




- PPO解决了PG哪些问题,怎么解决的:::策略梯度(PG)优化之TRPO/PPO
一 为什么提出PPO
训练AC时需要与环境交互来采样很多轨迹,然后利用这些轨迹训练Actor和Critic;然而,这一过程是十分费时的,这可能导致我们无法高效的采集大量数据,进而充分的训练模型。因此,我们考虑是否能将已有的轨迹数据复用以提高训练效率。
这一思路将我们指向了off-policy RL的道路。具体而言,我们希望有两个策略网络π1和π2,其中π1不断与环境交互收集数据,这些数据可以重复使用以训练π2的参数。
有了这些铺垫,我们终于得到了一个可以高效训练的RL算法:Proximal Policy Optimization(PPO),近期获得很大关注的InstructGPT、ChatGPT便在底层使用了PPO进行强化学习。
PPO是一种对上述Off-policy RL目标的实现,分析其优化目标不难发现,它首先最大化原始优化目标A*π2/π1,其次又防止π2/π1偏离1太多,即控制了两个分布的差距。
PPO(Proximal Policy Optimization)是OpenAI在2017提出的一种强化学习算法,是基于策略优化的算法,用于训练能够最大化累积奖励的智能体。PPO算法通过在每次更新时限制新策略与旧策略之间的差异,从而更稳定地更新策略参数。这种方法有助于避免训练过程中出现的不稳定性和剧烈波动,使得算法更容易收敛并学习到更好的策略。
即:PPO是RLHF实施用到的具体算法
二 训练步骤
2.1 RLHF流程
- 收集人类反馈,人工标注数据
以summary任务为例,随机从数据集中抽取问题,对于每个问题,生成多个不同的回答
人工标注,判断哪个回答更符合人类期望,给出排名- 训练奖励模型(reward model, RM)
对多个排序结果,两两组合,形成多个训练数据对
奖励模型接受一对输入输出数据,给出评价:回答质量分数 (标量奖励,数值上表示人的偏好)
调节参数使得高质量回答的打分比低质量的打分要高。- 采用PPO强化学习,优化策略(Proximal Policy Optimization,近端策略优化)
从数据集中抽取问题,使用PPO模型(包括ref model、actor model)生成回答(即不需要人工标注),并利用第二阶段训练好的奖励模型打分
把奖励分数依次传递,由此产生策略梯度,通过强化学习的方式更新PPO模型参数,训练目标是使得生成的文本要在奖励模型上获得尽可能高的得分。

2.2 PPO算法流程
- step1:prompt 输入 actor model 得到 response
- step2(重要性采样): prompt + response 分别输入到 actor_model 和 reference model 得到 log_probs、ref_log_probs、reward_score、values,这部分的数据可以重复利用。
- step3 计算 critic_loss、actor_loss,更新 actor_model。
大致上,ppo 主要就这个三个步骤。
整个流程下来,很繁琐,难训练,所以目前主流大模型很少使用原始的这套 RLHF 流程,更多使用 dpo 算法,而且 RLHF 的数据有限,很难对所有的 response 有一个公平的 reward

三 四个模型
- Actor model、Reference model: 开始的时候这两个模型是一样的,用途是一样的。
- Critic model、Reward model: 开始的时候这两个模型是一样的,但是用途是不一样的,
一个是用来产生 critic value,一个是用来产生 reward 的,虽然结构是一样的。
Actor 和 critic model 会随着 ppo 训练更新
而Reward/Reference Model是参数冻结的。
3.1 actor模型
如上,原始的大模型,以及需要被训练的大模型
参数会被一直更新
输入query
输出response
actor_loss 的核心是重要性采样
3.2 ref模型
如上,和actor同结构和大小,可以用actor初始化,或者上一轮actor参数初始化
输入query + response
输出logits
3.3 reward模型
模型结构上,model的最后一层last hidden state作为输入,输出为1维,得到value值。这样做可以帮助模型更好地学习序列的价值函数
输入query + response
reward值
Reward Model:奖励模型,它的作用是计算==即时收益 ==

