




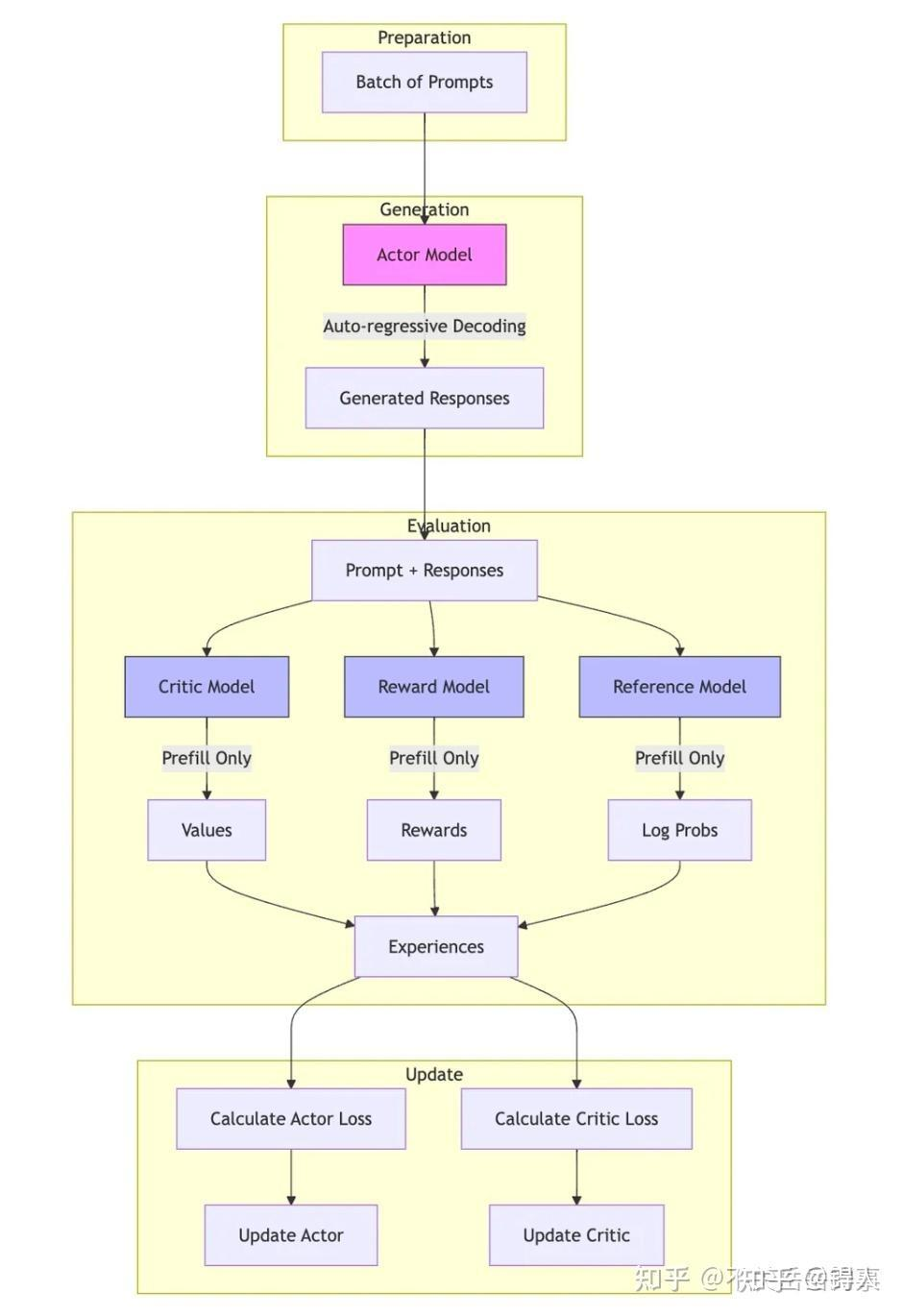
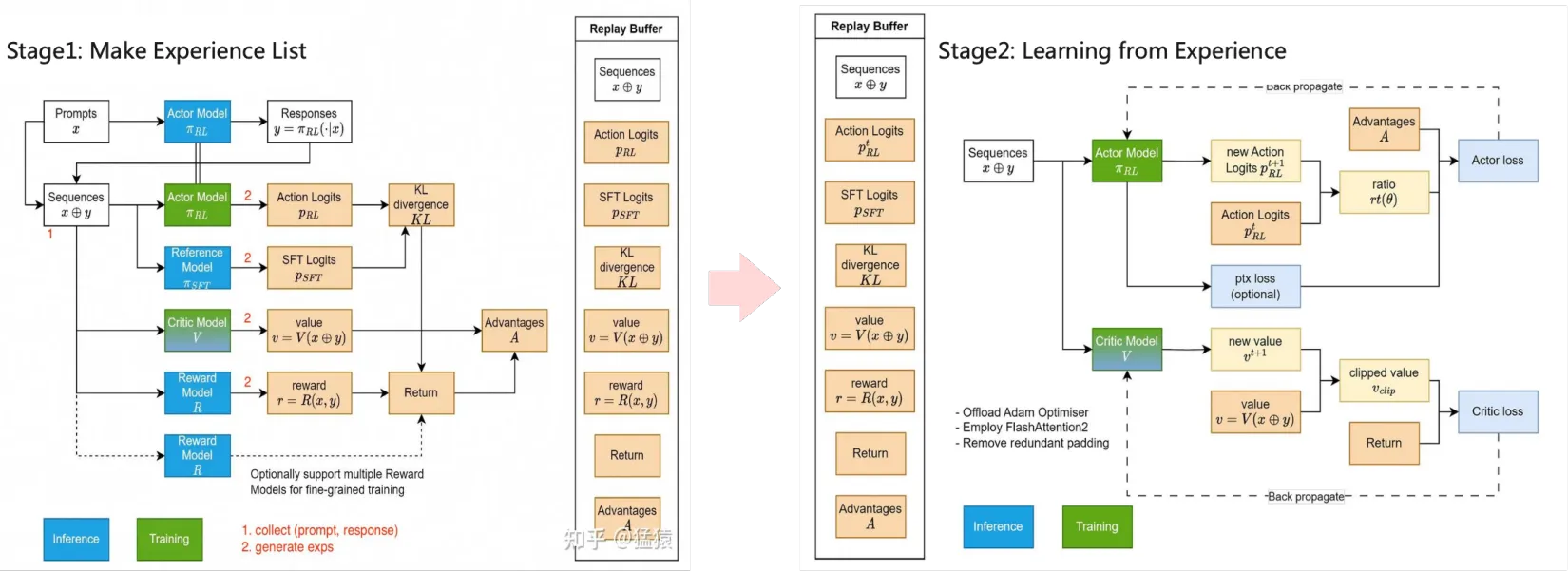
Episodes(片段)
在强化学习中,一个episode是指智能体(Agent)与环境(Environment)之间一次完整的交互序列。这个序列从智能体开始观察环境状态开始,然后根据其策略选择一个动作并执行,环境会给出新的状态和奖励,这个过程会一直重复,直到达到某种终止状态,比如游戏结束、任务完成或达到预定的步数。每个episode都是独立的,结束后会重置环境并开始新的episode。
例如,在一个简单的迷宫游戏中,一个episode可能包括智能体从起点开始,经过一系列的移动,最终达到终点的整个过程。
Rollouts(模拟轨迹)
Rollouts通常指的是在执行策略梯度或其他基于模拟的强化学习方法时,智能体在环境中进行的一系列模拟交互步骤。这些步骤用于收集数据,以评估或改进当前的策略。一个rollout可以包含一个或多个完整的episodes,或者只是一个episode的一部分(在实际应用中,通常一个rollout只包含一个episode的数据)。
在训练过程中,我们可能会执行多个rollouts来收集足够的数据,以便更新智能体的策略。每个rollout都会根据当前的策略生成一组新的交互数据(状态、动作、奖励等),这些数据随后用于计算梯度并更新策略。
总结
Episodes是智能体与环境之间一次完整的交互过程。
Rollouts是在训练过程中,智能体根据当前策略进行的一系列模拟交互步骤,用于收集数据和评估策略。一个rollout可以包含一个或多个episodes的数据。
verl参数
data.train_batch_size是一个大循环所采集的experience数据总量;
actor.ppo_mini_batch_size是每一次PPO actor更新时,所使用的数据量
而所有的micro_batch_size在默认设置中全都不起效!(因为当actor.use_dynamic_bsz为True时,会自动根据token量划分micro_batch)
因此同步调小data.train_batch_size和actor.ppo_mini_batch_size即可减少显存占用(同时保证PPO更新轮数不变)。
一:从run_deepseek7b_llm.sh干了什么
我们启动的是verl.trainer.main_ppo 这个python文件(main_ppo.py)。
然后main函数会启动run_ppo这个函数
从顶层看,干了以下几件事:
- 1.初始化ray的分布式环境:runtime_env.yaml;
- 2.启动TaskRunner这个类,让它在ray环境下运行;
ray是一个分布式框架,
常见的操作包括:
ray start(启动ray) ;ray status(显示ray的状态);ray stop (关闭ray)
在执行上面的脚本前,一定要先启动ray,然后再启动脚本。
TaskRunner这个类:
它干了四件事情:
- 启动几个worker:actor,rollout, critic等等;
我们关注的worker:(在fsdp_worker.py注册的ActorRolloutRefWorker)可以看出,actor,rollout,ref三个worker都是通过这个类注册的。actor:这是我们用来更新的模型,在魔改时,我们关注其方法。所以我们先不研究怎么初始化的,而是在意它支持哪些方法,可以看出,其对外接口是DataParallelPPOActor类的,actor怎么用只需关注其方法即可。
ref:这里是参考模型,ref模型一般是原始冻结的模型,用来提供KL loss所需的参考策略,当然魔改上可以在这里加上一个挂载模型,是KDRL paper的KD 实现。
rollout:这里一般只有generate sequence的支持,用来生成sample的sequence,一般也不会修改这里;
- 构造数据集;
构造验证的manager
主要通过load_reward_manager 构建,它们都是通过继承一个抽象的manager(https://github.com/volcengine/verl/blob/main/verl/workers/reward_manager/abstract.py)实现的;
from verl.utils.dataset.rl_dataset import RLHFDataset 可以看出,
dataset全部来自RLHFDataset,我们想要魔改,比如想让它支持adaptive thinking的格式,只需要自己写一个文件import进去,采用我们实现的RLHFDataset(在里面改apply_chat_template),然后在脚本传参即可。
- 启动奖励函数;
grpo采用的是batch.py 根据的实现,通过传入的compute_score实现。
但是,很多时候我们没有传入,为什么compute_score依旧实现了呢?因为有https://github.com/volcengine/verl/blob/main/verl/utils/reward_score/init.py#L19 的默认实现,这里我们是data_source 是openai/gsm8k,所以采用gsm8k的compute_score.
所以我们一方面可以通过data_source控制采用什么传入,另一方面,我们可以传入compute_score的位置实现。
- 启动训练RayPPOTrainer;
RayPPOTrainer:这里我们往往在意的是fit 函数
DataParallelPPOActor
dp_actor.py: 支持以下函数:(代码魔改最多位置之一)
- compute_log_prob 函数:
用来根据rollout 的sequence的inputs_id,attention_mask,position_ids,responses 生成其old_log_prob;- update_policy 函数:
用来更新策略,流程为:
计算old_log_prob
