










一、环境安装
使用dockerfile文件构建docker镜像mmdet3d。
1、原dockerfile安装
docker build -t mmdet3d -f docker/Dockerfile .
注:
-
编译过程中若执行
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub遇见gpg failed,no public key问题,可能网络原因,多试几次。 -
若
apt-get install xxxfailed to fetch archive.ubuntu and security.ubuntu问题,替换源:
RUN sed -i 's#http://archive.ubuntu.com/#http://mirrors.tuna.tsinghua.edu.cn/#' /etc/apt/sources.list; -
替换pip源:
RUN pip install -i http://mirrors.aliyun.com/pypi/simple -U pip \ && pip config set global.index-url http://mirrors.aliyun.com/pypi/simple \ && pip config set install.trusted-host mirrors.aliyun.com
创建容器:
docker run --runtime=nvidia -v /home/data:/data -it -p 8888:22 --name mmlab mmdet3d:latest
至此 mmdetection3d环境创建成功。但是导入mmseg包时,报如下错误:

根据报错定位到/opt/conda/lib/python3.7/site-packages/mmseg/init.py文件,修改L10:MMCV_MAX = '1.6.0'
训练环境:

docker镜像现有问题:
- 无法在线可视化,追查原因,发现环境中未安装requirement/optional.txt中spconv、open3d、waymo-open-dataset-tf-2-1-0等包。
- 训练过程中,出现cuda error:

表示本机显卡gpu算力与docker环境的cuda版本不匹配。gpu算力高(RTX3060算力8.6),cuda版本低(cuda10.1)。
2、修改dockerfile
基于以上问题,修改dockerfile部分内容:
ARG PYTORCH="1.8.0"
ARG CUDA="11.1"
ARG CUDNN="8"
# 增加install requirement/optional.txt
RUN pip install --use-feature=2020-resolver -r requirements/optional.txt
注意:因镜像python版本为3.8,而可选包 waymo-open-dataset-tf-2-1-0仅支持python3.5、3.6、3.7,故没安装此数据包。
pip 追加参数--use-feature=2020-resolver 解决pip安装版本的依赖问题,ERROR: After October 2020 you may experience errors when installing or updating packages. This is because pip will change the way that it resolves dependency conflicts.
同时为了在使用容器时解决mmcv和mmseg冲突,安装mmcv==1.5.0,但是导入报如下错误:

于是仍使用原始版本号,在容器中手动修改/opt/conda/lib/python3.7/site-packages/mmseg/init.py文件L10为:MMCV_MAX = '1.6.0'。
docker中open3d可视化问题:
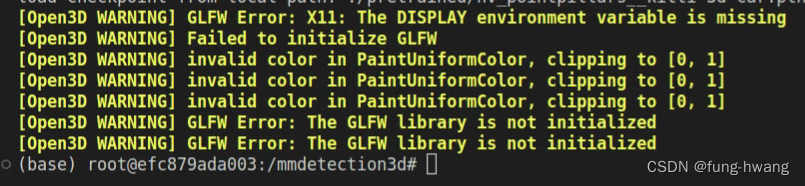
因 open3d显示要求在本地IDE上面,而笔者是在docker环境跑,故open3d没有能力显示。参考docker–open3d文档 解决GLFW Error。在终端执行以下命令,重新创建容器:
# Allow local X11 connections
xhost local:root
# Run Open3D viewer docker image with the NVIDIA GPU
docker run --runtime=nvidia -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY \
-v 宿主机数据:/data -v 宿主机代码:/code mmdet3d:latest
随后出现问题libGL error:

安装libnvidia-gl(其版本与驱动版本号有关)解决该问题:
sudo apt install libnvidia-gl-470
# 470 为nvidia版本驱动号
随后,重新设置x11连接。创建容器,增加参数:
-v /tmp/.X11-unix:/tmp/.X11-unix \
-e DISPLAY -e XAUTHORITY -e NVIDIA_DRIVER_CAPABILITIES=all \
以上即为如何在 Docker 容器中运行 GUI 应用程序。这里使用带有 X11 转发的 SSH 。核心部分为:
-v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY。
3、测试pcd_demo,并在线可视化验证环境是否可用
python demo/pcd_demo.py /data/kitti/kitti_000008.bin configs/pointpillars/hv_pointpillars_secfpn_6x8_160e_kitti-3d-car.py pretrained/hv_pointpillars_kitti-3d-car.pth --show