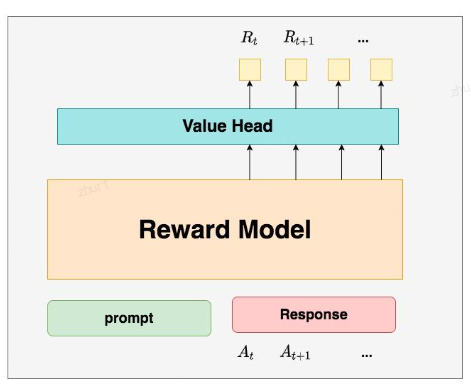
为什么Critic模型要参与训练,而同样是和收益相关的Reward模型的参数就可以冻结呢?
这是因为,Reward模型是站在上帝视角的。这个上帝视角有两层含义:
第一点,Reward模型是经过和“估算收益”相关的训练的,因此在RLHF阶段它可以直接被当作一个能产生客观值的模型。
第二点,Reward模型代表的含义就是“即时收益”,你的token At 已经产生,因此即时收益自然可以立刻算出。
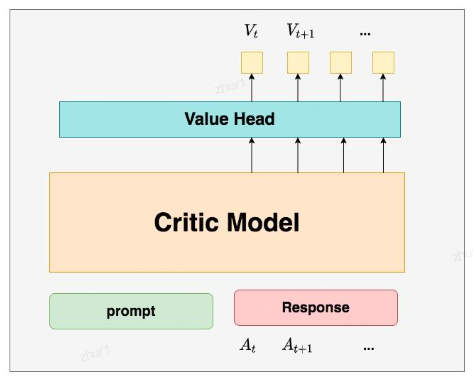
3.4 critic模型 - critic/value model
参数会被一直更新
输入query + response
critic值
Critic Model:评论家模型,它的作用是预估==总收益 ==
在forward传播时,reward model是在句子级别上进行操作,而critic model则是在token级别上进行操作。这种设计使得模型能够更好地捕捉序列中的细节信息。
模型结构与reward一致,critic参数可以由reward model参数来初始化。这样做的目的是为了方便模型参数的共享和初始化。

为什么要单独训练一个Critic模型用于预测收益呢?
这是因为,当我们在前文讨论总收益 Vt(即时 + 未来)时,我们是站在上帝视角的,也就是这个
就是客观存在的、真正的总收益。但是我们在训练模型时,就没有这个上帝视角加成了,也就是在
t 时刻,我们给不出客观存在的总收益 Vt ,我们只能训练一个模型去预测它。
所以总结来说,在RLHF中,我们不仅要训练模型生成符合人类喜好的内容的能力(Actor),也要提升模型对人类喜好量化判断的能力(Critic)。这就是Critic模型存在的意义。我们来看看它的大致架构:
Reward/Critic模型和Actor模型的架构是很相似的(毕竟输入都一样),同时,它在最后一层增加了一个Value Head层,该层是个简单的线形层,用于将原始输出结果映射成单一的 Vt 值。
在图中, Vt表示Critic模型对 t 时刻及未来(response完成)的收益预估。
Rt, Vt 同时存在的意义
那么哪一个结果更靠近上帝视角给出的客观值呢?
当然是结果2,因为结果1全靠预测,而结果2中的 Rt 是事实数据。
我们知道Critic模型也是参与参数更新的,我们可以用MSE(上帝视角的客观收益-Critic模型预测的收益)来衡量它的loss。但是上帝视角的客观收益我们是不知道的,只能用已知事实数据去逼近它,所以我们就用来做近似。这就是 Rt, Vt 同时存在的意义
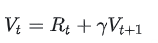

四 loss计算和优化
计算优势函数,指导策略更新。
通过剪切目标函数约束策略变化,更新Actor和Critic参数。
- 剪切机制:剪裁新旧策略比率在[1-ε, 1+ε],防止过度优化
- KL散度:衡量新旧策略差异,确保渐进式改进。
实践中:
Critic Model的设计和初始化方式也有很多种
例如和Actor共享部分参数、从RW阶段的Reward Model初始化而来等等。
我们讲解时,和deepspeed-chat的实现保持一致:从RW阶段的Reward Model初始化而来。
如上,共享时:
Critic Model 和 Actor Model 具有共享的底层编码器[底层大模型一样],比如状态特征提取层。该共享编码器负责对输入的状态信息(如图像、文本等高维特征数据)进行处理和特征提取,将其转化为公共的中间表征,为后续两个模型的不同任务输出提供基础。
4.1 KL散度和优势函数
4.1.1 直观解释
Actor接收到当前上文 St ,产出token At ( P(At|St) )
Critic根据 St, At ,产出对总收益的预测 Vt
那么Actor loss可以设计为:
求和符号表示我们只考虑response部分所有token的loss,为了表达简便,我们先把这个求和符号略去(下文也是同理),也就是说

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4293
4293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









