






PPO
PPO(Proximal Policy Optimization)是基于策略优化的算法,用于训练能够最大化累积奖励的智能体。PPO算法通过在每次更新时限制新策略与旧策略之间的差异,从而更稳定地更新策略参数。
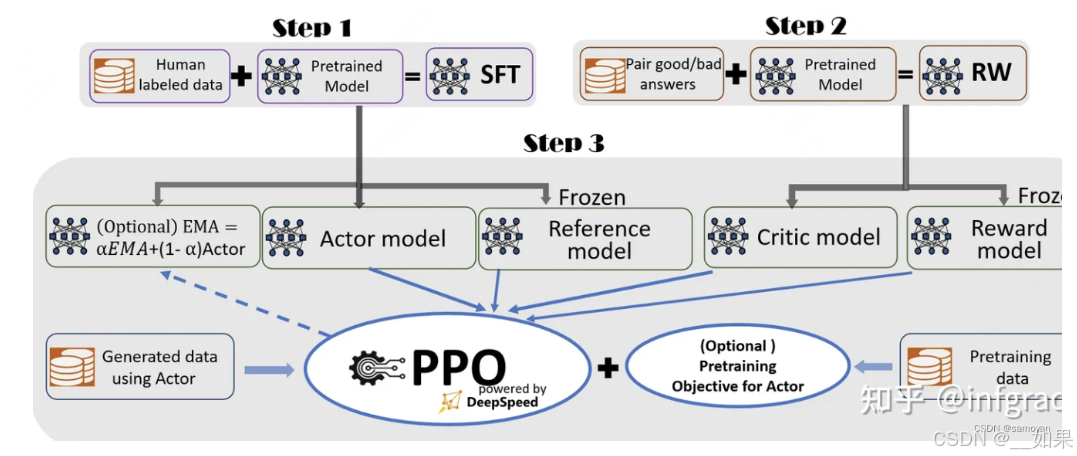
加载4个模型,2个推理,2个训练
Actor Model:演员模型,想要训练的目标语言模型
Critic Model:评论家模型,它的作用是预估总收益
Reward Model:奖励模型,它的作用是计算即时收益
Reference Model:参考模型,它的作用是在RLHF阶段给语言模型增加一些“约束”,防止语言模型训歪(朝不受控制的方向更新,效果可能越来越差)
其中:
Actor/Critic Model在RLHF阶段是需要训练的;而Reward/Reference Model是参数冻结的。
Critic/Reward/Reference Model共同组成了一个“奖励-loss”计算体系,我们综合它们的结果计算loss,用于更新Actor和Critic Model
DPO
DPO(Direct Preference Optimization)通过利用奖励函数与最优策略之间的映射关系,证明这个受限的奖励最大化问题可以通过单阶段的策略训练来精确优化,本质上是在人类偏好数据上解决一个分类问题。
只需要加载2个模型,其中一个推理,另外一个训练,直接在偏好数据上进行训练
DPO 假设参考分布 πref 能准确捕捉偏好数据分布,但在实际中,πref 和偏好分布常存在偏移,导致模型对分布外数据(OOD)表现异常
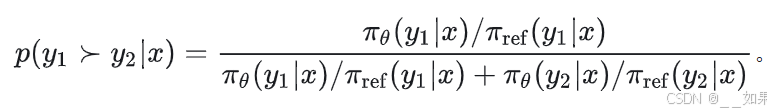
偏好数据常不覆盖整个分布,πref 的偏差会放大这种分布偏移,错误地提高 OOD 样本的概率
由于DPO的优化目标是最大化对比学习中的偏好数据的对数似然,因此在优化过程中,较短序列可能会因为相对较高的生成概率(相对于较长序列)而被偏好;可以在DPO的目标函数中加入长度惩罚项解决

















 6120
6120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