至此,mmdetection3d推理环境基于dockerfile搭建成功。
注:检测结果框为深度坐标系。
4、docker 使用GPU、X11转发显示图形界面
参考docker-gpu文档,安装nvidia-containers-runtime。
参考docker–open3d文档设置X11转发显示图形界面。
-e 参数,主要传递环境变量。如:
-e DISPLAY : 将 DISPLAY 环境变量从主机传递到容器中,告诉 GUI 程序将其输出发送到哪里。
-e XAUTHORITY :传递XAUTHORITY变量. .Xauthority 文件确保xclient与xserver之间的通信权限安全,从而支持linux vda使用X11显示功能进行交互式远程。
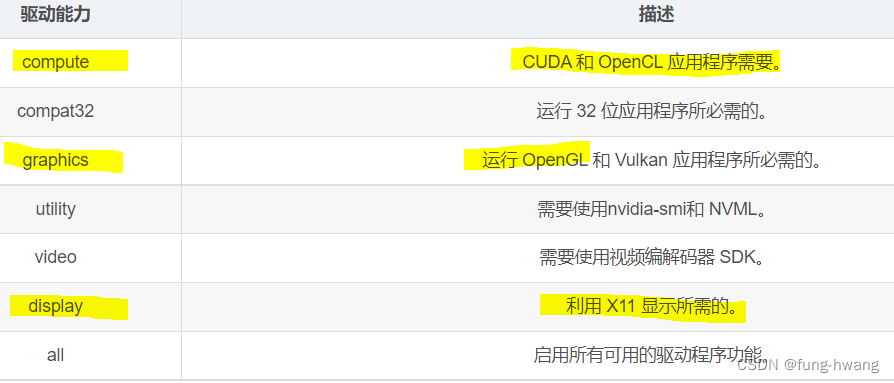
-e NVIDIA_DRIVER_CAPABILITIES=all :设置容器中允许使用显卡的某些能力。这里启用所有可用的驱动程序功能。如,宿主机的英伟达驱动在容器内作为utility存在,对容器提供计算支持(即cuda支持)等。具体有:
二、训练train
直接使用SA-SSD项目生成的KITTI数据集,train(其中需修改数据集关键字key) 单目标car类pointpillars 模型:
python tools/train.py configs/pointpillars/hv_pointpillars_secfpn_6x8_160e_kitti-3d-car.py
1、报错dataloader worker keyerror :

==> 粗暴式修改configs文件夹目录下对应数据文件中线程数为0:
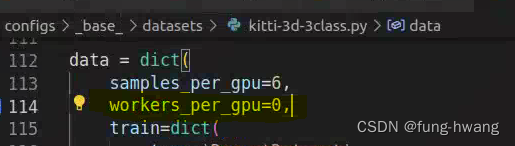
- 探索dataloader worker keyerror 其他解决方法? 后面该问题自动消失.
2、tensorboard 显示
训练日志:学习率、loss变化
tensorboard --logdir work_dirs/hv_pointpillars_secfpn_6x8_160e_kitti-3d-3class

亦可通过安装profiler,在vscode编辑器中可视化训练日志。该工具也可可视化 GPU 和 CPU 之间的工作负载分布。
pip install -U torch-tb-profiler
What’s New in PyTorch Profiler 1.9?
3、训练策略
- 学习率
余弦优化器.
- 动量
- loss
三、评估测试test
0、model_test
points提取特征,分类和回归,获取bbox、score、label。
def simple_test(self, points, img_metas, imgs=None, rescale=False):
"""Test function without augmentaiton."""
x = self.extract_feat(points, img_metas)
outs = self.bbox_head(x)
bbox_list = self.bbox_head.get_bboxes(
*outs, img_metas, rescale=rescale) # nms_bev过滤部分bboxes
bbox_results = [
bbox3d2result(bboxes, scores, labels)
for bboxes, scores, labels in bbox_list
]
return bbox_results

