







原文:https://docs.voxel51.com/tutorials/open_images.html
教程涵盖以下内容:
- 如何从fiftyone 数据库下载公开数据集;
- 如何使用fiftyone模型库进行预测,模型推理;
- 如何用fiftyone 进行数据集评估,模型计算输出mAP;
- 探索数据集和评估结果;
- 通过交互式绘图工具可视化嵌入特征。
准备工作
- 安装fiftyone
pip install fiftyone
- 我们会用一些 TensorFlow 模型和 PyTorch 来生成预测和嵌入,也会用 UMAP 方法(一种数据降维方法)来降低嵌入的维度,所以我们需要安装相应的包:
pip install tensorflow torch torchvision umap-learn
- 安装Jupyter notebooks里交互式绘图工具
pip install 'ipywidgets>=8,<9'
1、加载数据集
官网为例,下载 100 个随机选择的图像 + 标注的小样本:
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset(
"open-images-v7",
split="validation",
max_samples=100,
seed=51,
shuffle=True,)
现在让我们启动 FiftyOne 应用程序,以便我们可以探索刚刚下载的数据集。
session = fo.launch_app(dataset.view())
执行结果:
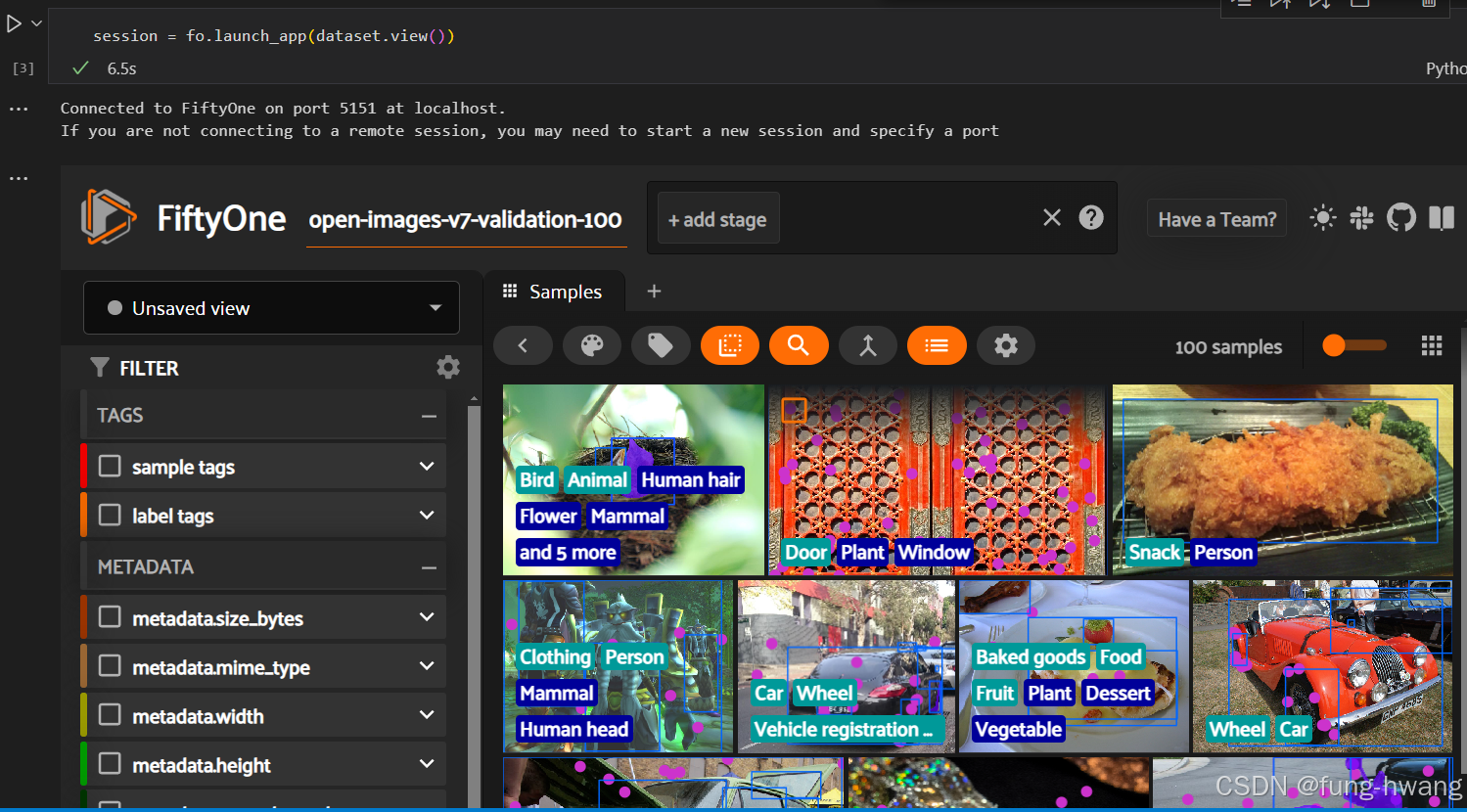 注:fiftyone连接到本地端口5151。如果未连接到远程会话,则可能需要启动新会话并指定端口。
注:fiftyone连接到本地端口5151。如果未连接到远程会话,则可能需要启动新会话并指定端口。
session = fo.launch_app(dataset.view(), port=5150)