计算损失(采用loss_mode传入get_policy_loss_fn选择loss,policy_loss_fn计算loss)
需要计算kl(如果需要,采用kl_penalty)
反向传播;
loss 修改
任何时候,loss的实现都是修改的重灾区,所以我们要进一步查看get_policy_loss_fn的实现:
GAE = "gae"
GRPO = "grpo"
REINFORCE_PLUS_PLUS = "reinforce_plus_plus"
REINFORCE_PLUS_PLUS_BASELINE = "reinforce_plus_plus_baseline"
REMAX = "remax"
RLOO = "rloo"
OPO = "opo"
GRPO_PASSK = "grpo_passk"
GPG = "gpg"
RLOO_VECTORIZED = "rloo_vectorized"
这是目前支持的loss对应表。
比如我们让loss_mode=grpo,计算loss就会采用compute_grpo_outcome_advantage函数。
所以我们想魔改只需要在这里加一下我们起的名字,然后改一下compute advantage函数即可。
RayPPOTraine
这里我们往往在意的是fit 函数:
这个函数的经典做法是:
with marked_timer("reward", timing_raw, color="yellow"):
# compute reward model score
if self.use_rm and "rm_scores" not in batch.batch.keys():
reward_tensor = self.rm_wg.compute_rm_score(batch)
batch = batch.union(reward_tensor)
if self.config.reward_model.launch_reward_fn_async:
future_reward = compute_reward_async.remote(data=batch, reward_fn=self.reward_fn)
else:
reward_tensor, reward_extra_infos_dict = compute_reward(batch, self.reward_fn)
开始计算时间,采用worker去生成数据,然后union到batch里面;
一个step包括rollout(generate_sequences),计算score,计算old_log_prob,计算优势,(计算ref),然后调用update_actor(update_actor会调用update_policy),从而更新actor。
dapo的实现
dapo是四个trick组成的,我们先看一个例子的:clip-higher。
原本是clip-ratio,现在是clip-high,clip-low。
那我们注定要加入参数,clip_ratio_high , clip_ratio_low .