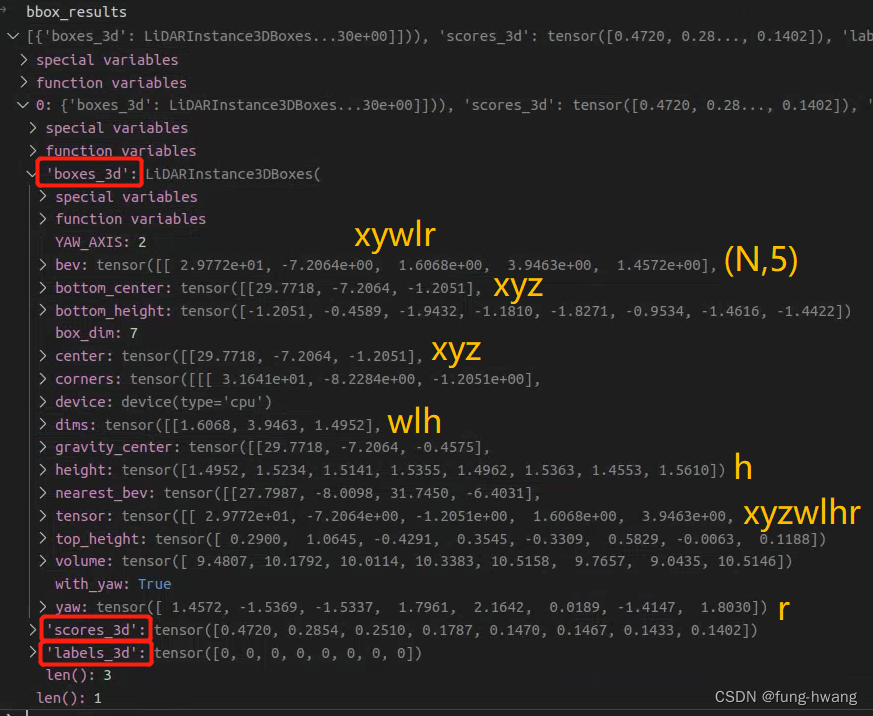
3d_bbox格式为 xyzwlhr。此时3d_bbox为lidar中边界框。
一些后处理操作:
- NMS_BEV:用于计算两个BEV框重叠区域IOU。可以在NMS前后分别指定box的最大大小,默认不指定。nms阈值默认0.01.
结果格式转换:
- lidar_box转camera_box:借助校准数据
R0_rect@Tr2C(组成旋转平移变换矩阵)更新xyz。同时更新角度yaw:
yaw = -yaw - np.pi / 2
yaw = limit_period(yaw, period=np.pi * 2)
camera_box格式为:xyzwhlr。二者数值如下:

- camera_box转corners:主要操作dims(whl)
dims = self.dims
corners_norm = torch.from_numpy(
np.stack(np.unravel_index(np.arange(8), [2] * 3), axis=1)).to(
device=dims.device, dtype=dims.dtype)
corners_norm = corners_norm[[0, 1, 3, 2, 4, 5, 7, 6]]
# use relative origin [0.5, 1, 0.5]
corners_norm = corners_norm - dims.new_tensor([0.5, 1, 0.5])
corners = dims.view([-1, 1, 3]) * corners_norm.reshape([1, 8, 3])
corners = rotation_3d_in_axis(
corners, self.tensor[:, 6], axis=self.YAW_AXIS)
corners += self.tensor[:, :3].view(-1, 1, 3)
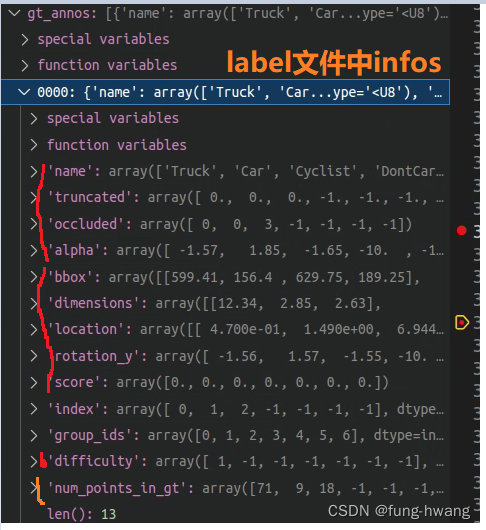
1、gt_annos & predict
每份点云数据真实信息:其中dimensions格式为(l, h, w)。标注文件label中dimensions格式为hwl。这里hwl为常规意义上的高宽长。
每份点云数据预测信息为:由bbox2result_kitti转为kitti格式(相机坐标系)。
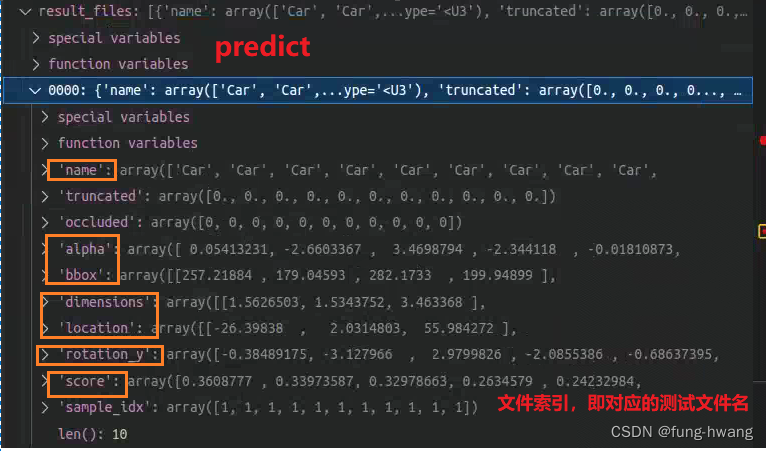
其中dimensions(whl,与GT标注中的lhw对应)、location、rotation_y均从camera_box获取。alpha为-np.arctan2(-box_lidar[1], box_lidar[0]) + box_camera[6]
注:根据定义激光雷达坐标系中dimensions为lwh。相机坐标系中dimensions为lhw。
2、评估
调用kitti_eval函数:
def kitti_eval(gt_annos,
dt_annos,
current_classes,
eval_types=['bbox', 'bev', '3d']):
"""KITTI evaluation.
Args:
gt_annos (list[dict]): Contain gt information of each sample.
dt_annos (list[dict]): Contain detected information of each sample.
current_classes (list[str]): Classes to evaluation.
eval_types (list[str], optional): Types to eval.
Defaults to ['bbox', 'bev', '3d'].
Returns:
tuple: String and dict of evaluation results.
"""
assert len(eval_types) > 0, 'must contain at least one evaluation type'
if 'aos' in eval_types:
assert 'bbox' in eval_types, 'must evaluate bbox when evaluating aos'
overlap_0_7 = np.array([[0.7, 0.5, 0.5, 0.7, 0.5],
[0.7, 0.5, 0.5, 0.7, 0.5],
[0.7, 0.5, 0.5, 0.7, 0.5]]) # 行对应eval_type,列对应类别
overlap_0_5 = np.array([[0.7, 0.5, 0.5, 0.7, 0.5],
[0.5, 0.25, 0.25, 0.5, 0.25],
[0.5, 0.25, 0.25, 0.5, 0.25]]) # 行对应eval_type,列对应类别
min_overlaps = np.stack([overlap_0_7, overlap_0_5], axis=0) # [2, 3, 5]
class_to_name = {
0: 'Car',
1: 'Pedestrian',
2: 'Cyclist',
3: 'Van',
4: 'Person_sitting',
}
name_to_class = {v: n for n, v in class_to_name.items()}
if not isinstance(current_classes, (list, tuple)):
current_classes = [current_classes]
current_classes_int = []
for curcls in current_classes:
if isinstance(curcls, str):
current_classes_int.append(name_to_class[curcls])
else:
current_classes_int.append(curcls)
current_classes = current_classes_int
min_overlaps = min_overlaps[:, :, current_classes]
result = ''
# check whether alpha is valid
compute_aos = False
pred_alpha = False
valid_alpha_gt = False
for anno in dt_annos:
mask = (anno['alpha'] != -10)
if anno['alpha'][mask].shape[0] != 0:
pred_alpha = True
break
for anno in gt_annos:
if anno['alpha'][0] != -10:
valid_alpha_gt = True
break
compute_aos = (pred_alpha and valid_alpha_gt)
if compute_aos:
eval_types.append('aos')
mAP11_bbox, mAP11_bev, mAP11_3d, mAP11_aos, mAP40_bbox, mAP40_bev, \
mAP40_3d, mAP40_aos = do_eval(gt_annos, dt_annos,
current_classes, min_overlaps,
eval_types)
ret_dict = {}
difficulty = ['easy', 'moderate', 'hard']
# calculate AP11
result += '\n----------- AP11 Results ------------\n\n'
for j, curcls in enumerate(current_classes):
# mAP threshold array: [num_minoverlap, metric, class]
# mAP result: [num_class, num_diff, num_minoverlap]
curcls_name = class_to_name[curcls]
for i in range(min_overlaps.shape[0]):
# prepare results for print
result += ('{} AP11@{:.2f}, {:.2f}, {:.2f}:\n'.format(
curcls_name, *min_overlaps[i, :, j]))
if mAP11_bbox is not None:
result += 'bbox AP11:{:.4f}, {:.4f}, {:.4f}\n'.format(
*mAP11_bbox[j, :, i])
if mAP11_bev is not None:
result += 'bev AP11:{:.4f}, {:.4f}, {:.4f}\n'.format(
*mAP11_bev[j, :, i])
if mAP11_3d is not None:
result += '3d AP11:{:.4f}, {:.4f}, {:.4f}\n'.format(
*mAP11_3d[j, :, i])
if compute_aos:
result += 'aos AP11:{:.2f}, {:.2f}, {:.2f}\n'.format(
*mAP11_aos[j, :, i])
# prepare results for logger
for idx in range(3):
if i == 0:
postfix = f'{difficulty[idx]}_strict'
else:
postfix = f'{difficulty[idx]}_loose'
prefix = f'KITTI/{curcls_name}'
if mAP11_3d is not None:
ret_dict[f'{prefix}_3D_AP11_{postfix}'] =\
mAP11_3d[j, idx, i]
if mAP11_bev is not None:
ret_dict[f'{prefix}_BEV_AP11_{postfix}'] =\
mAP11_bev[j, idx, i]
if mAP11_bbox is not None:
ret_dict[f'{prefix}_2D_AP11_{postfix}'] =\
mAP11_bbox[j, idx, i]
# calculate mAP11 over all classes if there are multiple classes
if len(current_classes) > 1:
# prepare results for print
result += ('\nOverall AP11@{}, {}, {}:\n'.format(*difficulty))
if mAP11_bbox is not None:
mAP11_bbox = mAP11_bbox.mean(axis=0)
result += 'bbox AP11:{:.4f}, {:.4f}, {:.4f}\n'.format(
*mAP11_bbox[:, 0])
if mAP11_bev is not None:
mAP11_bev = mAP11_bev.mean(axis=0)
result += 'bev AP11:{:.4f}, {:.4f}, {:.4f}\n'.format(
*mAP11_bev[:, 0])
if mAP11_3d is not None:
mAP11_3d = mAP11_3d.mean(axis=0)
result += '3d AP11:{:.4f}, {:.4f}, {:.4f}\n'.format(*mAP11_3d[:,
0])
if compute_aos:
mAP11_aos = mAP11_aos.mean(axis=0)
result += 'aos AP11:{:.2f}, {:.2f}, {:.2f}\n'.format(
*mAP11_aos[:, 0])
# prepare results for logger
for idx in range(3):
postfix = f'{difficulty[idx]}'
if mAP11_3d is not None:
ret_dict[f'KITTI/Overall_3D_AP11_{postfix}'] = mAP11_3d[idx, 0]
if mAP11_bev is not None:
ret_dict[f'KITTI/Overall_BEV_AP11_{postfix}'] =\
mAP11_bev[idx, 0]
if mAP11_bbox is not None:
ret_dict[f'KITTI/Overall_2D_AP11_{postfix}'] =\
mAP11_bbox[idx, 0]