# 如果在网页中看不到我们要的效果,等待应用程序加载完成.
session.wait()
同时,我们可以加载其他常见几种格式,如voc,yolo格式的数据集,或者纯图像数据集:
# 1、加载纯图像
dataset = fo.Dataset.from_dir(
dataset_type=fo.types.ImageDirectory,
dataset_dir="G:\\lf\Anti-UAV-RGBT\\train_data_mosaic_mixup",
name="anti_aug_train",
shuffle=False,)
# 2、加载yolo格式
dataset = fo.Dataset.from_dir(
dataset_type=fo.types.YOLOv5Dataset,
yaml_path = "H:\\lf\\Anti-UAV-RGBT\\anti.yaml", # 数据根目录、train/val txt、类别(即为yolov5训练格式yaml)
name ="anti",
shuffle=True,)
# 3、加载voc格式
dataset = fo.Dataset.from_dir(
data_path='H:/lf/anti/voc/train/images', # 末尾不能加 /
labels_path='H:/lf/antin/voc/train/labels', # 末尾不能加 /
dataset_type=fo.types.VOCDetectionDataset,
label_field='ground_truth',
shuffle=True,)
使用 FiftyOne 加载 Open Images 还会自动存储相关的标签和元数据,例如类、属性和用于在数据集的 info 字典中评估的类层次结构。输出相应字典信息:
print(dataset.info.keys())
返回:dict_keys([‘hierarchy’, ‘attributes_map’, ‘attributes’, ‘segmentation_classes’, ‘point_classes’, ‘classes_map’])。
加载数据集可以将各种可用参数传递给 load_zoo_dataset() 以指定要下载的图像或标签类型的子集:
label_types- 加载的标签类型列表。Open Images V7 支持的值为(“detections”, “classifications”, “points”, “segmentations”, “relationships”)。Open Images v6 与此相同,只是它不包含 “points”。默认情况下,将加载所有可用的标签类型。指定[]将仅加载图像。classes- 感兴趣的类的列表。如果指定,则仅下载指定类中至少具有一个object、segmentation或image-level label的样本。attrs- 感兴趣的属性列表。如果指定,则仅当样本在attrs中至少包含一个属性或在classes中包含一个类时才下载样本(仅当label_types包含 “relationships” 时适用)。load_hierarchy- 是否将类层次结构加载到dataset.info[“hierarchy”]中。image_ids- 要下载的特定图像 ID 数组。image_ids_file- 包含要下载图像 ID 的 .txt、.csv 或 .json 文件的路径。max_samples- 要加载的最大样本数。shuffle- 如果给出了max_samples,是否随机选择要加载的样本。seed- 随机排序时使用的随机种子。
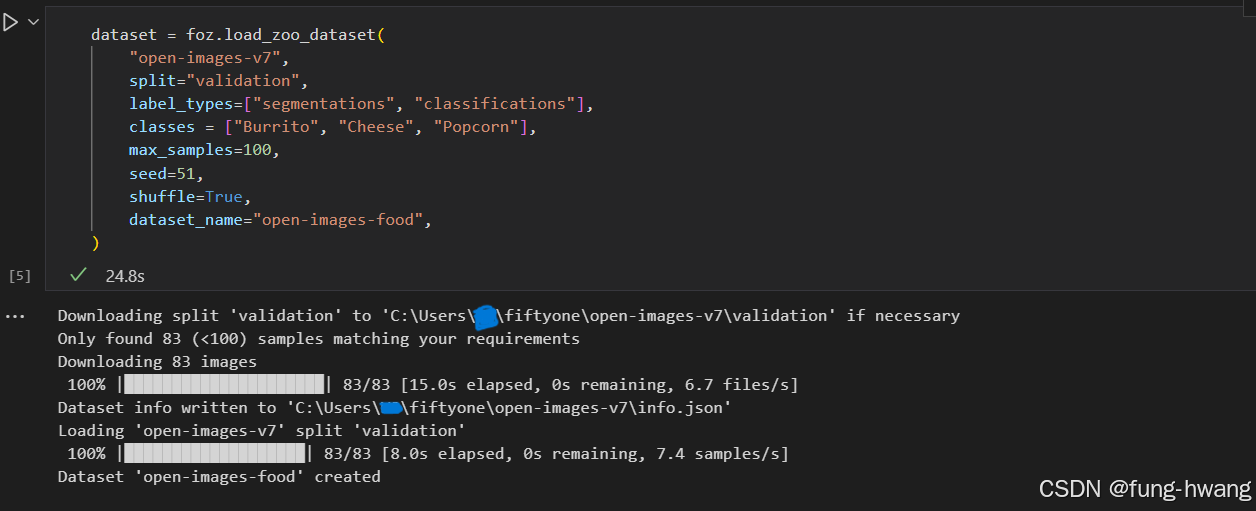
接下来,我们使用其中一些参数来下载 Open Images 的 100 个示例子集,其中包含类“Burrito”、“Cheese”和“Popcorn”的segmentations和image-level labels。
dataset = foz.load_zoo_dataset(
"open-images-v7",
split="validation",
label_types=["segmentations", "classifications"],
classes = ["Burrito", "Cheese", "Popcorn"],
max_samples=100,
seed=51,
shuffle=True,
dataset_name="open-images-food",)
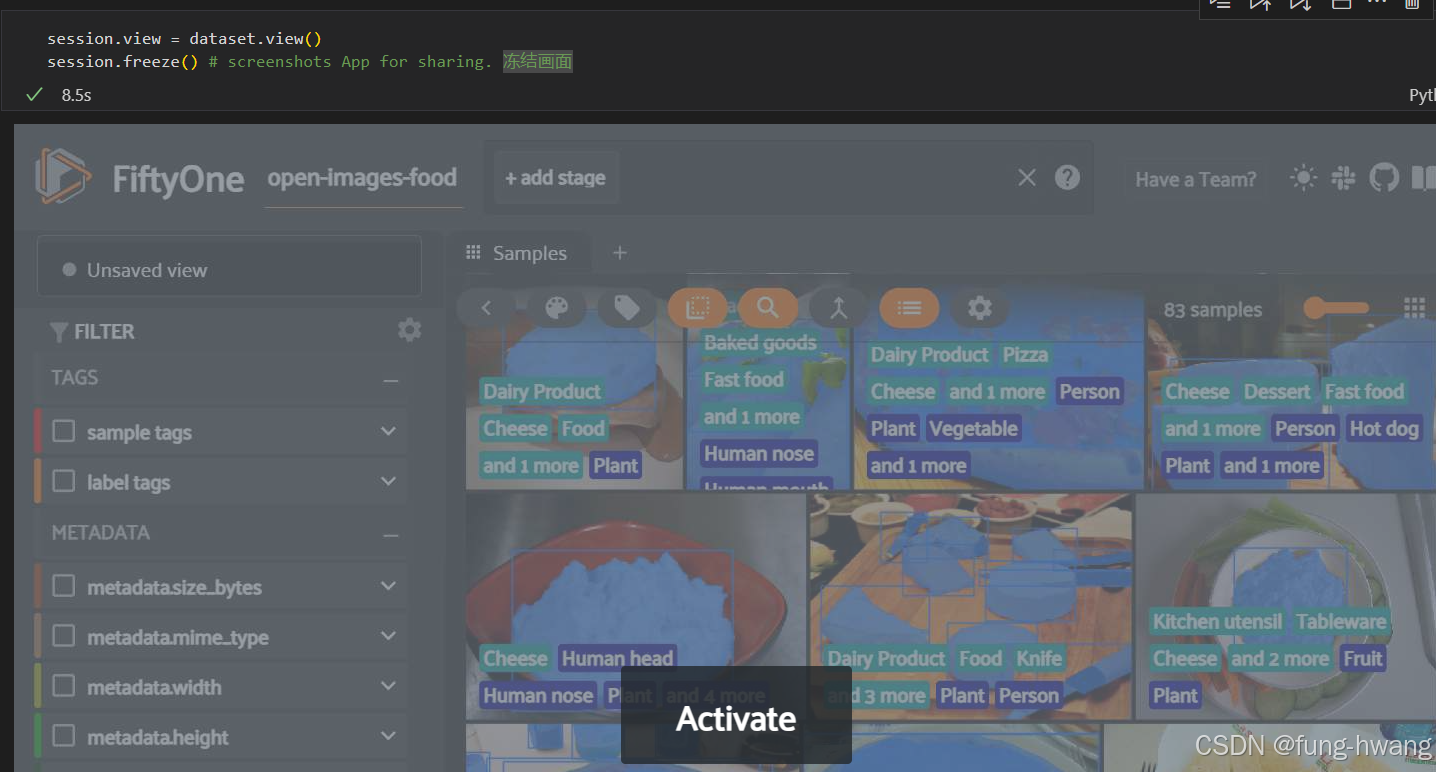
执行结果图:
例如,我们只下载包含与 “Wooden” 属性有关系的示例:
dataset = foz.load_zoo_dataset(
"open-images-v7",
split="validation",
label_types=["relationships"],
attrs 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5687
5687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









