



进入2025年之后,腾讯的混元团队放出了多个开源大招。
先是在年初发布了Hunyuan 3D 2.0模型,一款致力于生成高分辨率的大规模3D生成系统。
然后在3月初又开源了自家的AI视频生成模型HunyuanVideo。
最近一次就是7月底发布的Hunyuan 3D世界生成模型HunyuanWorld 1.0。

可以看到,混元团队在3D生成领域可谓频频发力,这在玩家众多的AI视频生成赛道里面算是独一份了。
3D建模本身一项门槛极高的技术,复杂的拓扑结构设计和优化、需要掌握多种建模软件,如果涉及到更深入的计算机图形学问题,则对数学和算法能力有更高的要求。
但混元3D生成系列模型开源之后,在混元3D生成平台,用户仅需要提示词描述和参考图像,即可生成3D内容。在提升3D内容生成质量和效率的同时,也大幅度降低了3D内容创作的技术门槛。
所以,我们今天主要聚焦混元的两个3D模型:Hunyuan 3D 2.0和HunyuanWorld 1.0模型。
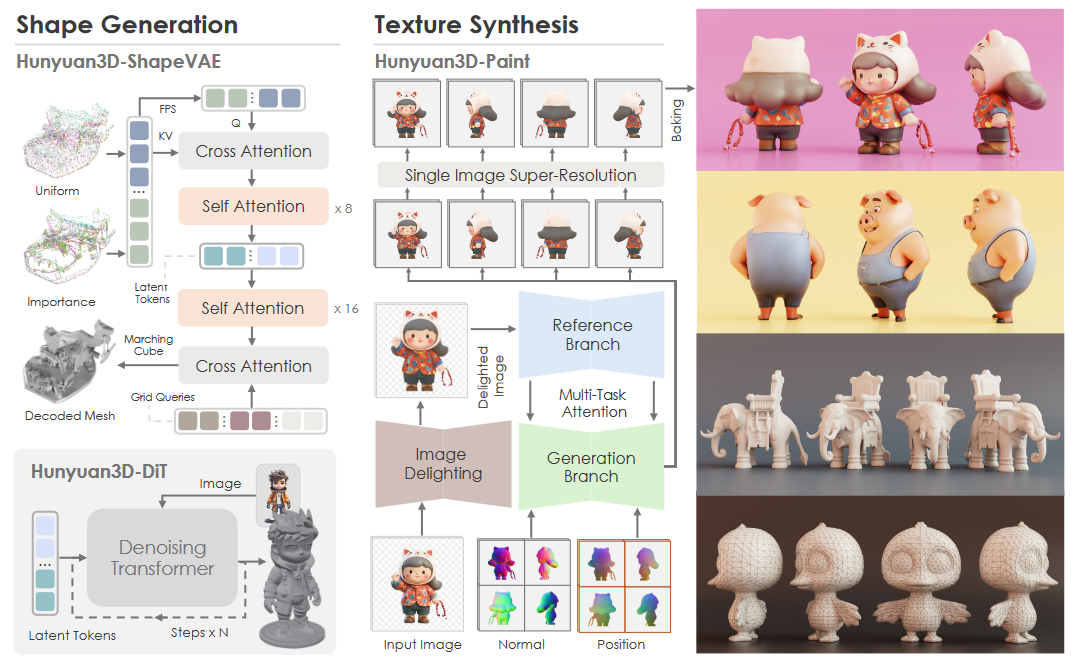
Hunyuan 3D 2.0模型是一个先进的大规模3D合成系统,包含两大基础组件:Hunyuan3D-DiT(大规模形状生成模型)和Hunyuan3D-Paint(大规模纹理合成模型)。
Hunyuan3D-DiT是基于可扩展流基(flow-based)扩散Transformer构建,旨在根据给定图像生成精确几何形状。它利用Hunyuan3D-ShapeVAE将3D形状压缩为连续潜在token,并采用网格表面重要性采样来捕获精细细节。Hunyuan3D-Paint则利用强大的几何和扩散先验,通过新颖的网格条件多视图生成管道和图像去光照模块,为生成或手工网格生成高分辨率、生动的纹理贴图,确保多视图生成的一致性。Hunyuan 3D 2.0模型如下图所示。