# Calculate AP40
result += '\n----------- AP40 Results ------------\n\n'
for j, curcls in enumerate(current_classes):
# mAP threshold array: [num_minoverlap, metric, class]
# mAP result: [num_class, num_diff, num_minoverlap]
curcls_name = class_to_name[curcls]
for i in range(min_overlaps.shape[0]):
# prepare results for print
result += ('{} AP40@{:.2f}, {:.2f}, {:.2f}:\n'.format(
curcls_name, *min_overlaps[i, :, j]))
if mAP40_bbox is not None:
result += 'bbox AP40:{:.4f}, {:.4f}, {:.4f}\n'.format(
*mAP40_bbox[j, :, i])
if mAP40_bev is not None:
result += 'bev AP40:{:.4f}, {:.4f}, {:.4f}\n'.format(
*mAP40_bev[j, :, i])
if mAP40_3d is not None:
result += '3d AP40:{:.4f}, {:.4f}, {:.4f}\n'.format(
*mAP40_3d[j, :, i])
if compute_aos:
result += 'aos AP40:{:.2f}, {:.2f}, {:.2f}\n'.format(
*mAP40_aos[j, :, i])
# prepare results for logger
for idx in range(3):
if i == 0:
postfix = f'{difficulty[idx]}_strict'
else:
postfix = f'{difficulty[idx]}_loose'
prefix = f'KITTI/{curcls_name}'
if mAP40_3d is not None:
ret_dict[f'{prefix}_3D_AP40_{postfix}'] =\
mAP40_3d[j, idx, i]
if mAP40_bev is not None:
ret_dict[f'{prefix}_BEV_AP40_{postfix}'] =\
mAP40_bev[j, idx, i]
if mAP40_bbox is not None:
ret_dict[f'{prefix}_2D_AP40_{postfix}'] =\
mAP40_bbox[j, idx, i]
# calculate mAP40 over all classes if there are multiple classes
if len(current_classes) > 1:
# prepare results for print
result += ('\nOverall AP40@{}, {}, {}:\n'.format(*difficulty))
if mAP40_bbox is not None:
mAP40_bbox = mAP40_bbox.mean(axis=0)
result += 'bbox AP40:{:.4f}, {:.4f}, {:.4f}\n'.format(
*mAP40_bbox[:, 0])
if mAP40_bev is not None:
mAP40_bev = mAP40_bev.mean(axis=0)
result += 'bev AP40:{:.4f}, {:.4f}, {:.4f}\n'.format(
*mAP40_bev[:, 0])
if mAP40_3d is not None:
mAP40_3d = mAP40_3d.mean(axis=0)
result += '3d AP40:{:.4f}, {:.4f}, {:.4f}\n'.format(*mAP40_3d[:,
0])
if compute_aos:
mAP40_aos = mAP40_aos.mean(axis=0)
result += 'aos AP40:{:.2f}, {:.2f}, {:.2f}\n'.format(
*mAP40_aos[:, 0])
# prepare results for logger
for idx in range(3):
postfix = f'{difficulty[idx]}'
if mAP40_3d is not None:
ret_dict[f'KITTI/Overall_3D_AP40_{postfix}'] = mAP40_3d[idx, 0]
if mAP40_bev is not None:
ret_dict[f'KITTI/Overall_BEV_AP40_{postfix}'] =\
mAP40_bev[idx, 0]
if mAP40_bbox is not None:
ret_dict[f'KITTI/Overall_2D_AP40_{postfix}'] =\
mAP40_bbox[idx, 0]
return result, ret_dict
参考资料
- https://github.com/open-mmlab/mmdetection3d
- https://mmdetection3d.readthedocs.io/en/latest/getting_started.html#installation
- https://docs.docker.com/config/containers/resource_constraints/#gpu
- http://www.open3d.org/docs/release/docker.html

















 4337
4337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









