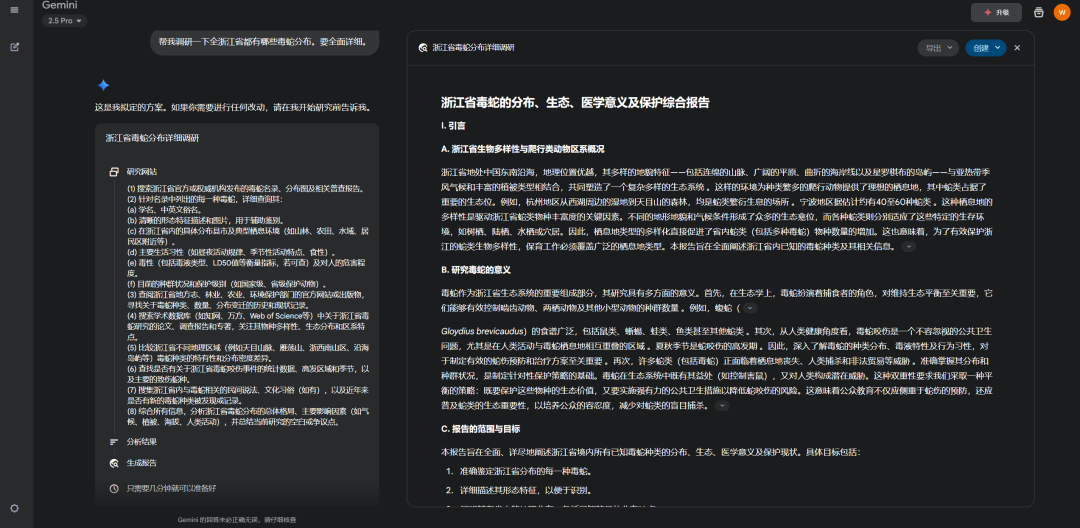
而且,报告也可以以PDF格式导出(Gemini),或者用可视化报告的方式呈现(Kimi)。
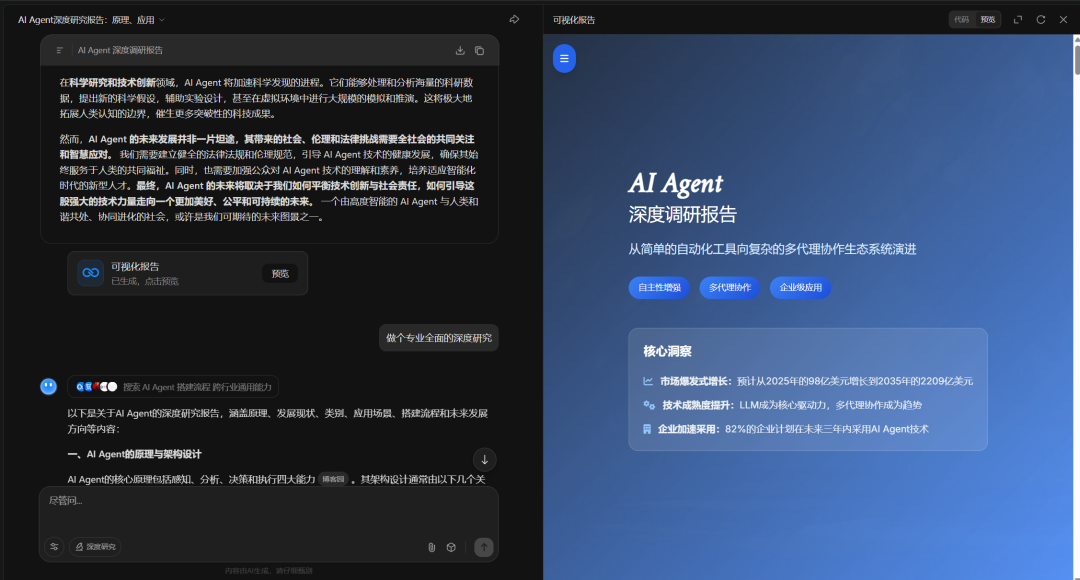
我数了一下今年2月份以来,我在各个平台使用Deep Research生成的报告数,足足有113篇,除了周末,基本上每天都在用AI做深度研究和调研,是名副其实的文献综述和技术调研爱好者。
有时候想想,现在的学生真幸福,赶上了AI爆发的好时代,各种信息、AI工具随手就能获得,我读研的时候要是有Deep Research这种科研大杀器,高低也能多出两篇学术成果。
虽然很好用,但是也必须提醒一下大家,Deep Research的缺点。特别是在对一个学术方向做详尽的paper review的时候,用Deep Research调研很多时候是不全面的。主要原因是它不能访问闭源的期刊文献,比如Springer、Elsevier、IEEE等学术出版商旗下的各类期刊论文。
但瑕不掩瑜,任何情况下,无论是学术调研、行业调研,还是查行业数据,甚至是用来直接翻译PDF文档,Deep Research都是每个知识工作者的必备Agent。
所以,调研爱好者们,Deep Research赶紧用起来!
后记:机器学习实验室公众号近期在进行内容重组,会更加聚焦AIGC和AGI相关学术、技术与应用。会加大原创内容产出,感谢各位读者的支持。
八年AI算法老兵,目前正在全面拥抱大模型和AIGC。感兴趣的小伙伴可以加我微信(louwill_)交个朋友。
>/ 作者:louwill



















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