Hunyuan3D 2.0模型完整细节可阅读论文:
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
链接:https://arxiv.org/pdf/2501.12202
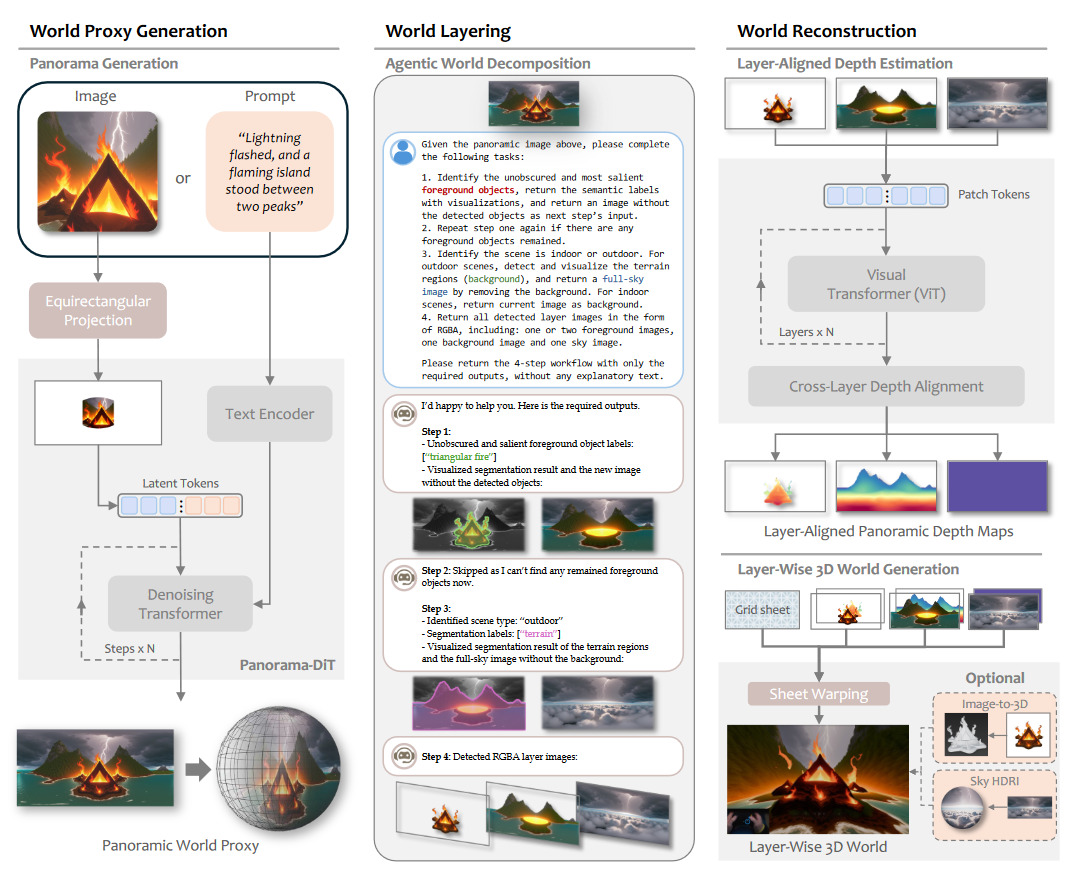
而HunyuanWorld 1.0是一个创新框架,致力于从文本或图像条件生成沉浸式、可探索和可交互的3D世界。
HunyuanWorld 1.0的核心是语义分层3D网格表示,利用全景图像作为360°世界代理进行语义感知世界分解和重建。该框架包括:全景世界图像生成(基于DiT的Panorama-DiT模型)作为世界代理;智能世界分层,将复杂场景分解为天空、背景和多个对象层以实现对象解耦和交互;分层3D世界重建,估计对齐的全景深度图并生成网格;以及通过Voyager模型实现长距离世界探索,提供世界一致的视频扩散和世界缓存机制。HunyuanWorld 1.0模型架构如下图所示。
HunyuanWorld 1.0模型完整细节可阅读论文:
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
链接:https://arxiv.org/pdf/2507.21809
下面直接进入混元3D生成平台,看一下如何使用。直接进入混元3D生成平台官网:
https://3d.hunyuan.tencent.com/
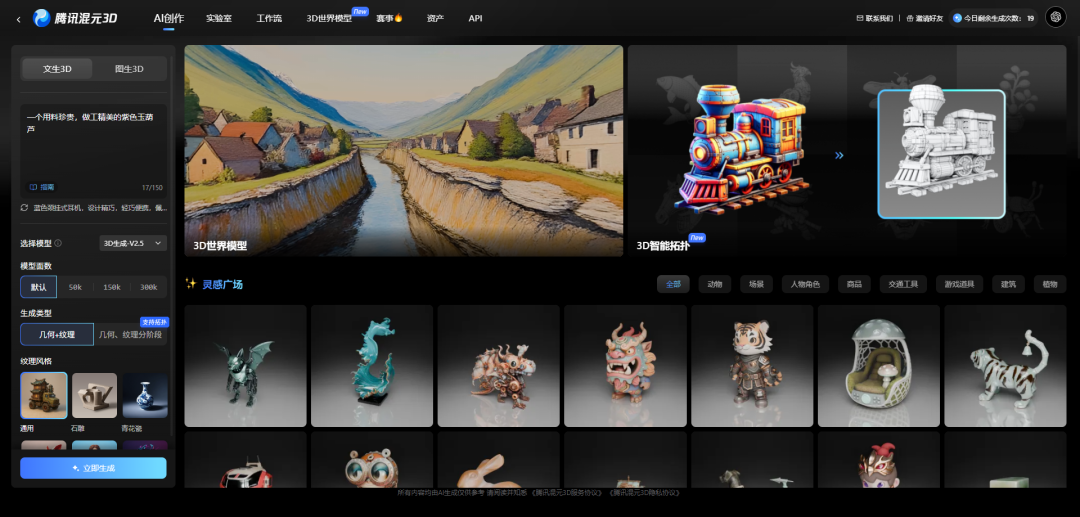
平台菜单栏包括AI创作、实验室、工作流、3D世界模型等主要创作页面。AI创作即基于Hunyuan3D 2.0模型的文生3D和图生3D工具页面。比如一些官方生成案例:



我们也可以自己做一些测试:

(文生3D:紫色玉葫芦)
(文生3D:常山赵子龙)

(图生3D:紫色牡丹花)
我作为医疗行业算法从业者,经常会有医学图像的三维重建问题。现在,我可以用单张3D医学影像,基于混元3D进行三维重建。比如,我基于一张2D的脑部血管造影图像(DSA)来直接进行三维血管重建:
输入参考图:
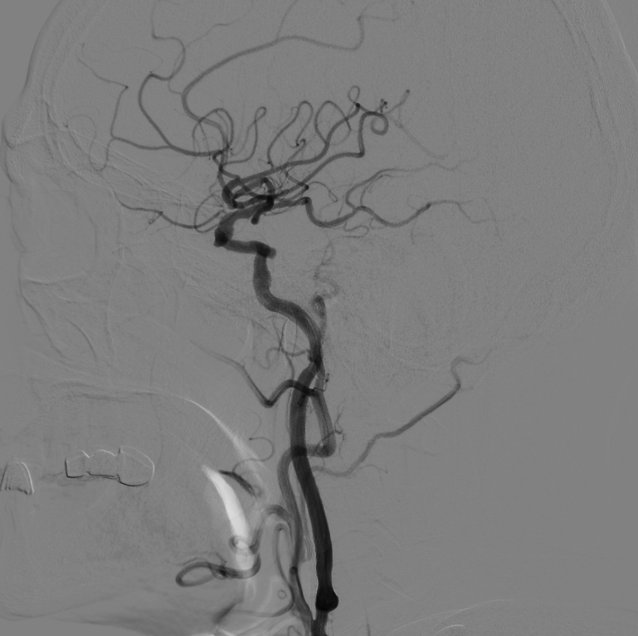
Hunyuan 3D 2.0模型三维重建效果:

并且生成的3D模型可以直接以GLB/STL/OBJ等3D建模格式下载使用。所以整体来看,效果还是非常好的,可以直接干翻我们医疗垂类的一些三维重建算法了。混元3D生成每天有20次生成机会,腾讯还是非常慷慨的。
混元3D平台另一大功能就是3D世界生成建模,即基于前述的HunyuanWorld 1.0模型的应用。将菜单栏切换到3D世界模型即可,包括360全景图和漫游场景两个选项。
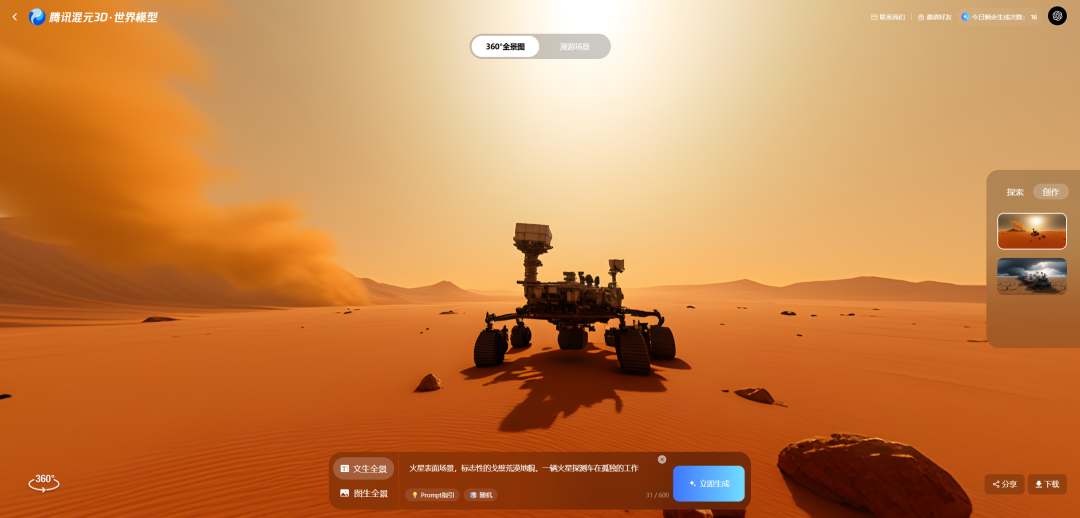
比如,我用文生全景生成一个火星地表全景效果:
除了上述两大核心功能之外,混元还提供了实验室和工作流功能。实验室可以看作是一个基于上述两大模型的3D应用平台,用户可以在上面完成一些有趣的3D生成创作。
工作流则是将ComfyUI集成到了混元平台,在平台内即可使用ComfyUI工作流来进行3D生成创作,比如实验室文生道具工作流:
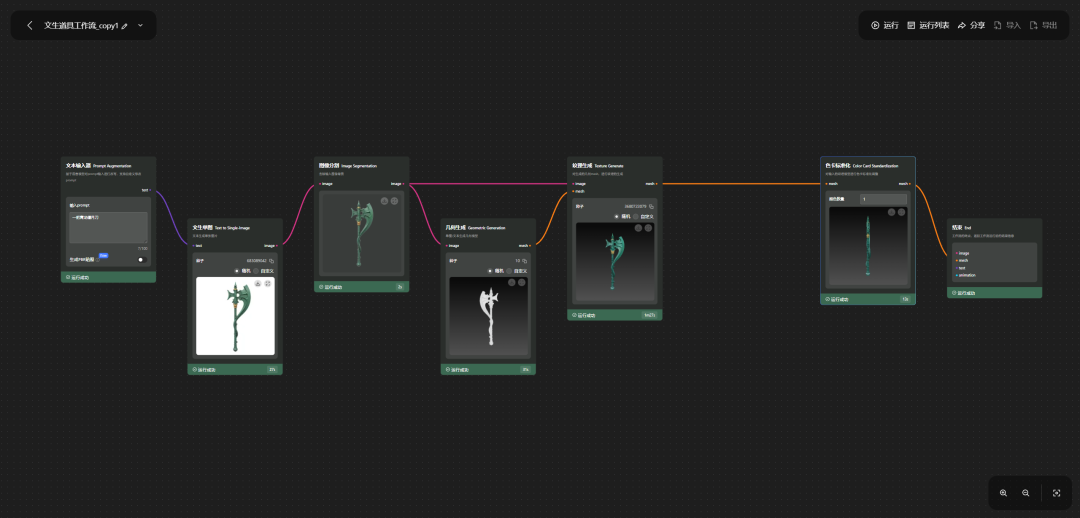
跟大多数AIGC平台一样,我们每一次生成的3D模型,都会作为数字资产保存在混元的资产栏目下。官方还提供了3D生成的API,方便开发者进行调用,不过价格感觉有点小贵。
最后,不得不感慨一下,当下的国产AI,确实越来越全面,是全方位的在变强。
感谢您阅读我的文章。我是louwill,八年AI算法老兵,目前正在全面拥抱大模型和AIGC。感兴趣的小伙伴可以加我微信(louwill_)交个朋友。

>/ 作者:louwill

















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