1.config加入参数:
想加入参数就要看一下config,我们找一下clip_ratio,因为我们和它用到的地方和传参是一致的,所以follow它就行了。
我们查找grep -r “clip_ratio” --include=“*yaml”
然后找到符合ppo 下面的,发现在https://github.com/volcengine/verl/blob/main/verl/trainer/config/actor/actor.yaml里面;
然后直接加上就行了,只加参数其实没必要写recipe了,但是default一定要保持原本的clip_ratio。
修改loss 计算代码:
我们去https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/core_algos.py 找到loss计算的地方,然后通过: clip_ratio = config.clip_ratio # Clipping parameter ε for standard PPO.
See https://arxiv.org/abs/1707.06347.
clip_ratio_low = config.clip_ratio_low if config.clip_ratio_low is not None else clip_ratio
clip_ratio_high = config.clip_ratio_high if config.clip_ratio_high is not None else clip_ratio
这样正常的分支会走 clip_ratio,我们只有传入clip_ratio_low ,clip_ratio_high才会走这两个地方。
修改传参的@dataclass类:
config.clip_ratio 这里,我们要找到相关的config,
因为上文提到传参数是在actor.yaml里面,所以我们去worker下找:https://github.com/volcengine/verl/blob/main/verl/workers/config/actor.py 发现其在:ActorConfig下,
就加入 clip_ratio_low: float = 0.2 clip_ratio_high: float = 0.2。
所以,加入新参数且可以兼容原本的逻辑的可以直接改源码,但是要注意一定要默认是原本的路径,Token-level Loss 同理,可以同样这样改。
然后是config 的xxpo_trainer.yaml 和 runtime_env.yaml文件:如果加入新参数,我们不想做兼容/无法做兼容,那就要用我们自己的main_xxpo.
这时,修改除了上述的加入参数处理,还要用我们的入口,那我们就也要改以下代码为:
@hydra.main(config_path="config", config_name="xxpo_trainer", version_base=None)
def main(config):
run_ppo(config)
这里就会索引recipe/config/xxpo_trainer.yaml,用它做传参的入口。
这里可以借鉴dapo 的dapo_trainer 文件:
hydra:
searchpath:
- file://verl/trainer/config
defaults:
- ppo_trainer
- _self_
data:
gen_batch_size: ${data.train_batch_size}
reward_model:
reward_manager: dapo
overlong_buffer:
enable: False # We try to avoid forgetting to set enable
len: 0
penalty_factor: 0.0
log: False
algorithm:
filter_groups:
_target_: verl.trainer.config.FilterGroupsConfig
enable: False # We try to avoid forgetting to set enable
metric: null # acc / score / seq_reward / seq_final_reward / ...
max_num_gen_batches: 0 # Non-positive values mean no upper limit
trainer:
project_name: verl-dapo
这里通过搜索/verl/trainer/config ,default设置ppo_trainer,再基础上加上刚加入的参数,可以在verl/下执行。
然后一般的runtime_env是用ppo下的,但是不方便的一点是要把工作区设置为verl/ 整个文件夹,而不是recipe的代码,这样模型和数据集之类的都要交ray上,ray最大限制是100MB,就会失败。
一个解决方式就是在runtime_env.yaml把不需要的文件全部excludes掉,但是这样会很麻烦。所以我一般修改的时候,都会把runtime_env.yaml 改成下面的形式,把pythonpath设置成path to verl,工作区设置为我recipe的代码。这样无论在哪里执行,都不会造成影响。
working_dir: ./
excludes: ["/.git/"]
env_vars:
TORCH_NCCL_AVOID_RECORD_STREAMS: "1"
CUDA_LAUNCH_BLOCKING: "0"
NVTE_DEBUG: "1"
NVTE_DEBUG_LEVEL: "2"
NVTE_FLASH_ATTN: "1"
RAY_DEBUG: "legacy"
NCCL_DEBUG: "WARN"
PYTHONPATH: "~path to verl"
VLLM_USE_V1: "1"
VERL_VLLM_DISTRIBUTED_BACKEND: "ray"

















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









